 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscovering Sparse Recovery Algorithms Using Neural Architecture Search
Dec 25, 2025The design of novel algorithms for solving inverse problems in signal processing is an incredibly difficult, heuristic-driven, and time-consuming task. In this short paper, we the idea of automated algorithm discovery in the signal processing context through meta-learning tools such as Neural Architecture Search (NAS). Specifically, we examine the Iterative Shrinkage Thresholding Algorithm (ISTA) and its accelerated Fast ISTA (FISTA) variant as candidates for algorithm rediscovery. We develop a meta-learning framework which is capable of rediscovering (several key elements of) the two aforementioned algorithms when given a search space of over 50,000 variables. We then show how our framework can apply to various data distributions and algorithms besides ISTA/FISTA.
EigenScore: OOD Detection using Covariance in Diffusion Models
Oct 08, 2025


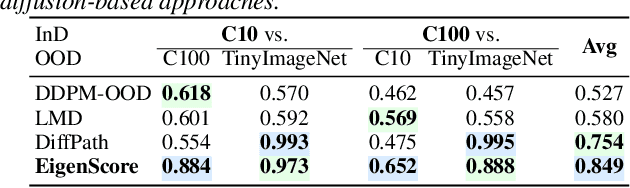
Out-of-distribution (OOD) detection is critical for the safe deployment of machine learning systems in safety-sensitive domains. Diffusion models have recently emerged as powerful generative models, capable of capturing complex data distributions through iterative denoising. Building on this progress, recent work has explored their potential for OOD detection. We propose EigenScore, a new OOD detection method that leverages the eigenvalue spectrum of the posterior covariance induced by a diffusion model. We argue that posterior covariance provides a consistent signal of distribution shift, leading to larger trace and leading eigenvalues on OOD inputs, yielding a clear spectral signature. We further provide analysis explicitly linking posterior covariance to distribution mismatch, establishing it as a reliable signal for OOD detection. To ensure tractability, we adopt a Jacobian-free subspace iteration method to estimate the leading eigenvalues using only forward evaluations of the denoiser. Empirically, EigenScore achieves SOTA performance, with up to 5% AUROC improvement over the best baseline. Notably, it remains robust in near-OOD settings such as CIFAR-10 vs CIFAR-100, where existing diffusion-based methods often fail.
Unsupervised Detection of Distribution Shift in Inverse Problems using Diffusion Models
May 16, 2025Diffusion models are widely used as priors in imaging inverse problems. However, their performance often degrades under distribution shifts between the training and test-time images. Existing methods for identifying and quantifying distribution shifts typically require access to clean test images, which are almost never available while solving inverse problems (at test time). We propose a fully unsupervised metric for estimating distribution shifts using only indirect (corrupted) measurements and score functions from diffusion models trained on different datasets. We theoretically show that this metric estimates the KL divergence between the training and test image distributions. Empirically, we show that our score-based metric, using only corrupted measurements, closely approximates the KL divergence computed from clean images. Motivated by this result, we show that aligning the out-of-distribution score with the in-distribution score -- using only corrupted measurements -- reduces the KL divergence and leads to improved reconstruction quality across multiple inverse problems.
RENO: Real-Time Neural Compression for 3D LiDAR Point Clouds
Mar 16, 2025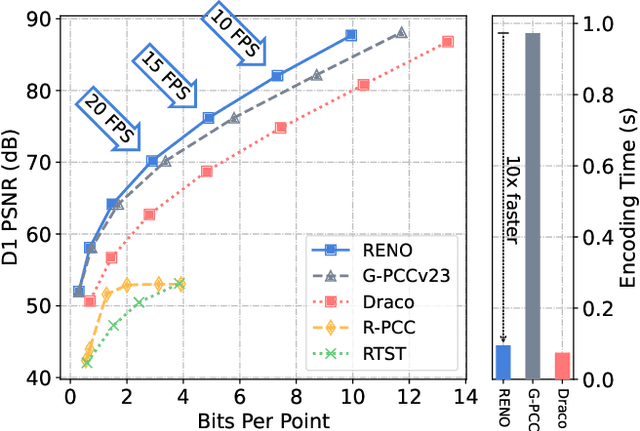
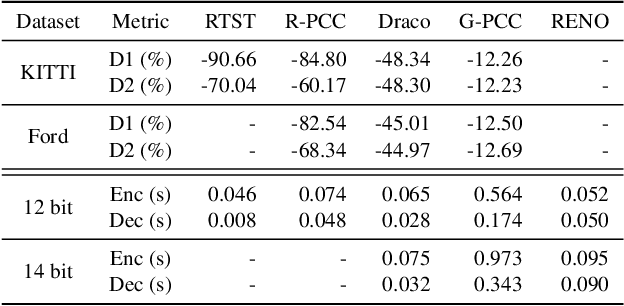
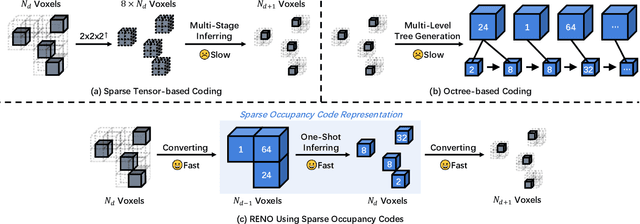
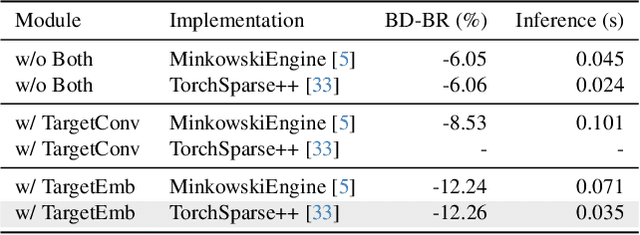
Despite the substantial advancements demonstrated by learning-based neural models in the LiDAR Point Cloud Compression (LPCC) task, realizing real-time compression - an indispensable criterion for numerous industrial applications - remains a formidable challenge. This paper proposes RENO, the first real-time neural codec for 3D LiDAR point clouds, achieving superior performance with a lightweight model. RENO skips the octree construction and directly builds upon the multiscale sparse tensor representation. Instead of the multi-stage inferring, RENO devises sparse occupancy codes, which exploit cross-scale correlation and derive voxels' occupancy in a one-shot manner, greatly saving processing time. Experimental results demonstrate that the proposed RENO achieves real-time coding speed, 10 fps at 14-bit depth on a desktop platform (e.g., one RTX 3090 GPU) for both encoding and decoding processes, while providing 12.25% and 48.34% bit-rate savings compared to G-PCCv23 and Draco, respectively, at a similar quality. RENO model size is merely 1MB, making it attractive for practical applications. The source code is available at https://github.com/NJUVISION/RENO.
U2A: Unified Unimodal Adaptation for Robust and Efficient Multimodal Learning
Jan 29, 2025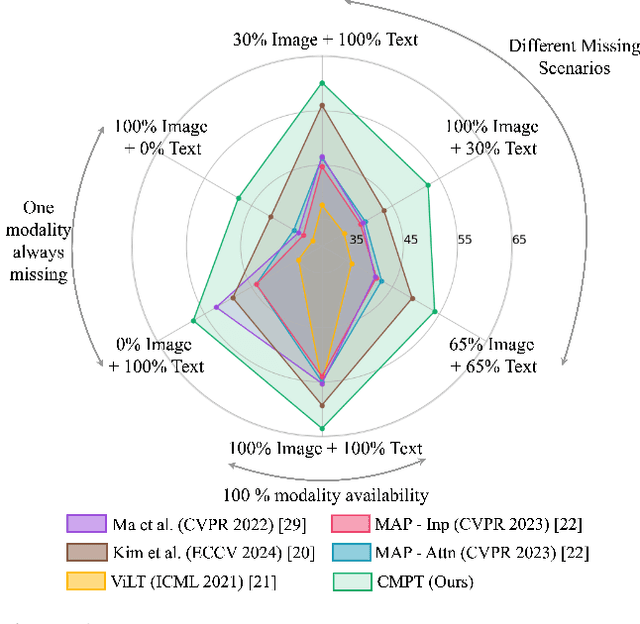
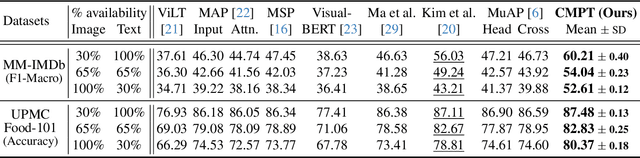
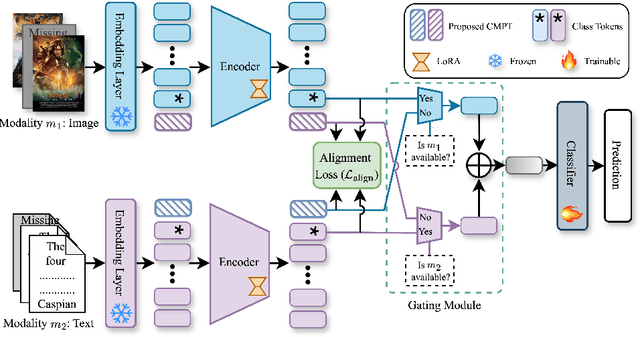
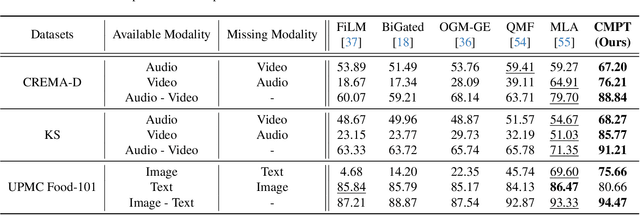
Multimodal learning often relies on designing new models and complex training strategies to achieve optimal performance. We present Unified Unimodal Adaptation (U2A), which jointly fine-tunes pretrained unimodal encoders using low-rank adaptation (LoRA) for various multimodal tasks. Our method significantly reduces the number of learnable parameters and eliminates the need for complex training strategies, such as alternating training, gradient modifications, or unimodal fine-tuning. To address missing modalities during both training and testing, we introduce Mask Tokens (MT), which generate missing modality features from available modalities using a single token per modality. This simplifies the process, removing the need for specialized feature estimation or prompt-tuning methods. Our evaluation demonstrates that U2A matches or outperforms state-of-the-art methods in both complete and missing modality settings, showcasing strong performance and robustness across various modalities, tasks, and datasets. We also analyze and report the effectiveness of Mask Tokens in different missing modality scenarios. Overall, our method provides a robust, flexible, and efficient solution for multimodal learning, with minimal computational overhead.
MMP: Towards Robust Multi-Modal Learning with Masked Modality Projection
Oct 03, 2024



Multimodal learning seeks to combine data from multiple input sources to enhance the performance of different downstream tasks. In real-world scenarios, performance can degrade substantially if some input modalities are missing. Existing methods that can handle missing modalities involve custom training or adaptation steps for each input modality combination. These approaches are either tied to specific modalities or become computationally expensive as the number of input modalities increases. In this paper, we propose Masked Modality Projection (MMP), a method designed to train a single model that is robust to any missing modality scenario. We achieve this by randomly masking a subset of modalities during training and learning to project available input modalities to estimate the tokens for the masked modalities. This approach enables the model to effectively learn to leverage the information from the available modalities to compensate for the missing ones, enhancing missing modality robustness. We conduct a series of experiments with various baseline models and datasets to assess the effectiveness of this strategy. Experiments demonstrate that our approach improves robustness to different missing modality scenarios, outperforming existing methods designed for missing modalities or specific modality combinations.
Gaussian is All You Need: A Unified Framework for Solving Inverse Problems via Diffusion Posterior Sampling
Sep 13, 2024



Diffusion models can generate a variety of high-quality images by modeling complex data distributions. Trained diffusion models can also be very effective image priors for solving inverse problems. Most of the existing diffusion-based methods integrate data consistency steps within the diffusion reverse sampling process. The data consistency steps rely on an approximate likelihood function. In this paper, we show that the existing approximations are either insufficient or computationally inefficient. To address these issues, we propose a unified likelihood approximation method that incorporates a covariance correction term to enhance the performance and avoids propagating gradients through the diffusion model. The correction term, when integrated into the reverse diffusion sampling process, achieves better convergence towards the true data posterior for selected distributions and improves performance on real-world natural image datasets. Furthermore, we present an efficient way to factorize and invert the covariance matrix of the likelihood function for several inverse problems. We present comprehensive experiments to demonstrate the effectiveness of our method over several existing approaches.
Single Layer Single Gradient Unlearning
Jul 16, 2024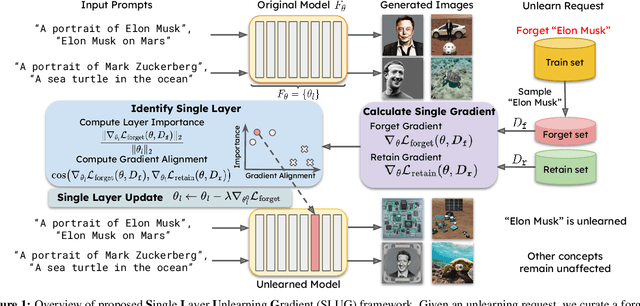
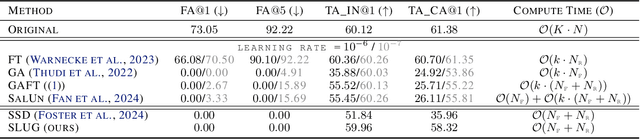
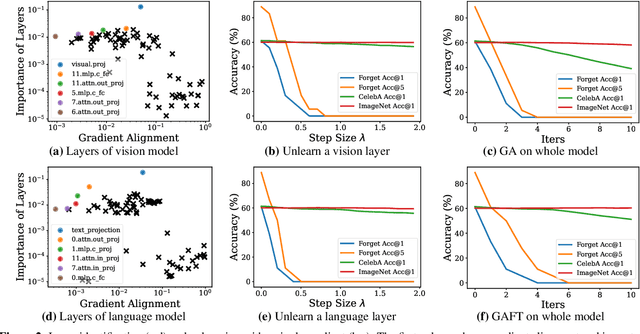
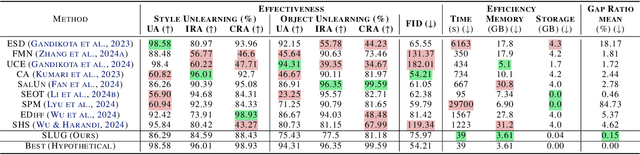
Machine unlearning methods seek to revise pretrained models such that effects of certain training samples can be removed. In addition to effective erasure, low computational cost and general utility retention are also highly desirable. Existing unlearning methods usually involve iterative updates over the model parameters, which incurs a high computational cost. In this work, we propose an efficient method that only requires a one-time gradient computation, with which we modify only a single layer of model parameters. Specifically, we first identify a small number of model layers that lie on the Pareto front of high forget importance and low retain influence as critical layers. Then we search for a suitable step size and take a step along the gradient direction of a single critical layer while keeping other layers frozen. This method is highly modular and can be used to unlearn multiple concepts simultaneously in a controllable manner. We demonstrate the effectiveness and efficiency of this method on various models including CLIP, stable diffusion, and VLMs, surpassing other state-of-the-art methods.
Transformation-Dependent Adversarial Attacks
Jun 12, 2024
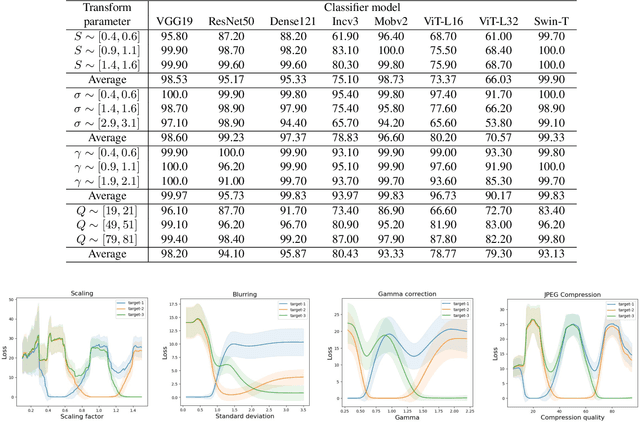
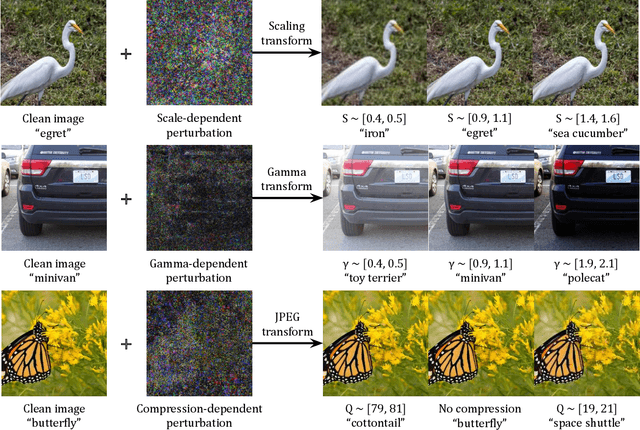
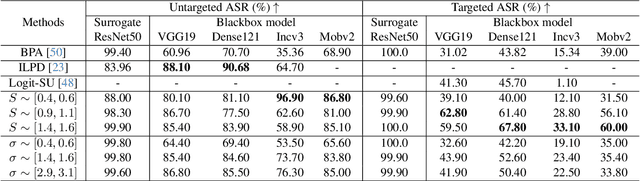
We introduce transformation-dependent adversarial attacks, a new class of threats where a single additive perturbation can trigger diverse, controllable mis-predictions by systematically transforming the input (e.g., scaling, blurring, compression). Unlike traditional attacks with static effects, our perturbations embed metamorphic properties to enable different adversarial attacks as a function of the transformation parameters. We demonstrate the transformation-dependent vulnerability across models (e.g., convolutional networks and vision transformers) and vision tasks (e.g., image classification and object detection). Our proposed geometric and photometric transformations enable a range of targeted errors from one crafted input (e.g., higher than 90% attack success rate for classifiers). We analyze effects of model architecture and type/variety of transformations on attack effectiveness. This work forces a paradigm shift by redefining adversarial inputs as dynamic, controllable threats. We highlight the need for robust defenses against such multifaceted, chameleon-like perturbations that current techniques are ill-prepared for.
Cross-Modal Safety Alignment: Is textual unlearning all you need?
May 27, 2024



Recent studies reveal that integrating new modalities into Large Language Models (LLMs), such as Vision-Language Models (VLMs), creates a new attack surface that bypasses existing safety training techniques like Supervised Fine-tuning (SFT) and Reinforcement Learning with Human Feedback (RLHF). While further SFT and RLHF-based safety training can be conducted in multi-modal settings, collecting multi-modal training datasets poses a significant challenge. Inspired by the structural design of recent multi-modal models, where, regardless of the combination of input modalities, all inputs are ultimately fused into the language space, we aim to explore whether unlearning solely in the textual domain can be effective for cross-modality safety alignment. Our evaluation across six datasets empirically demonstrates the transferability -- textual unlearning in VLMs significantly reduces the Attack Success Rate (ASR) to less than 8\% and in some cases, even as low as nearly 2\% for both text-based and vision-text-based attacks, alongside preserving the utility. Moreover, our experiments show that unlearning with a multi-modal dataset offers no potential benefits but incurs significantly increased computational demands, possibly up to 6 times higher.