 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZebra-CoT: A Dataset for Interleaved Vision Language Reasoning
Jul 22, 2025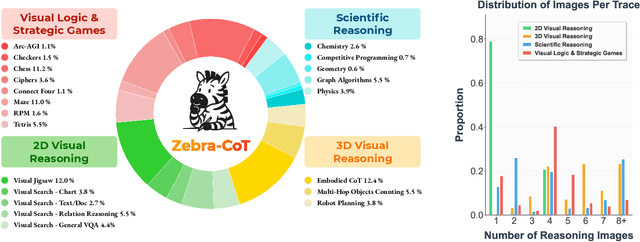

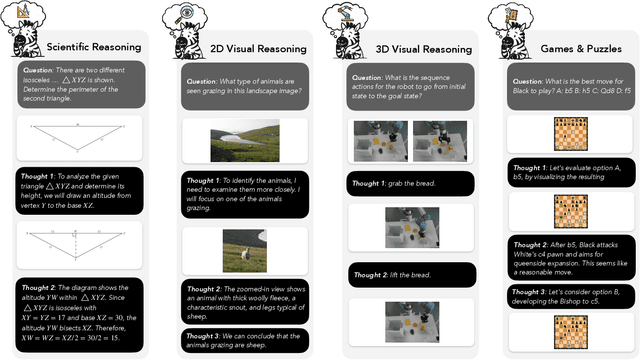

Humans often use visual aids, for example diagrams or sketches, when solving complex problems. Training multimodal models to do the same, known as Visual Chain of Thought (Visual CoT), is challenging due to: (1) poor off-the-shelf visual CoT performance, which hinders reinforcement learning, and (2) the lack of high-quality visual CoT training data. We introduce $\textbf{Zebra-CoT}$, a diverse large-scale dataset with 182,384 samples, containing logically coherent interleaved text-image reasoning traces. We focus on four categories of tasks where sketching or visual reasoning is especially natural, spanning scientific questions such as geometry, physics, and algorithms; 2D visual reasoning tasks like visual search and jigsaw puzzles; 3D reasoning tasks including 3D multi-hop inference, embodied and robot planning; visual logic problems and strategic games like chess. Fine-tuning the Anole-7B model on the Zebra-CoT training corpus results in an improvement of +12% in our test-set accuracy and yields up to +13% performance gain on standard VLM benchmark evaluations. Fine-tuning Bagel-7B yields a model that generates high-quality interleaved visual reasoning chains, underscoring Zebra-CoT's effectiveness for developing multimodal reasoning abilities. We open-source our dataset and models to support development and evaluation of visual CoT.
MORSE-500: A Programmatically Controllable Video Benchmark to Stress-Test Multimodal Reasoning
Jun 05, 2025Despite rapid advances in vision-language models (VLMs), current benchmarks for multimodal reasoning fall short in three key dimensions. First, they overwhelmingly rely on static images, failing to capture the temporal complexity of real-world environments. Second, they narrowly focus on mathematical problem-solving, neglecting the broader spectrum of reasoning skills -- including abstract, physical, planning, spatial, and temporal capabilities -- required for robust multimodal intelligence. Third, many benchmarks quickly saturate, offering limited headroom for diagnosing failure modes or measuring continued progress. We introduce MORSE-500 (Multimodal Reasoning Stress-test Environment), a video benchmark composed of 500 fully scripted clips with embedded questions spanning six complementary reasoning categories. Each instance is programmatically generated using deterministic Python scripts (via Manim, Matplotlib, MoviePy), generative video models, and curated real footage. This script-driven design allows fine-grained control over visual complexity, distractor density, and temporal dynamics -- enabling difficulty to be scaled systematically as models improve. Unlike static benchmarks that become obsolete once saturated, MORSE-500 is built to evolve: its controllable generation pipeline supports the creation of arbitrarily challenging new instances, making it ideally suited for stress-testing next-generation models. Initial experiments with state-of-the-art systems -- including various Gemini 2.5 Pro and OpenAI o3 which represent the strongest available at the time, alongside strong open-source models -- reveal substantial performance gaps across all categories, with particularly large deficits in abstract and planning tasks. We release the full dataset, generation scripts, and evaluation harness to support transparent, reproducible, and forward-looking multimodal reasoning research.
Zero-Shot Vision Encoder Grafting via LLM Surrogates
May 28, 2025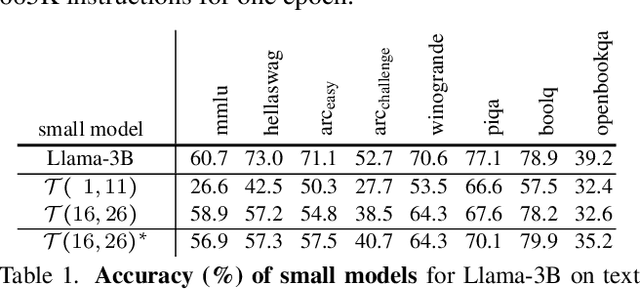
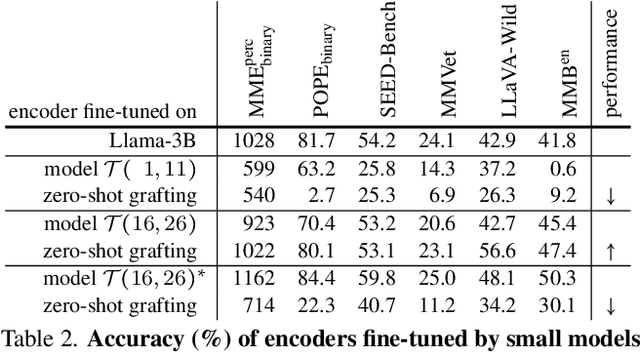
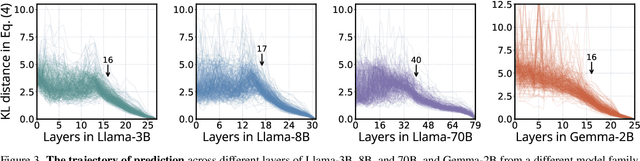

Vision language models (VLMs) typically pair a modestly sized vision encoder with a large language model (LLM), e.g., Llama-70B, making the decoder the primary computational burden during training. To reduce costs, a potential promising strategy is to first train the vision encoder using a small language model before transferring it to the large one. We construct small "surrogate models" that share the same embedding space and representation language as the large target LLM by directly inheriting its shallow layers. Vision encoders trained on the surrogate can then be directly transferred to the larger model, a process we call zero-shot grafting -- when plugged directly into the full-size target LLM, the grafted pair surpasses the encoder-surrogate pair and, on some benchmarks, even performs on par with full decoder training with the target LLM. Furthermore, our surrogate training approach reduces overall VLM training costs by ~45% when using Llama-70B as the decoder.
AegisLLM: Scaling Agentic Systems for Self-Reflective Defense in LLM Security
Apr 29, 2025We introduce AegisLLM, a cooperative multi-agent defense against adversarial attacks and information leakage. In AegisLLM, a structured workflow of autonomous agents - orchestrator, deflector, responder, and evaluator - collaborate to ensure safe and compliant LLM outputs, while self-improving over time through prompt optimization. We show that scaling agentic reasoning system at test-time - both by incorporating additional agent roles and by leveraging automated prompt optimization (such as DSPy)- substantially enhances robustness without compromising model utility. This test-time defense enables real-time adaptability to evolving attacks, without requiring model retraining. Comprehensive evaluations across key threat scenarios, including unlearning and jailbreaking, demonstrate the effectiveness of AegisLLM. On the WMDP unlearning benchmark, AegisLLM achieves near-perfect unlearning with only 20 training examples and fewer than 300 LM calls. For jailbreaking benchmarks, we achieve 51% improvement compared to the base model on StrongReject, with false refusal rates of only 7.9% on PHTest compared to 18-55% for comparable methods. Our results highlight the advantages of adaptive, agentic reasoning over static defenses, establishing AegisLLM as a strong runtime alternative to traditional approaches based on model modifications. Code is available at https://github.com/zikuicai/aegisllm
Single Layer Single Gradient Unlearning
Jul 16, 2024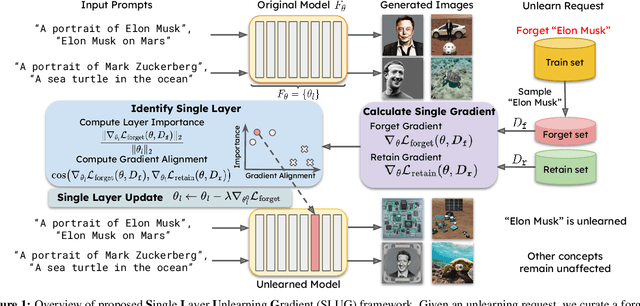
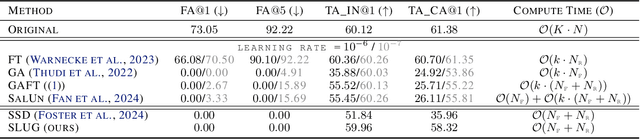
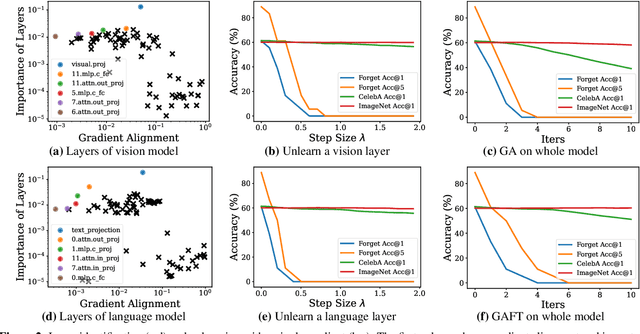
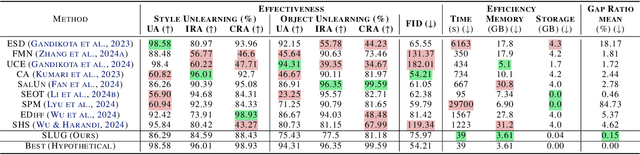
Machine unlearning methods seek to revise pretrained models such that effects of certain training samples can be removed. In addition to effective erasure, low computational cost and general utility retention are also highly desirable. Existing unlearning methods usually involve iterative updates over the model parameters, which incurs a high computational cost. In this work, we propose an efficient method that only requires a one-time gradient computation, with which we modify only a single layer of model parameters. Specifically, we first identify a small number of model layers that lie on the Pareto front of high forget importance and low retain influence as critical layers. Then we search for a suitable step size and take a step along the gradient direction of a single critical layer while keeping other layers frozen. This method is highly modular and can be used to unlearn multiple concepts simultaneously in a controllable manner. We demonstrate the effectiveness and efficiency of this method on various models including CLIP, stable diffusion, and VLMs, surpassing other state-of-the-art methods.
Transformation-Dependent Adversarial Attacks
Jun 12, 2024
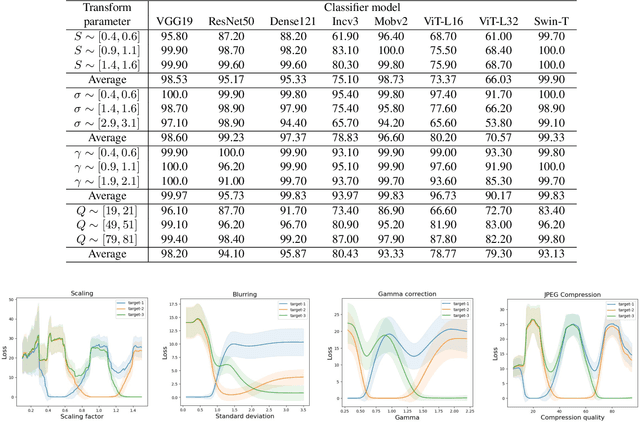
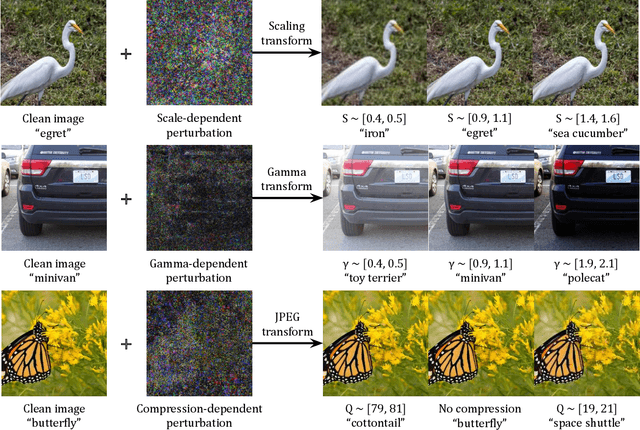
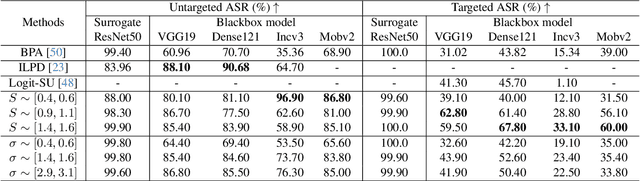
We introduce transformation-dependent adversarial attacks, a new class of threats where a single additive perturbation can trigger diverse, controllable mis-predictions by systematically transforming the input (e.g., scaling, blurring, compression). Unlike traditional attacks with static effects, our perturbations embed metamorphic properties to enable different adversarial attacks as a function of the transformation parameters. We demonstrate the transformation-dependent vulnerability across models (e.g., convolutional networks and vision transformers) and vision tasks (e.g., image classification and object detection). Our proposed geometric and photometric transformations enable a range of targeted errors from one crafted input (e.g., higher than 90% attack success rate for classifiers). We analyze effects of model architecture and type/variety of transformations on attack effectiveness. This work forces a paradigm shift by redefining adversarial inputs as dynamic, controllable threats. We highlight the need for robust defenses against such multifaceted, chameleon-like perturbations that current techniques are ill-prepared for.
Cross-Modal Safety Alignment: Is textual unlearning all you need?
May 27, 2024



Recent studies reveal that integrating new modalities into Large Language Models (LLMs), such as Vision-Language Models (VLMs), creates a new attack surface that bypasses existing safety training techniques like Supervised Fine-tuning (SFT) and Reinforcement Learning with Human Feedback (RLHF). While further SFT and RLHF-based safety training can be conducted in multi-modal settings, collecting multi-modal training datasets poses a significant challenge. Inspired by the structural design of recent multi-modal models, where, regardless of the combination of input modalities, all inputs are ultimately fused into the language space, we aim to explore whether unlearning solely in the textual domain can be effective for cross-modality safety alignment. Our evaluation across six datasets empirically demonstrates the transferability -- textual unlearning in VLMs significantly reduces the Attack Success Rate (ASR) to less than 8\% and in some cases, even as low as nearly 2\% for both text-based and vision-text-based attacks, alongside preserving the utility. Moreover, our experiments show that unlearning with a multi-modal dataset offers no potential benefits but incurs significantly increased computational demands, possibly up to 6 times higher.
Ensemble-based Blackbox Attacks on Dense Prediction
Mar 25, 2023We propose an approach for adversarial attacks on dense prediction models (such as object detectors and segmentation). It is well known that the attacks generated by a single surrogate model do not transfer to arbitrary (blackbox) victim models. Furthermore, targeted attacks are often more challenging than the untargeted attacks. In this paper, we show that a carefully designed ensemble can create effective attacks for a number of victim models. In particular, we show that normalization of the weights for individual models plays a critical role in the success of the attacks. We then demonstrate that by adjusting the weights of the ensemble according to the victim model can further improve the performance of the attacks. We performed a number of experiments for object detectors and segmentation to highlight the significance of the our proposed methods. Our proposed ensemble-based method outperforms existing blackbox attack methods for object detection and segmentation. Finally we show that our proposed method can also generate a single perturbation that can fool multiple blackbox detection and segmentation models simultaneously. Code is available at https://github.com/CSIPlab/EBAD.
Disguise without Disruption: Utility-Preserving Face De-Identification
Mar 23, 2023
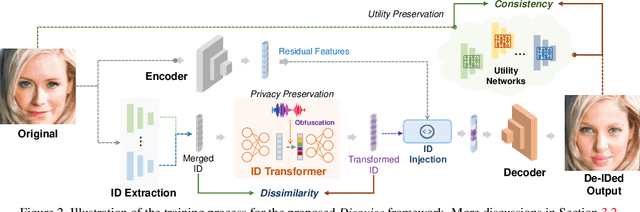
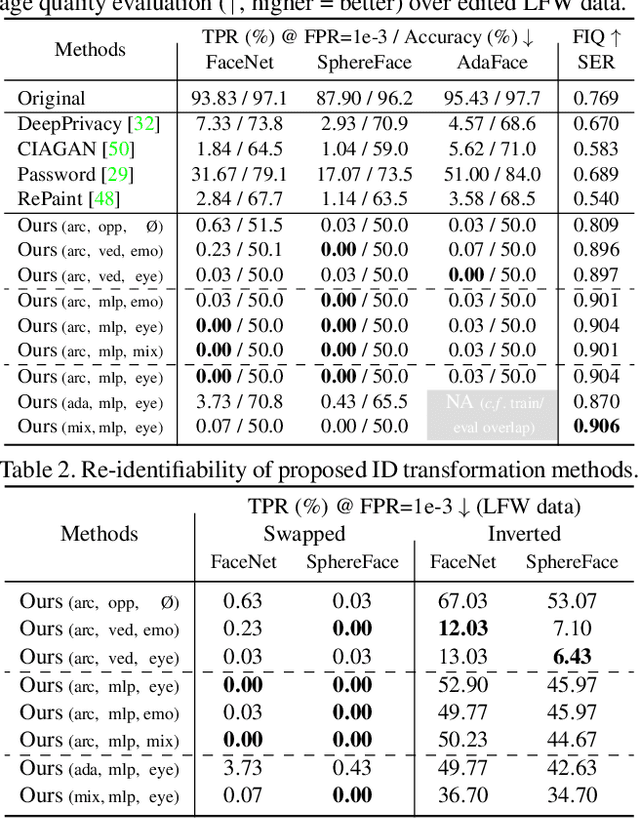

With the increasing ubiquity of cameras and smart sensors, humanity is generating data at an exponential rate. Access to this trove of information, often covering yet-underrepresented use-cases (e.g., AI in medical settings) could fuel a new generation of deep-learning tools. However, eager data scientists should first provide satisfying guarantees w.r.t. the privacy of individuals present in these untapped datasets. This is especially important for images or videos depicting faces, as their biometric information is the target of most identification methods. While a variety of solutions have been proposed to de-identify such images, they often corrupt other non-identifying facial attributes that would be relevant for downstream tasks. In this paper, we propose Disguise, a novel algorithm to seamlessly de-identify facial images while ensuring the usability of the altered data. Unlike prior arts, we ground our solution in both differential privacy and ensemble-learning research domains. Our method extracts and swaps depicted identities with fake ones, synthesized via variational mechanisms to maximize obfuscation and non-invertibility; while leveraging the supervision from a mixture-of-experts to disentangle and preserve other utility attributes. We extensively evaluate our method on multiple datasets, demonstrating higher de-identification rate and superior consistency than prior art w.r.t. various downstream tasks.
Blackbox Attacks via Surrogate Ensemble Search
Aug 07, 2022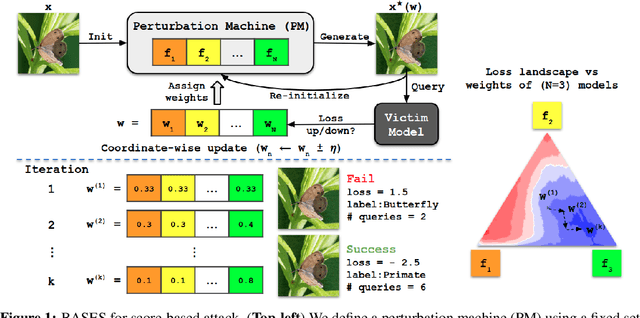

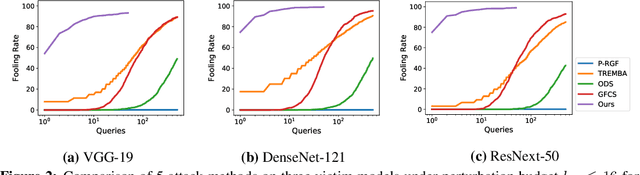

Blackbox adversarial attacks can be categorized into transfer- and query-based attacks. Transfer methods do not require any feedback from the victim model, but provide lower success rates compared to query-based methods. Query attacks often require a large number of queries for success. To achieve the best of both approaches, recent efforts have tried to combine them, but still require hundreds of queries to achieve high success rates (especially for targeted attacks). In this paper, we propose a novel method for blackbox attacks via surrogate ensemble search (BASES) that can generate highly successful blackbox attacks using an extremely small number of queries. We first define a perturbation machine that generates a perturbed image by minimizing a weighted loss function over a fixed set of surrogate models. To generate an attack for a given victim model, we search over the weights in the loss function using queries generated by the perturbation machine. Since the dimension of the search space is small (same as the number of surrogate models), the search requires a small number of queries. We demonstrate that our proposed method achieves better success rate with at least 30x fewer queries compared to state-of-the-art methods on different image classifiers trained with ImageNet (including VGG-19, DenseNet-121, and ResNext-50). In particular, our method requires as few as 3 queries per image (on average) to achieve more than a 90% success rate for targeted attacks and 1-2 queries per image for over a 99% success rate for non-targeted attacks. Our method is also effective on Google Cloud Vision API and achieved a 91% non-targeted attack success rate with 2.9 queries per image. We also show that the perturbations generated by our proposed method are highly transferable and can be adopted for hard-label blackbox attacks.