 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward Autonomous Laboratory Safety Monitoring with Vision Language Models: Learning to See Hazards Through Scene Structure
Jan 31, 2026Laboratories are prone to severe injuries from minor unsafe actions, yet continuous safety monitoring -- beyond mandatory pre-lab safety training -- is limited by human availability. Vision language models (VLMs) offer promise for autonomous laboratory safety monitoring, but their effectiveness in realistic settings is unclear due to the lack of visual evaluation data, as most safety incidents are documented primarily as unstructured text. To address this gap, we first introduce a structured data generation pipeline that converts textual laboratory scenarios into aligned triples of (image, scene graph, ground truth), using large language models as scene graph architects and image generation models as renderers. Our experiments on the synthetic dataset of 1,207 samples across 362 unique scenarios and seven open- and closed-source models show that VLMs perform effectively given textual scene graph, but degrade substantially in visual-only settings indicating difficulty in extracting structured object relationships directly from pixels. To overcome this, we propose a post-training context-engineering approach, scene-graph-guided alignment, to bridge perceptual gaps in VLMs by translating visual inputs into structured scene graphs better aligned with VLM reasoning, improving hazard detection performance in visual only settings.
Visual Alignment of Medical Vision-Language Models for Grounded Radiology Report Generation
Dec 18, 2025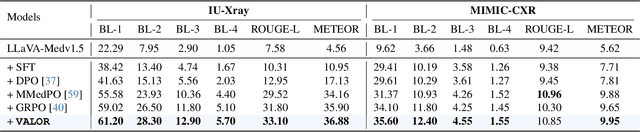
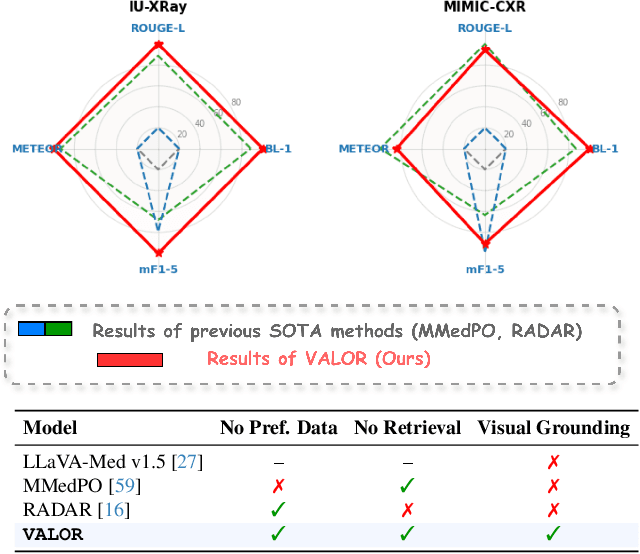
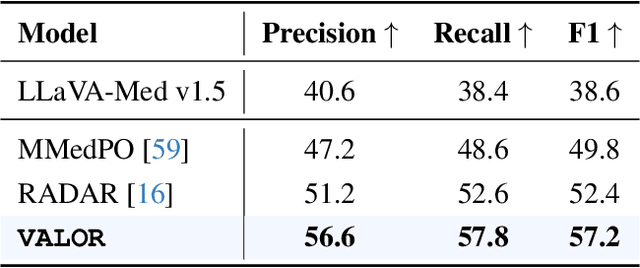
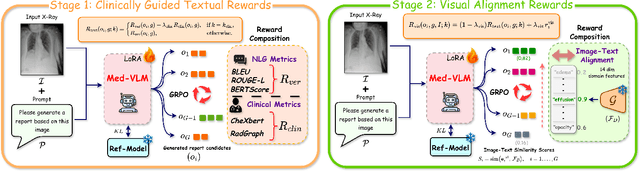
Radiology Report Generation (RRG) is a critical step toward automating healthcare workflows, facilitating accurate patient assessments, and reducing the workload of medical professionals. Despite recent progress in Large Medical Vision-Language Models (Med-VLMs), generating radiology reports that are both visually grounded and clinically accurate remains a significant challenge. Existing approaches often rely on large labeled corpora for pre-training, costly task-specific preference data, or retrieval-based methods. However, these strategies do not adequately mitigate hallucinations arising from poor cross-modal alignment between visual and linguistic representations. To address these limitations, we propose VALOR:Visual Alignment of Medical Vision-Language Models for GrOunded Radiology Report Generation. Our method introduces a reinforcement learning-based post-alignment framework utilizing Group-Relative Proximal Optimization (GRPO). The training proceeds in two stages: (1) improving the Med-VLM with textual rewards to encourage clinically precise terminology, and (2) aligning the vision projection module of the textually grounded model with disease findings, thereby guiding attention toward image re gions most relevant to the diagnostic task. Extensive experiments on multiple benchmarks demonstrate that VALOR substantially improves factual accuracy and visual grounding, achieving significant performance gains over state-of-the-art report generation methods.
LINGUAL: Language-INtegrated GUidance in Active Learning for Medical Image Segmentation
Nov 18, 2025Although active learning (AL) in segmentation tasks enables experts to annotate selected regions of interest (ROIs) instead of entire images, it remains highly challenging, labor-intensive, and cognitively demanding due to the blurry and ambiguous boundaries commonly observed in medical images. Also, in conventional AL, annotation effort is a function of the ROI- larger regions make the task cognitively easier but incur higher annotation costs, whereas smaller regions demand finer precision and more attention from the expert. In this context, language guidance provides an effective alternative, requiring minimal expert effort while bypassing the cognitively demanding task of precise boundary delineation in segmentation. Towards this goal, we introduce LINGUAL: a framework that receives natural language instructions from an expert, translates them into executable programs through in-context learning, and automatically performs the corresponding sequence of sub-tasks without any human intervention. We demonstrate the effectiveness of LINGUAL in active domain adaptation (ADA) achieving comparable or superior performance to AL baselines while reducing estimated annotation time by approximately 80%.
SAGA: Source Attribution of Generative AI Videos
Nov 16, 2025The proliferation of generative AI has led to hyper-realistic synthetic videos, escalating misuse risks and outstripping binary real/fake detectors. We introduce SAGA (Source Attribution of Generative AI videos), the first comprehensive framework to address the urgent need for AI-generated video source attribution at a large scale. Unlike traditional detection, SAGA identifies the specific generative model used. It uniquely provides multi-granular attribution across five levels: authenticity, generation task (e.g., T2V/I2V), model version, development team, and the precise generator, offering far richer forensic insights. Our novel video transformer architecture, leveraging features from a robust vision foundation model, effectively captures spatio-temporal artifacts. Critically, we introduce a data-efficient pretrain-and-attribute strategy, enabling SAGA to achieve state-of-the-art attribution using only 0.5\% of source-labeled data per class, matching fully supervised performance. Furthermore, we propose Temporal Attention Signatures (T-Sigs), a novel interpretability method that visualizes learned temporal differences, offering the first explanation for why different video generators are distinguishable. Extensive experiments on public datasets, including cross-domain scenarios, demonstrate that SAGA sets a new benchmark for synthetic video provenance, providing crucial, interpretable insights for forensic and regulatory applications.
Towards Source-Free Machine Unlearning
Aug 20, 2025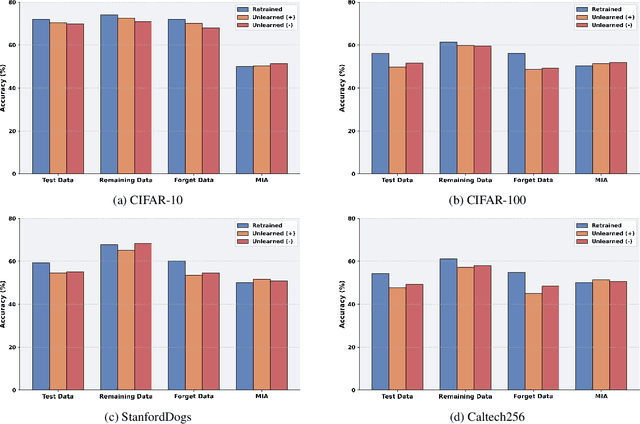
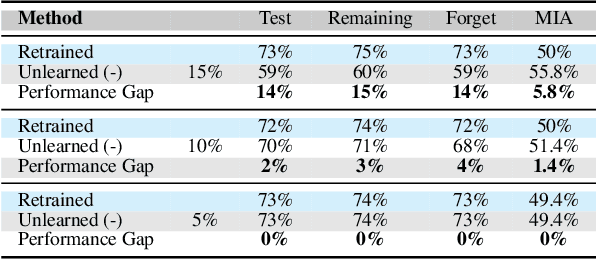
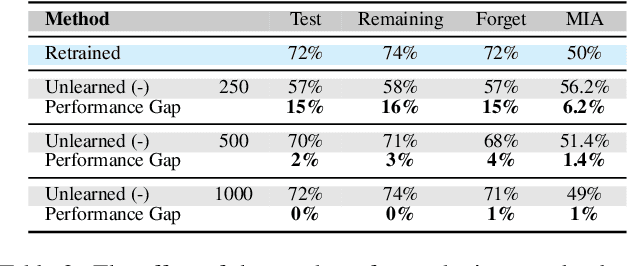
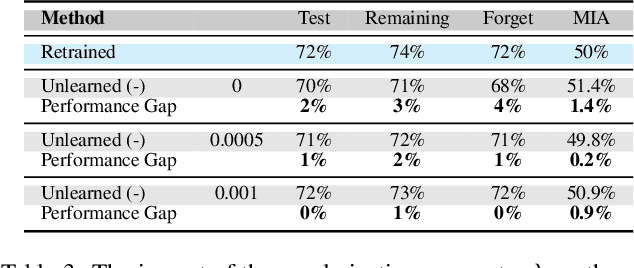
As machine learning becomes more pervasive and data privacy regulations evolve, the ability to remove private or copyrighted information from trained models is becoming an increasingly critical requirement. Existing unlearning methods often rely on the assumption of having access to the entire training dataset during the forgetting process. However, this assumption may not hold true in practical scenarios where the original training data may not be accessible, i.e., the source-free setting. To address this challenge, we focus on the source-free unlearning scenario, where an unlearning algorithm must be capable of removing specific data from a trained model without requiring access to the original training dataset. Building on recent work, we present a method that can estimate the Hessian of the unknown remaining training data, a crucial component required for efficient unlearning. Leveraging this estimation technique, our method enables efficient zero-shot unlearning while providing robust theoretical guarantees on the unlearning performance, while maintaining performance on the remaining data. Extensive experiments over a wide range of datasets verify the efficacy of our method.
Towards Generalizable Safety in Crowd Navigation via Conformal Uncertainty Handling
Aug 07, 2025Mobile robots navigating in crowds trained using reinforcement learning are known to suffer performance degradation when faced with out-of-distribution scenarios. We propose that by properly accounting for the uncertainties of pedestrians, a robot can learn safe navigation policies that are robust to distribution shifts. Our method augments agent observations with prediction uncertainty estimates generated by adaptive conformal inference, and it uses these estimates to guide the agent's behavior through constrained reinforcement learning. The system helps regulate the agent's actions and enables it to adapt to distribution shifts. In the in-distribution setting, our approach achieves a 96.93% success rate, which is over 8.80% higher than the previous state-of-the-art baselines with over 3.72 times fewer collisions and 2.43 times fewer intrusions into ground-truth human future trajectories. In three out-of-distribution scenarios, our method shows much stronger robustness when facing distribution shifts in velocity variations, policy changes, and transitions from individual to group dynamics. We deploy our method on a real robot, and experiments show that the robot makes safe and robust decisions when interacting with both sparse and dense crowds. Our code and videos are available on https://gen-safe-nav.github.io/.
HEAL: An Empirical Study on Hallucinations in Embodied Agents Driven by Large Language Models
Jun 18, 2025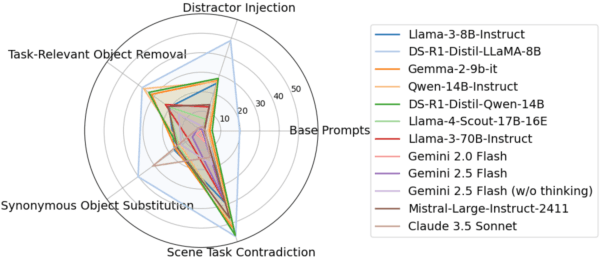
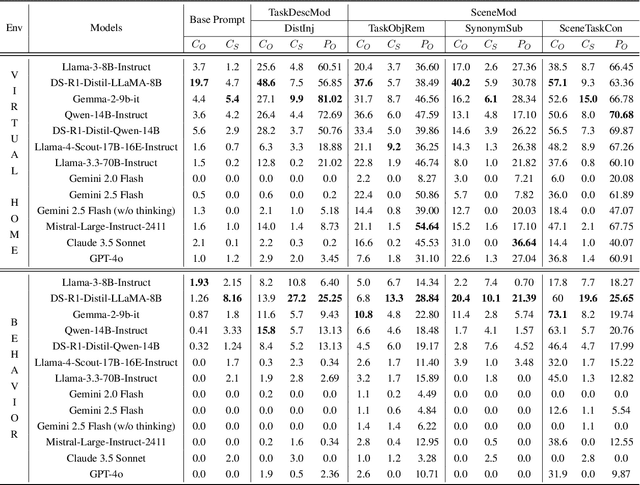

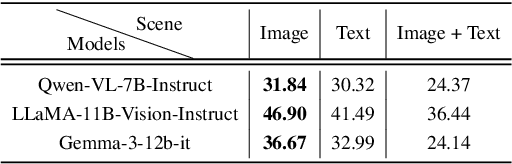
Large language models (LLMs) are increasingly being adopted as the cognitive core of embodied agents. However, inherited hallucinations, which stem from failures to ground user instructions in the observed physical environment, can lead to navigation errors, such as searching for a refrigerator that does not exist. In this paper, we present the first systematic study of hallucinations in LLM-based embodied agents performing long-horizon tasks under scene-task inconsistencies. Our goal is to understand to what extent hallucinations occur, what types of inconsistencies trigger them, and how current models respond. To achieve these goals, we construct a hallucination probing set by building on an existing benchmark, capable of inducing hallucination rates up to 40x higher than base prompts. Evaluating 12 models across two simulation environments, we find that while models exhibit reasoning, they fail to resolve scene-task inconsistencies-highlighting fundamental limitations in handling infeasible tasks. We also provide actionable insights on ideal model behavior for each scenario, offering guidance for developing more robust and reliable planning strategies.
Gradient Inversion Attacks on Parameter-Efficient Fine-Tuning
Jun 04, 2025Federated learning (FL) allows multiple data-owners to collaboratively train machine learning models by exchanging local gradients, while keeping their private data on-device. To simultaneously enhance privacy and training efficiency, recently parameter-efficient fine-tuning (PEFT) of large-scale pretrained models has gained substantial attention in FL. While keeping a pretrained (backbone) model frozen, each user fine-tunes only a few lightweight modules to be used in conjunction, to fit specific downstream applications. Accordingly, only the gradients with respect to these lightweight modules are shared with the server. In this work, we investigate how the privacy of the fine-tuning data of the users can be compromised via a malicious design of the pretrained model and trainable adapter modules. We demonstrate gradient inversion attacks on a popular PEFT mechanism, the adapter, which allow an attacker to reconstruct local data samples of a target user, using only the accessible adapter gradients. Via extensive experiments, we demonstrate that a large batch of fine-tuning images can be retrieved with high fidelity. Our attack highlights the need for privacy-preserving mechanisms for PEFT, while opening up several future directions. Our code is available at https://github.com/info-ucr/PEFTLeak.
Leveraging Synthetic Adult Datasets for Unsupervised Infant Pose Estimation
Apr 08, 2025Human pose estimation is a critical tool across a variety of healthcare applications. Despite significant progress in pose estimation algorithms targeting adults, such developments for infants remain limited. Existing algorithms for infant pose estimation, despite achieving commendable performance, depend on fully supervised approaches that require large amounts of labeled data. These algorithms also struggle with poor generalizability under distribution shifts. To address these challenges, we introduce SHIFT: Leveraging SyntHetic Adult Datasets for Unsupervised InFanT Pose Estimation, which leverages the pseudo-labeling-based Mean-Teacher framework to compensate for the lack of labeled data and addresses distribution shifts by enforcing consistency between the student and the teacher pseudo-labels. Additionally, to penalize implausible predictions obtained from the mean-teacher framework, we incorporate an infant manifold pose prior. To enhance SHIFT's self-occlusion perception ability, we propose a novel visibility consistency module for improved alignment of the predicted poses with the original image. Extensive experiments on multiple benchmarks show that SHIFT significantly outperforms existing state-of-the-art unsupervised domain adaptation (UDA) pose estimation methods by 5% and supervised infant pose estimation methods by a margin of 16%. The project page is available at: https://sarosijbose.github.io/SHIFT.
SeGuE: Semantic Guided Exploration for Mobile Robots
Apr 04, 2025The rise of embodied AI applications has enabled robots to perform complex tasks which require a sophisticated understanding of their environment. To enable successful robot operation in such settings, maps must be constructed so that they include semantic information, in addition to geometric information. In this paper, we address the novel problem of semantic exploration, whereby a mobile robot must autonomously explore an environment to fully map both its structure and the semantic appearance of features. We develop a method based on next-best-view exploration, where potential poses are scored based on the semantic features visible from that pose. We explore two alternative methods for sampling potential views and demonstrate the effectiveness of our framework in both simulation and physical experiments. Automatic creation of high-quality semantic maps can enable robots to better understand and interact with their environments and enable future embodied AI applications to be more easily deployed.