 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAKVQ-VL: Attention-Aware KV Cache Adaptive 2-Bit Quantization for Vision-Language Models
Jan 25, 2025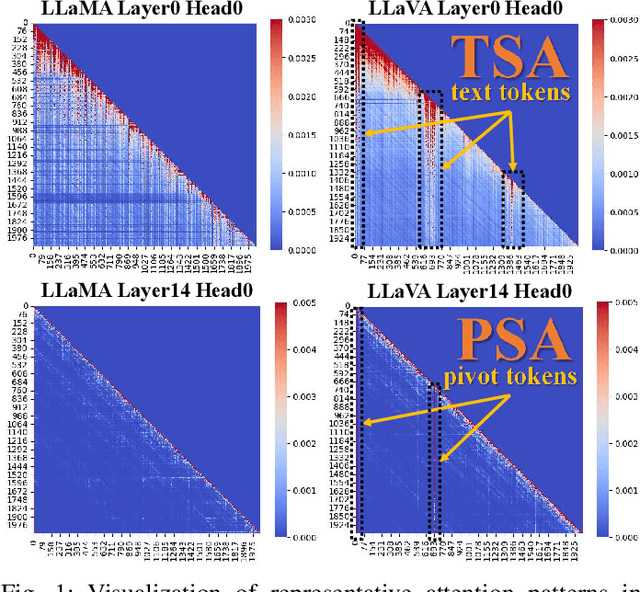
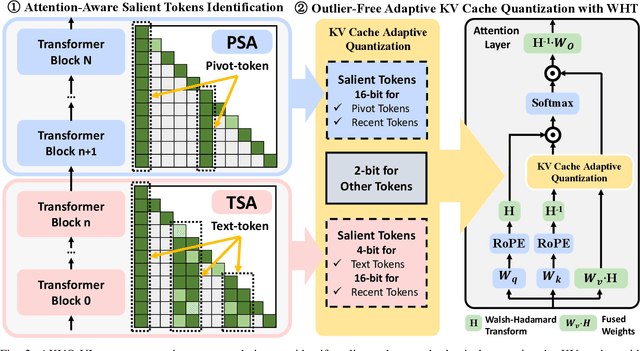
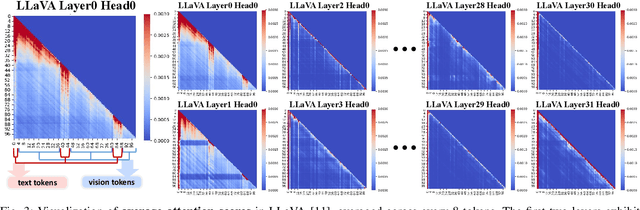
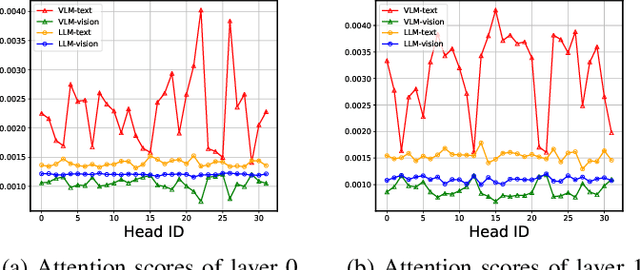
Vision-language models (VLMs) show remarkable performance in multimodal tasks. However, excessively long multimodal inputs lead to oversized Key-Value (KV) caches, resulting in significant memory consumption and I/O bottlenecks. Previous KV quantization methods for Large Language Models (LLMs) may alleviate these issues but overlook the attention saliency differences of multimodal tokens, resulting in suboptimal performance. In this paper, we investigate the attention-aware token saliency patterns in VLM and propose AKVQ-VL. AKVQ-VL leverages the proposed Text-Salient Attention (TSA) and Pivot-Token-Salient Attention (PSA) patterns to adaptively allocate bit budgets. Moreover, achieving extremely low-bit quantization requires effectively addressing outliers in KV tensors. AKVQ-VL utilizes the Walsh-Hadamard transform (WHT) to construct outlier-free KV caches, thereby reducing quantization difficulty. Evaluations of 2-bit quantization on 12 long-context and multimodal tasks demonstrate that AKVQ-VL maintains or even improves accuracy, outperforming LLM-oriented methods. AKVQ-VL can reduce peak memory usage by 2.13x, support up to 3.25x larger batch sizes and 2.46x throughput.
H2-Stereo: High-Speed, High-Resolution Stereoscopic Video System
Aug 04, 2022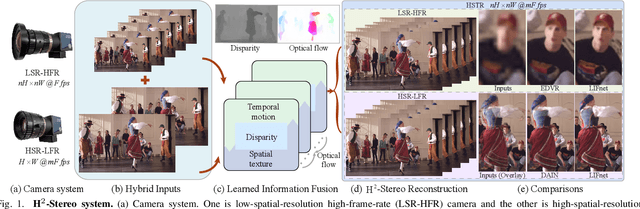



High-speed, high-resolution stereoscopic (H2-Stereo) video allows us to perceive dynamic 3D content at fine granularity. The acquisition of H2-Stereo video, however, remains challenging with commodity cameras. Existing spatial super-resolution or temporal frame interpolation methods provide compromised solutions that lack temporal or spatial details, respectively. To alleviate this problem, we propose a dual camera system, in which one camera captures high-spatial-resolution low-frame-rate (HSR-LFR) videos with rich spatial details, and the other captures low-spatial-resolution high-frame-rate (LSR-HFR) videos with smooth temporal details. We then devise a Learned Information Fusion network (LIFnet) that exploits the cross-camera redundancies to enhance both camera views to high spatiotemporal resolution (HSTR) for reconstructing the H2-Stereo video effectively. We utilize a disparity network to transfer spatiotemporal information across views even in large disparity scenes, based on which, we propose disparity-guided flow-based warping for LSR-HFR view and complementary warping for HSR-LFR view. A multi-scale fusion method in feature domain is proposed to minimize occlusion-induced warping ghosts and holes in HSR-LFR view. The LIFnet is trained in an end-to-end manner using our collected high-quality Stereo Video dataset from YouTube. Extensive experiments demonstrate that our model outperforms existing state-of-the-art methods for both views on synthetic data and camera-captured real data with large disparity. Ablation studies explore various aspects, including spatiotemporal resolution, camera baseline, camera desynchronization, long/short exposures and applications, of our system to fully understand its capability for potential applications.
Enhanced Deep Animation Video Interpolation
Jun 25, 2022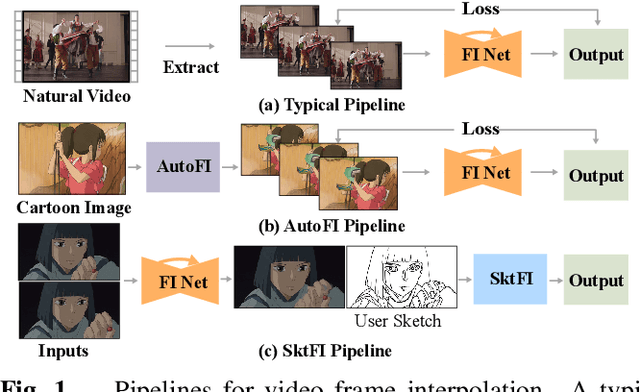

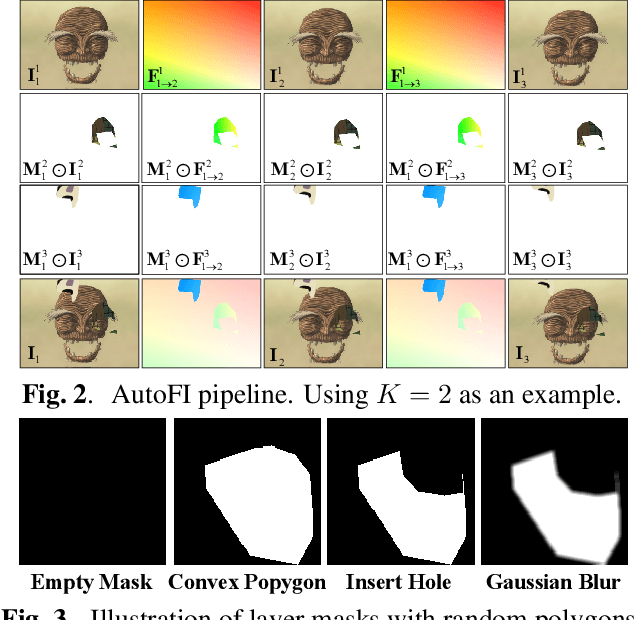
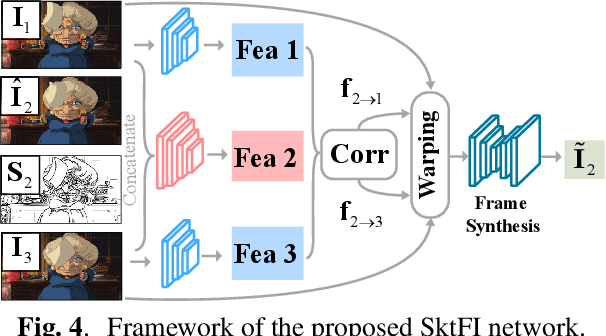
Existing learning-based frame interpolation algorithms extract consecutive frames from high-speed natural videos to train the model. Compared to natural videos, cartoon videos are usually in a low frame rate. Besides, the motion between consecutive cartoon frames is typically nonlinear, which breaks the linear motion assumption of interpolation algorithms. Thus, it is unsuitable for generating a training set directly from cartoon videos. For better adapting frame interpolation algorithms from nature video to animation video, we present AutoFI, a simple and effective method to automatically render training data for deep animation video interpolation. AutoFI takes a layered architecture to render synthetic data, which ensures the assumption of linear motion. Experimental results show that AutoFI performs favorably in training both DAIN and ANIN. However, most frame interpolation algorithms will still fail in error-prone areas, such as fast motion or large occlusion. Besides AutoFI, we also propose a plug-and-play sketch-based post-processing module, named SktFI, to refine the final results using user-provided sketches manually. With AutoFI and SktFI, the interpolated animation frames show high perceptual quality.
Frequency-Aware Physics-Inspired Degradation Model for Real-World Image Super-Resolution
Nov 05, 2021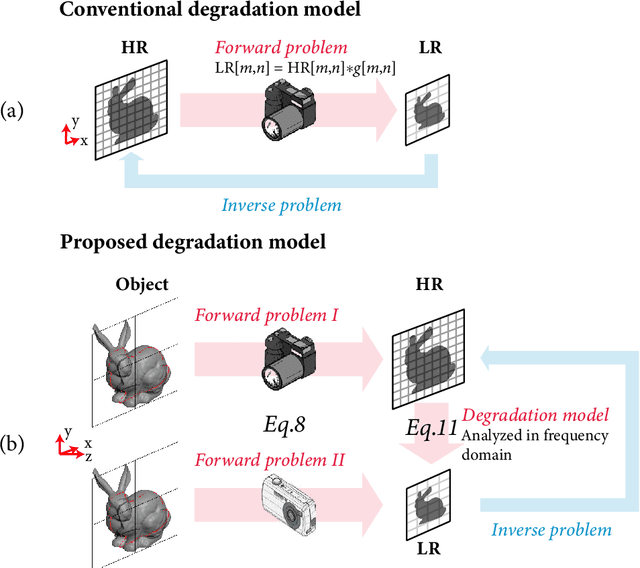

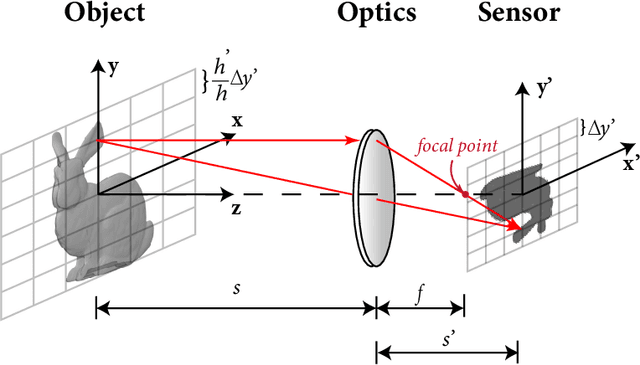
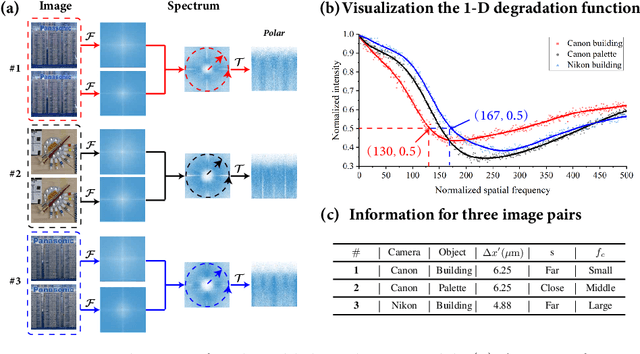
Current learning-based single image super-resolution (SISR) algorithms underperform on real data due to the deviation in the assumed degrada-tion process from that in the real-world scenario. Conventional degradation processes consider applying blur, noise, and downsampling (typicallybicubic downsampling) on high-resolution (HR) images to synthesize low-resolution (LR) counterparts. However, few works on degradation modelling have taken the physical aspects of the optical imaging system intoconsideration. In this paper, we analyze the imaging system optically andexploit the characteristics of the real-world LR-HR pairs in the spatial frequency domain. We formulate a real-world physics-inspired degradationmodel by considering bothopticsandsensordegradation; The physical degradation of an imaging system is modelled as a low-pass filter, whose cut-off frequency is dictated by the object distance, the focal length of thelens, and the pixel size of the image sensor. In particular, we propose to use a convolutional neural network (CNN) to learn the cutoff frequency of real-world degradation process. The learned network is then applied to synthesize LR images from unpaired HR images. The synthetic HR-LR image pairs are later used to train an SISR network. We evaluatethe effectiveness and generalization capability of the proposed degradation model on real-world images captured by different imaging systems. Experimental results showcase that the SISR network trained by using our synthetic data performs favorably against the network using the traditional degradation model. Moreover, our results are comparable to that obtained by the same network trained by using real-world LR-HR pairs, which are challenging to obtain in real scenes.
Prediction-assistant Frame Super-Resolution for Video Streaming
Mar 17, 2021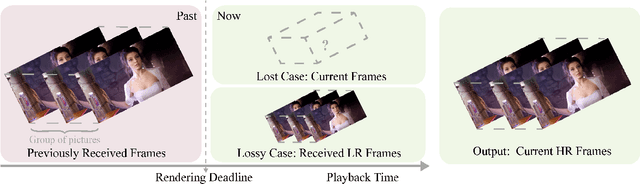
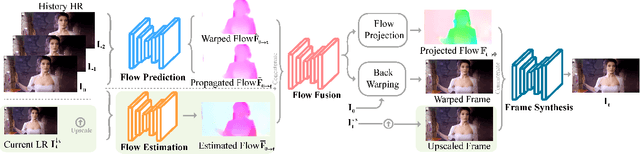
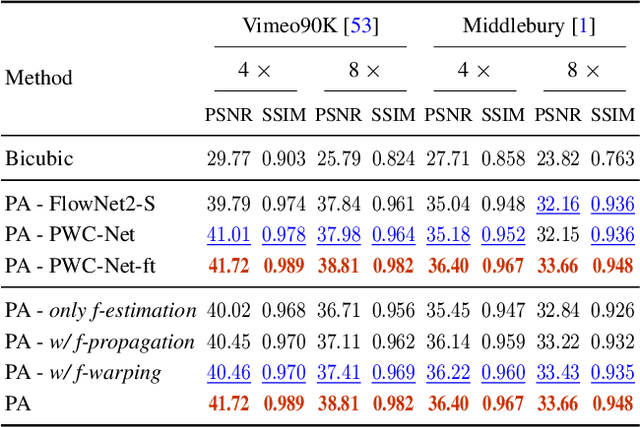

Video frame transmission delay is critical in real-time applications such as online video gaming, live show, etc. The receiving deadline of a new frame must catch up with the frame rendering time. Otherwise, the system will buffer a while, and the user will encounter a frozen screen, resulting in unsatisfactory user experiences. An effective approach is to transmit frames in lower-quality under poor bandwidth conditions, such as using scalable video coding. In this paper, we propose to enhance video quality using lossy frames in two situations. First, when current frames are too late to receive before rendering deadline (i.e., lost), we propose to use previously received high-resolution images to predict the future frames. Second, when the quality of the currently received frames is low~(i.e., lossy), we propose to use previously received high-resolution frames to enhance the low-quality current ones. For the first case, we propose a small yet effective video frame prediction network. For the second case, we improve the video prediction network to a video enhancement network to associate current frames as well as previous frames to restore high-quality images. Extensive experimental results demonstrate that our method performs favorably against state-of-the-art algorithms in the lossy video streaming environment.
Blurry Video Frame Interpolation
Feb 27, 2020
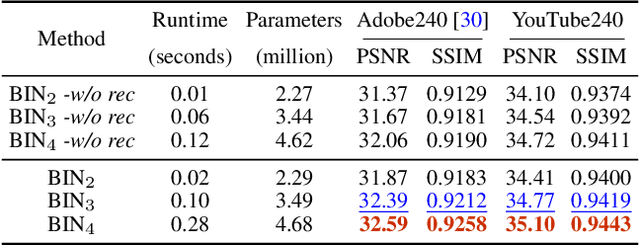
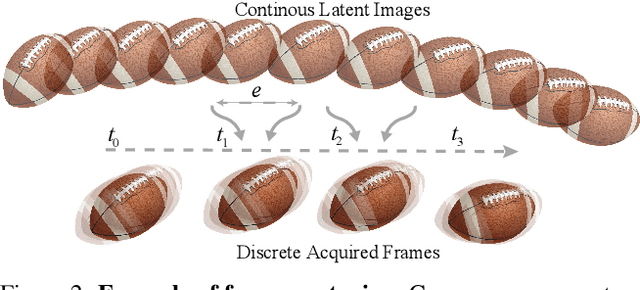
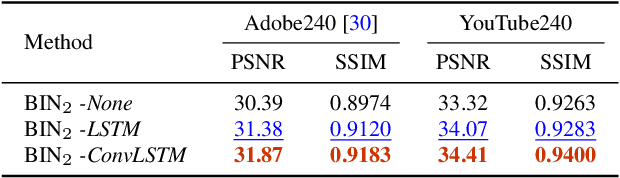
Existing works reduce motion blur and up-convert frame rate through two separate ways, including frame deblurring and frame interpolation. However, few studies have approached the joint video enhancement problem, namely synthesizing high-frame-rate clear results from low-frame-rate blurry inputs. In this paper, we propose a blurry video frame interpolation method to reduce motion blur and up-convert frame rate simultaneously. Specifically, we develop a pyramid module to cyclically synthesize clear intermediate frames. The pyramid module features adjustable spatial receptive field and temporal scope, thus contributing to controllable computational complexity and restoration ability. Besides, we propose an inter-pyramid recurrent module to connect sequential models to exploit the temporal relationship. The pyramid module integrates a recurrent module, thus can iteratively synthesize temporally smooth results without significantly increasing the model size. Extensive experimental results demonstrate that our method performs favorably against state-of-the-art methods.