 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBOXR: Body and head motion Optimization framework for eXtended Reality
Oct 16, 2024
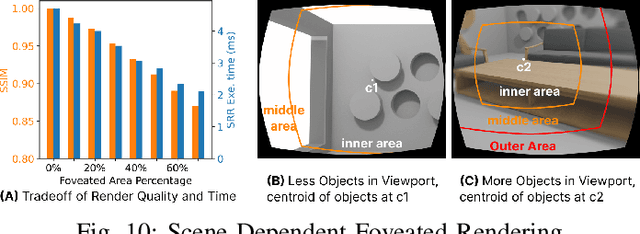
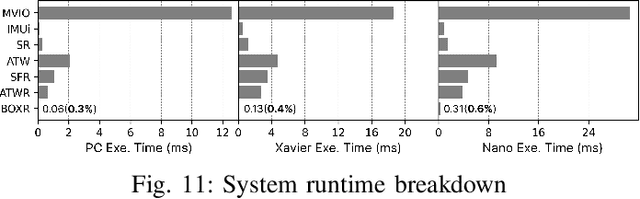
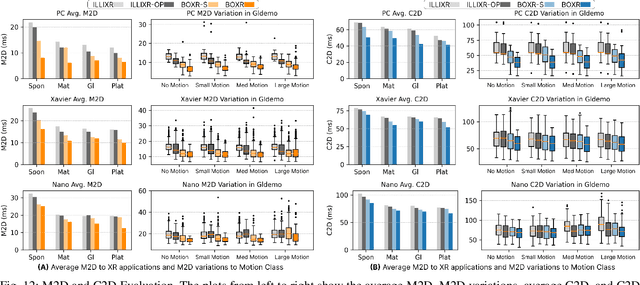
The emergence of standalone XR systems has enhanced user mobility, accommodating both subtle, frequent head motions and substantial, less frequent body motions. However, the pervasively used M2D latency metric, which measures the delay between the most recent motion and its corresponding display update, only accounts for head motions. This oversight can leave users prone to motion sickness if significant body motion is involved. Although existing methods optimize M2D latency through asynchronous task scheduling and reprojection methods, they introduce challenges like resource contention between tasks and outdated pose data. These challenges are further complicated by user motion dynamics and scene changes during runtime. To address these issues, we for the first time introduce the C2D latency metric, which captures the delay caused by body motions, and present BOXR, a framework designed to co-optimize both body and head motion delays within an XR system. BOXR enhances the coordination between M2D and C2D latencies by efficiently scheduling tasks to avoid contentions while maintaining an up-to-date pose in the output frame. Moreover, BOXR incorporates a motion-driven visual inertial odometer to adjust to user motion dynamics and employs scene-dependent foveated rendering to manage changes in the scene effectively. Our evaluations show that BOXR significantly outperforms state-of-the-art solutions in 11 EuRoC MAV datasets across 4 XR applications across 3 hardware platforms. In controlled motion and scene settings, BOXR reduces M2D and C2D latencies by up to 63% and 27%, respectively and increases frame rate by up to 43%. In practical deployments, BOXR achieves substantial reductions in real-world scenarios up to 42% in M2D latency and 31% in C2D latency while maintaining remarkably low miss rates of only 1.6% for M2D requirements and 1.0% for C2D requirements.
Timing Analysis and Priority-driven Enhancements of ROS 2 Multi-threaded Executors
Aug 15, 2024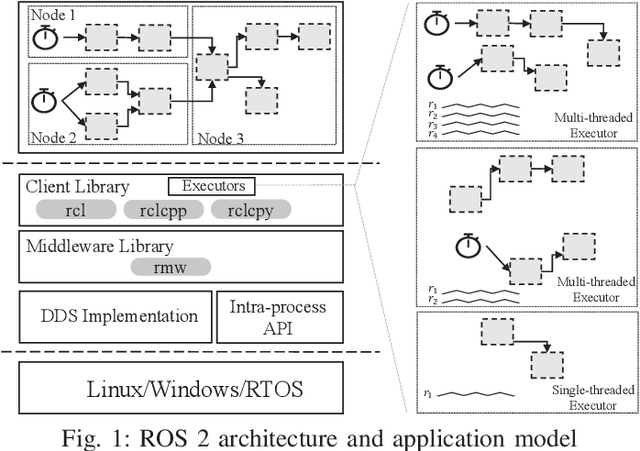
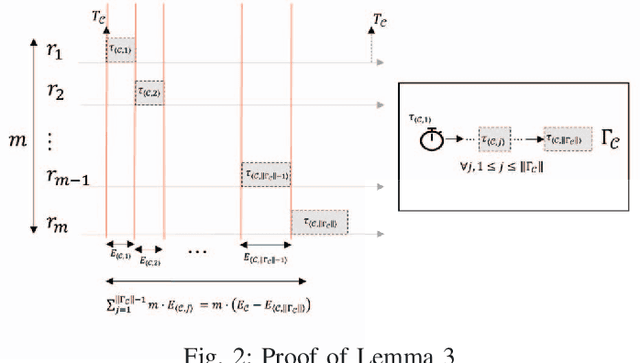
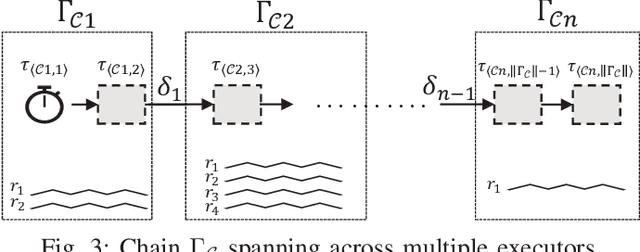
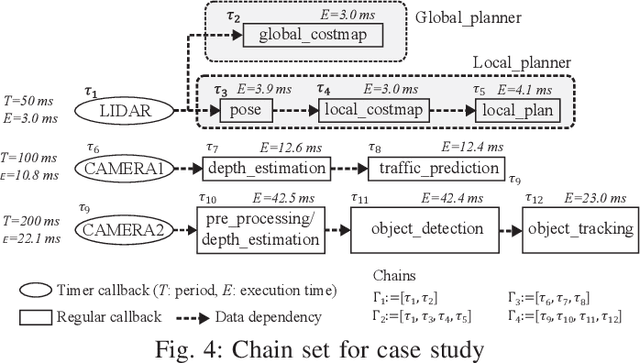
The second generation of Robotic Operating System, ROS 2, has gained much attention for its potential to be used for safety-critical robotic applications. The need to provide a solid foundation for timing correctness and scheduling mechanisms is therefore growing rapidly. Although there are some pioneering studies conducted on formally analyzing the response time of processing chains in ROS 2, the focus has been limited to single-threaded executors, and multi-threaded executors, despite their advantages, have not been studied well. To fill this knowledge gap, in this paper, we propose a comprehensive response-time analysis framework for chains running on ROS 2 multi-threaded executors. We first analyze the timing behavior of the default scheduling scheme in ROS 2 multi-threaded executors, and then present priority-driven scheduling enhancements to address the limitations of the default scheme. Our framework can analyze chains with both arbitrary and constrained deadlines and also the effect of mutually-exclusive callback groups. Evaluation is conducted by a case study on NVIDIA Jetson AGX Xavier and schedulability experiments using randomly-generated chains. The results demonstrate that our analysis framework can safely upper-bound response times under various conditions and the priority-driven scheduling enhancements not only reduce the response time of critical chains but also improve analytical bounds.
PAAM: A Framework for Coordinated and Priority-Driven Accelerator Management in ROS 2
Apr 09, 2024This paper proposes a Priority-driven Accelerator Access Management (PAAM) framework for multi-process robotic applications built on top of the Robot Operating System (ROS) 2 middleware platform. The framework addresses the issue of predictable execution of time- and safety-critical callback chains that require hardware accelerators such as GPUs and TPUs. PAAM provides a standalone ROS executor that acts as an accelerator resource server, arbitrating accelerator access requests from all other callbacks at the application layer. This approach enables coordinated and priority-driven accelerator access management in multi-process robotic systems. The framework design is directly applicable to all types of accelerators and enables granular control over how specific chains access accelerators, making it possible to achieve predictable real-time support for accelerators used by safety-critical callback chains without making changes to underlying accelerator device drivers. The paper shows that PAAM also offers a theoretical analysis that can upper bound the worst-case response time of safety-critical callback chains that necessitate accelerator access. This paper also demonstrates that complex robotic systems with extensive accelerator usage that are integrated with PAAM may achieve up to a 91\% reduction in end-to-end response time of their critical callback chains.
EBV: Electronic Bee-Veterinarian for Principled Mining and Forecasting of Honeybee Time Series
Feb 02, 2024Honeybees are vital for pollination and food production. Among many factors, extreme temperature (e.g., due to climate change) is particularly dangerous for bee health. Anticipating such extremities would allow beekeepers to take early preventive action. Thus, given sensor (temperature) time series data from beehives, how can we find patterns and do forecasting? Forecasting is crucial as it helps spot unexpected behavior and thus issue warnings to the beekeepers. In that case, what are the right models for forecasting? ARIMA, RNNs, or something else? We propose the EBV (Electronic Bee-Veterinarian) method, which has the following desirable properties: (i) principled: it is based on a) diffusion equations from physics and b) control theory for feedback-loop controllers; (ii) effective: it works well on multiple, real-world time sequences, (iii) explainable: it needs only a handful of parameters (e.g., bee strength) that beekeepers can easily understand and trust, and (iv) scalable: it performs linearly in time. We applied our method to multiple real-world time sequences, and found that it yields accurate forecasting (up to 49% improvement in RMSE compared to baselines), and segmentation. Specifically, discontinuities detected by EBV mostly coincide with domain expert's opinions, showcasing our approach's potential and practical feasibility. Moreover, EBV is scalable and fast, taking about 20 minutes on a stock laptop for reconstructing two months of sensor data.
R^3: On-device Real-Time Deep Reinforcement Learning for Autonomous Robotics
Sep 15, 2023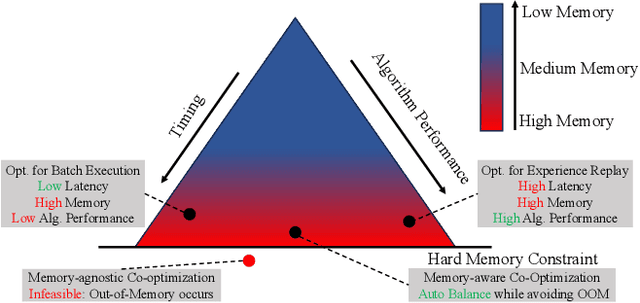

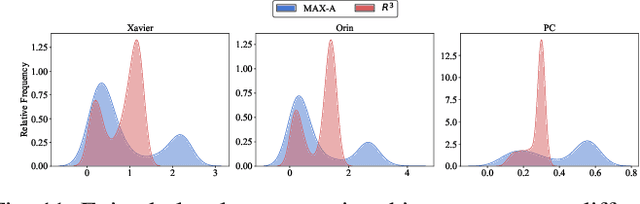
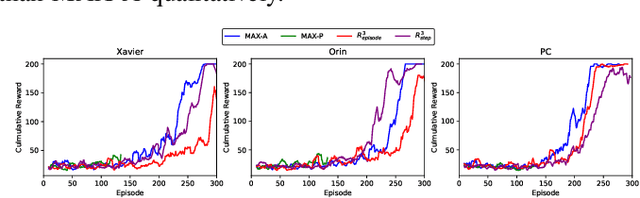
Autonomous robotic systems, like autonomous vehicles and robotic search and rescue, require efficient on-device training for continuous adaptation of Deep Reinforcement Learning (DRL) models in dynamic environments. This research is fundamentally motivated by the need to understand and address the challenges of on-device real-time DRL, which involves balancing timing and algorithm performance under memory constraints, as exposed through our extensive empirical studies. This intricate balance requires co-optimizing two pivotal parameters of DRL training -- batch size and replay buffer size. Configuring these parameters significantly affects timing and algorithm performance, while both (unfortunately) require substantial memory allocation to achieve near-optimal performance. This paper presents R^3, a holistic solution for managing timing, memory, and algorithm performance in on-device real-time DRL training. R^3 employs (i) a deadline-driven feedback loop with dynamic batch sizing for optimizing timing, (ii) efficient memory management to reduce memory footprint and allow larger replay buffer sizes, and (iii) a runtime coordinator guided by heuristic analysis and a runtime profiler for dynamically adjusting memory resource reservations. These components collaboratively tackle the trade-offs in on-device DRL training, improving timing and algorithm performance while minimizing the risk of out-of-memory (OOM) errors. We implemented and evaluated R^3 extensively across various DRL frameworks and benchmarks on three hardware platforms commonly adopted by autonomous robotic systems. Additionally, we integrate R^3 with a popular realistic autonomous car simulator to demonstrate its real-world applicability. Evaluation results show that R^3 achieves efficacy across diverse platforms, ensuring consistent latency performance and timing predictability with minimal overhead.