 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeH2-Stereo: High-Speed, High-Resolution Stereoscopic Video System
Paper and Code
Aug 04, 2022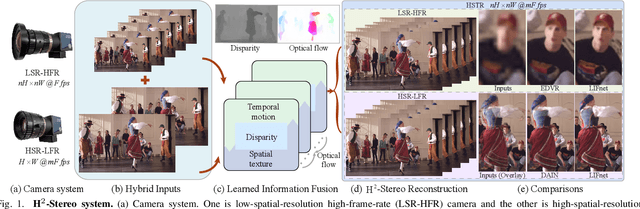



High-speed, high-resolution stereoscopic (H2-Stereo) video allows us to perceive dynamic 3D content at fine granularity. The acquisition of H2-Stereo video, however, remains challenging with commodity cameras. Existing spatial super-resolution or temporal frame interpolation methods provide compromised solutions that lack temporal or spatial details, respectively. To alleviate this problem, we propose a dual camera system, in which one camera captures high-spatial-resolution low-frame-rate (HSR-LFR) videos with rich spatial details, and the other captures low-spatial-resolution high-frame-rate (LSR-HFR) videos with smooth temporal details. We then devise a Learned Information Fusion network (LIFnet) that exploits the cross-camera redundancies to enhance both camera views to high spatiotemporal resolution (HSTR) for reconstructing the H2-Stereo video effectively. We utilize a disparity network to transfer spatiotemporal information across views even in large disparity scenes, based on which, we propose disparity-guided flow-based warping for LSR-HFR view and complementary warping for HSR-LFR view. A multi-scale fusion method in feature domain is proposed to minimize occlusion-induced warping ghosts and holes in HSR-LFR view. The LIFnet is trained in an end-to-end manner using our collected high-quality Stereo Video dataset from YouTube. Extensive experiments demonstrate that our model outperforms existing state-of-the-art methods for both views on synthetic data and camera-captured real data with large disparity. Ablation studies explore various aspects, including spatiotemporal resolution, camera baseline, camera desynchronization, long/short exposures and applications, of our system to fully understand its capability for potential applications.