 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeGuE: Semantic Guided Exploration for Mobile Robots
Apr 04, 2025The rise of embodied AI applications has enabled robots to perform complex tasks which require a sophisticated understanding of their environment. To enable successful robot operation in such settings, maps must be constructed so that they include semantic information, in addition to geometric information. In this paper, we address the novel problem of semantic exploration, whereby a mobile robot must autonomously explore an environment to fully map both its structure and the semantic appearance of features. We develop a method based on next-best-view exploration, where potential poses are scored based on the semantic features visible from that pose. We explore two alternative methods for sampling potential views and demonstrate the effectiveness of our framework in both simulation and physical experiments. Automatic creation of high-quality semantic maps can enable robots to better understand and interact with their environments and enable future embodied AI applications to be more easily deployed.
Vision-based Xylem Wetness Classification in Stem Water Potential Determination
Sep 24, 2024



Water is often overused in irrigation, making efficient management of it crucial. Precision Agriculture emphasizes tools like stem water potential (SWP) analysis for better plant status determination. However, such tools often require labor-intensive in-situ sampling. Automation and machine learning can streamline this process and enhance outcomes. This work focused on automating stem detection and xylem wetness classification using the Scholander Pressure Chamber, a widely used but demanding method for SWP measurement. The aim was to refine stem detection and develop computer-vision-based methods to better classify water emergence at the xylem. To this end, we collected and manually annotated video data, applying vision- and learning-based methods for detection and classification. Additionally, we explored data augmentation and fine-tuned parameters to identify the most effective models. The identified best-performing models for stem detection and xylem wetness classification were evaluated end-to-end over 20 SWP measurements. Learning-based stem detection via YOLOv8n combined with ResNet50-based classification achieved a Top-1 accuracy of 80.98%, making it the best-performing approach for xylem wetness classification.
R^3: On-device Real-Time Deep Reinforcement Learning for Autonomous Robotics
Sep 15, 2023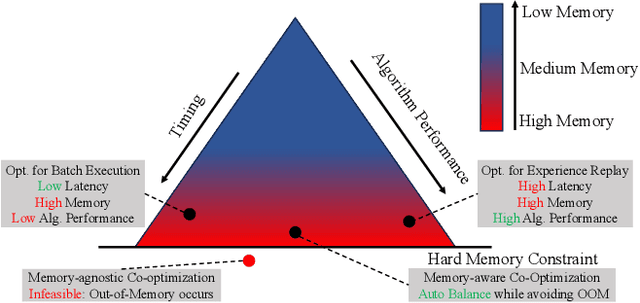

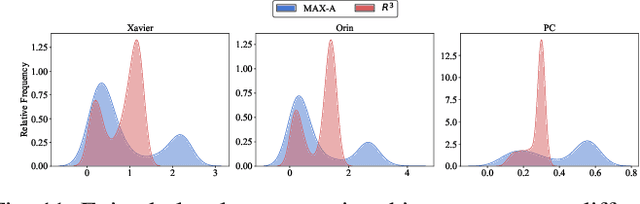
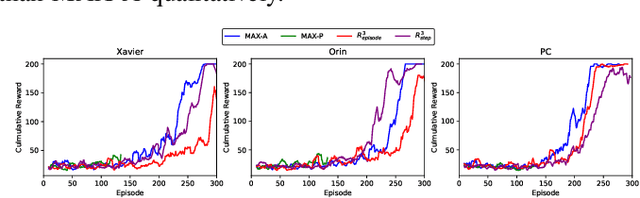
Autonomous robotic systems, like autonomous vehicles and robotic search and rescue, require efficient on-device training for continuous adaptation of Deep Reinforcement Learning (DRL) models in dynamic environments. This research is fundamentally motivated by the need to understand and address the challenges of on-device real-time DRL, which involves balancing timing and algorithm performance under memory constraints, as exposed through our extensive empirical studies. This intricate balance requires co-optimizing two pivotal parameters of DRL training -- batch size and replay buffer size. Configuring these parameters significantly affects timing and algorithm performance, while both (unfortunately) require substantial memory allocation to achieve near-optimal performance. This paper presents R^3, a holistic solution for managing timing, memory, and algorithm performance in on-device real-time DRL training. R^3 employs (i) a deadline-driven feedback loop with dynamic batch sizing for optimizing timing, (ii) efficient memory management to reduce memory footprint and allow larger replay buffer sizes, and (iii) a runtime coordinator guided by heuristic analysis and a runtime profiler for dynamically adjusting memory resource reservations. These components collaboratively tackle the trade-offs in on-device DRL training, improving timing and algorithm performance while minimizing the risk of out-of-memory (OOM) errors. We implemented and evaluated R^3 extensively across various DRL frameworks and benchmarks on three hardware platforms commonly adopted by autonomous robotic systems. Additionally, we integrate R^3 with a popular realistic autonomous car simulator to demonstrate its real-world applicability. Evaluation results show that R^3 achieves efficacy across diverse platforms, ensuring consistent latency performance and timing predictability with minimal overhead.
PIMbot: Policy and Incentive Manipulation for Multi-Robot Reinforcement Learning in Social Dilemmas
Jul 29, 2023Recent research has demonstrated the potential of reinforcement learning (RL) in enabling effective multi-robot collaboration, particularly in social dilemmas where robots face a trade-off between self-interests and collective benefits. However, environmental factors such as miscommunication and adversarial robots can impact cooperation, making it crucial to explore how multi-robot communication can be manipulated to achieve different outcomes. This paper presents a novel approach, namely PIMbot, to manipulating the reward function in multi-robot collaboration through two distinct forms of manipulation: policy and incentive manipulation. Our work introduces a new angle for manipulation in recent multi-agent RL social dilemmas that utilize a unique reward function for incentivization. By utilizing our proposed PIMbot mechanisms, a robot is able to manipulate the social dilemma environment effectively. PIMbot has the potential for both positive and negative impacts on the task outcome, where positive impacts lead to faster convergence to the global optimum and maximized rewards for any chosen robot. Conversely, negative impacts can have a detrimental effect on the overall task performance. We present comprehensive experimental results that demonstrate the effectiveness of our proposed methods in the Gazebo-simulated multi-robot environment. Our work provides insights into how inter-robot communication can be manipulated and has implications for various robotic applications. %, including robotics, transportation, and manufacturing.