 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSingle Layer Single Gradient Unlearning
Jul 16, 2024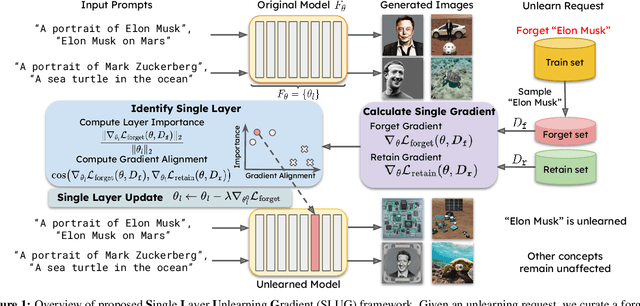
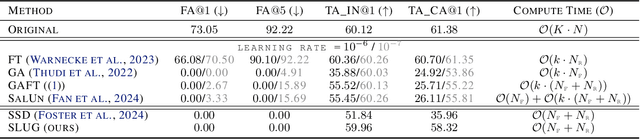
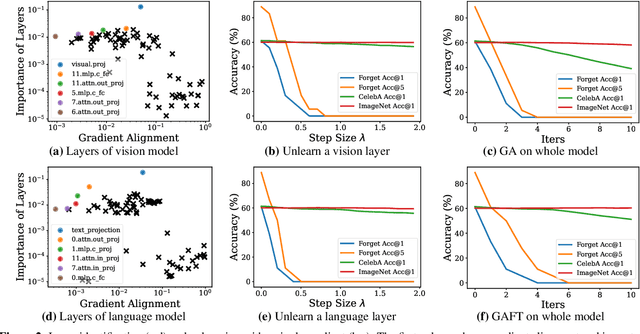
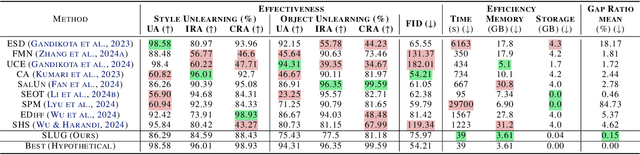
Machine unlearning methods seek to revise pretrained models such that effects of certain training samples can be removed. In addition to effective erasure, low computational cost and general utility retention are also highly desirable. Existing unlearning methods usually involve iterative updates over the model parameters, which incurs a high computational cost. In this work, we propose an efficient method that only requires a one-time gradient computation, with which we modify only a single layer of model parameters. Specifically, we first identify a small number of model layers that lie on the Pareto front of high forget importance and low retain influence as critical layers. Then we search for a suitable step size and take a step along the gradient direction of a single critical layer while keeping other layers frozen. This method is highly modular and can be used to unlearn multiple concepts simultaneously in a controllable manner. We demonstrate the effectiveness and efficiency of this method on various models including CLIP, stable diffusion, and VLMs, surpassing other state-of-the-art methods.
Transformation-Dependent Adversarial Attacks
Jun 12, 2024
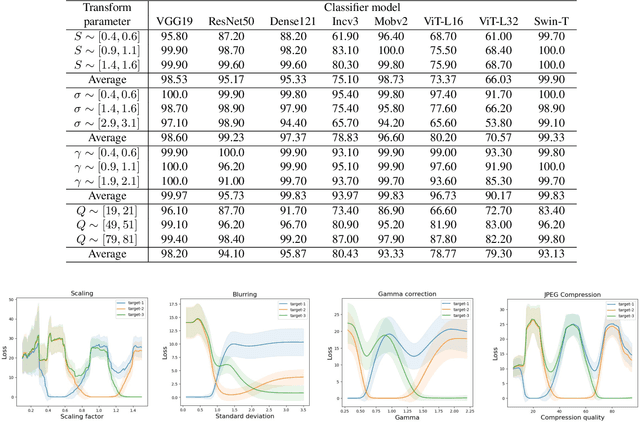
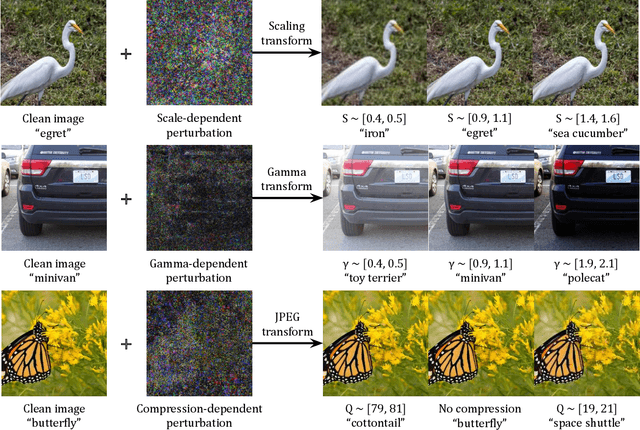
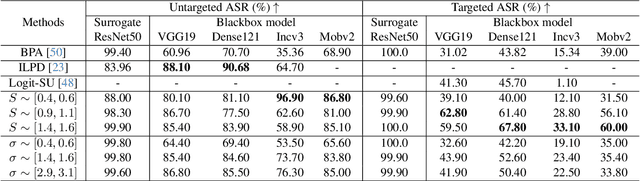
We introduce transformation-dependent adversarial attacks, a new class of threats where a single additive perturbation can trigger diverse, controllable mis-predictions by systematically transforming the input (e.g., scaling, blurring, compression). Unlike traditional attacks with static effects, our perturbations embed metamorphic properties to enable different adversarial attacks as a function of the transformation parameters. We demonstrate the transformation-dependent vulnerability across models (e.g., convolutional networks and vision transformers) and vision tasks (e.g., image classification and object detection). Our proposed geometric and photometric transformations enable a range of targeted errors from one crafted input (e.g., higher than 90% attack success rate for classifiers). We analyze effects of model architecture and type/variety of transformations on attack effectiveness. This work forces a paradigm shift by redefining adversarial inputs as dynamic, controllable threats. We highlight the need for robust defenses against such multifaceted, chameleon-like perturbations that current techniques are ill-prepared for.
Ensemble-based Blackbox Attacks on Dense Prediction
Mar 25, 2023We propose an approach for adversarial attacks on dense prediction models (such as object detectors and segmentation). It is well known that the attacks generated by a single surrogate model do not transfer to arbitrary (blackbox) victim models. Furthermore, targeted attacks are often more challenging than the untargeted attacks. In this paper, we show that a carefully designed ensemble can create effective attacks for a number of victim models. In particular, we show that normalization of the weights for individual models plays a critical role in the success of the attacks. We then demonstrate that by adjusting the weights of the ensemble according to the victim model can further improve the performance of the attacks. We performed a number of experiments for object detectors and segmentation to highlight the significance of the our proposed methods. Our proposed ensemble-based method outperforms existing blackbox attack methods for object detection and segmentation. Finally we show that our proposed method can also generate a single perturbation that can fool multiple blackbox detection and segmentation models simultaneously. Code is available at https://github.com/CSIPlab/EBAD.