 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCollaborative Learning in Agentic Systems: A Collective AI is Greater Than the Sum of Its Parts
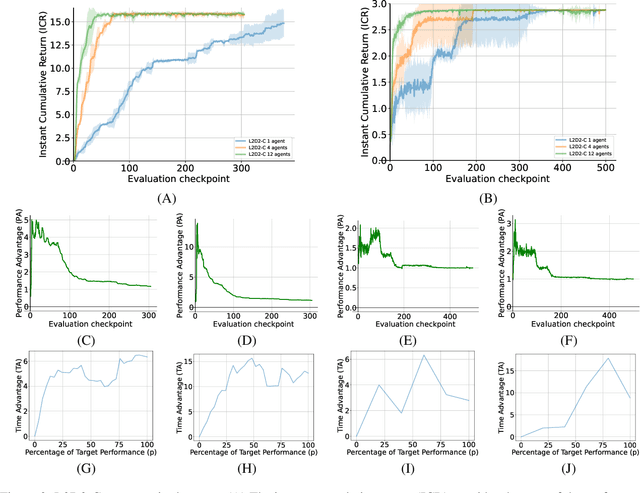
Jun 05, 2025Agentic AI has gained significant interest as a research paradigm focused on autonomy, self-directed learning, and long-term reliability of decision making. Real-world agentic systems operate in decentralized settings on a large set of tasks or data distributions with constraints such as limited bandwidth, asynchronous execution, and the absence of a centralized model or even common objectives. We posit that exploiting previously learned skills, task similarities, and communication capabilities in a collective of agentic AI are challenging but essential elements to enabling scalability, open-endedness, and beneficial collaborative learning dynamics. In this paper, we introduce Modular Sharing and Composition in Collective Learning (MOSAIC), an agentic algorithm that allows multiple agents to independently solve different tasks while also identifying, sharing, and reusing useful machine-learned knowledge, without coordination, synchronization, or centralized control. MOSAIC combines three mechanisms: (1) modular policy composition via neural network masks, (2) cosine similarity estimation using Wasserstein embeddings for knowledge selection, and (3) asynchronous communication and policy integration. Results on a set of RL benchmarks show that MOSAIC has a greater sample efficiency than isolated learners, i.e., it learns significantly faster, and in some cases, finds solutions to tasks that cannot be solved by isolated learners. The collaborative learning and sharing dynamics are also observed to result in the emergence of ideal curricula of tasks, from easy to hard. These findings support the case for collaborative learning in agentic systems to achieve better and continuously evolving performance both at the individual and collective levels.
Synaptic Modulation using Interspike Intervals Increases Energy Efficiency of Spiking Neural Networks
Aug 06, 2024


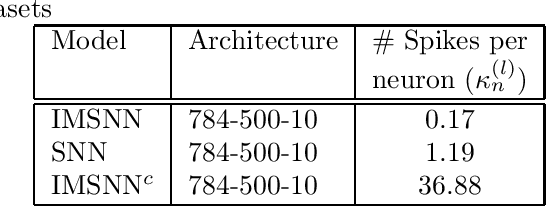
Despite basic differences between Spiking Neural Networks (SNN) and Artificial Neural Networks (ANN), most research on SNNs involve adapting ANN-based methods for SNNs. Pruning (dropping connections) and quantization (reducing precision) are often used to improve energy efficiency of SNNs. These methods are very effective for ANNs whose energy needs are determined by signals transmitted on synapses. However, the event-driven paradigm in SNNs implies that energy is consumed by spikes. In this paper, we propose a new synapse model whose weights are modulated by Interspike Intervals (ISI) i.e. time difference between two spikes. SNNs composed of this synapse model, termed ISI Modulated SNNs (IMSNN), can use gradient descent to estimate how the ISI of a neuron changes after updating its synaptic parameters. A higher ISI implies fewer spikes and vice-versa. The learning algorithm for IMSNNs exploits this information to selectively propagate gradients such that learning is achieved by increasing the ISIs resulting in a network that generates fewer spikes. The performance of IMSNNs with dense and convolutional layers have been evaluated in terms of classification accuracy and the number of spikes using the MNIST and FashionMNIST datasets. The performance comparison with conventional SNNs shows that IMSNNs exhibit upto 90% reduction in the number of spikes while maintaining similar classification accuracy.
Statistical Context Detection for Deep Lifelong Reinforcement Learning
May 29, 2024Context detection involves labeling segments of an online stream of data as belonging to different tasks. Task labels are used in lifelong learning algorithms to perform consolidation or other procedures that prevent catastrophic forgetting. Inferring task labels from online experiences remains a challenging problem. Most approaches assume finite and low-dimension observation spaces or a preliminary training phase during which task labels are learned. Moreover, changes in the transition or reward functions can be detected only in combination with a policy, and therefore are more difficult to detect than changes in the input distribution. This paper presents an approach to learning both policies and labels in an online deep reinforcement learning setting. The key idea is to use distance metrics, obtained via optimal transport methods, i.e., Wasserstein distance, on suitable latent action-reward spaces to measure distances between sets of data points from past and current streams. Such distances can then be used for statistical tests based on an adapted Kolmogorov-Smirnov calculation to assign labels to sequences of experiences. A rollback procedure is introduced to learn multiple policies by ensuring that only the appropriate data is used to train the corresponding policy. The combination of task detection and policy deployment allows for the optimization of lifelong reinforcement learning agents without an oracle that provides task labels. The approach is tested using two benchmarks and the results show promising performance when compared with related context detection algorithms. The results suggest that optimal transport statistical methods provide an explainable and justifiable procedure for online context detection and reward optimization in lifelong reinforcement learning.
R^3: On-device Real-Time Deep Reinforcement Learning for Autonomous Robotics
Sep 15, 2023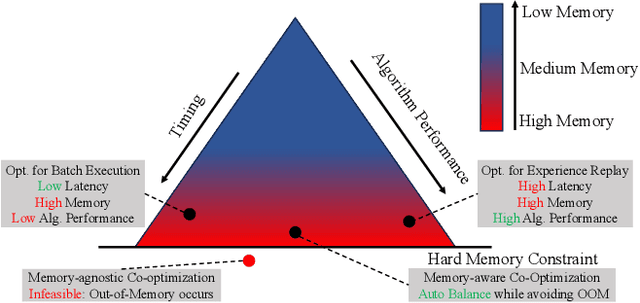

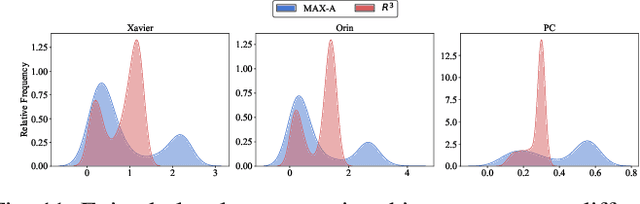
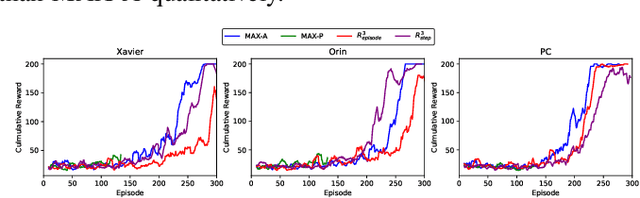
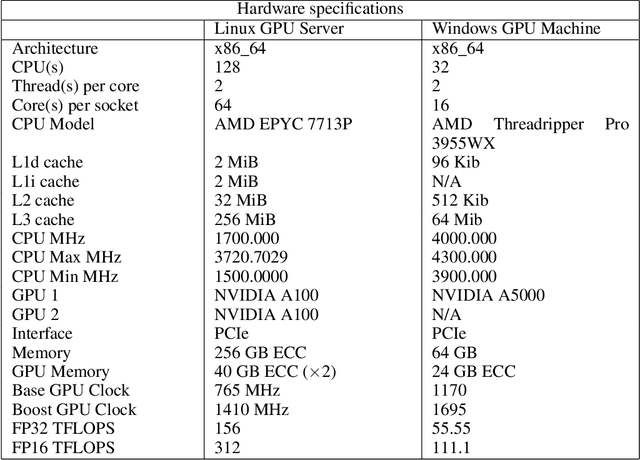
Autonomous robotic systems, like autonomous vehicles and robotic search and rescue, require efficient on-device training for continuous adaptation of Deep Reinforcement Learning (DRL) models in dynamic environments. This research is fundamentally motivated by the need to understand and address the challenges of on-device real-time DRL, which involves balancing timing and algorithm performance under memory constraints, as exposed through our extensive empirical studies. This intricate balance requires co-optimizing two pivotal parameters of DRL training -- batch size and replay buffer size. Configuring these parameters significantly affects timing and algorithm performance, while both (unfortunately) require substantial memory allocation to achieve near-optimal performance. This paper presents R^3, a holistic solution for managing timing, memory, and algorithm performance in on-device real-time DRL training. R^3 employs (i) a deadline-driven feedback loop with dynamic batch sizing for optimizing timing, (ii) efficient memory management to reduce memory footprint and allow larger replay buffer sizes, and (iii) a runtime coordinator guided by heuristic analysis and a runtime profiler for dynamically adjusting memory resource reservations. These components collaboratively tackle the trade-offs in on-device DRL training, improving timing and algorithm performance while minimizing the risk of out-of-memory (OOM) errors. We implemented and evaluated R^3 extensively across various DRL frameworks and benchmarks on three hardware platforms commonly adopted by autonomous robotic systems. Additionally, we integrate R^3 with a popular realistic autonomous car simulator to demonstrate its real-world applicability. Evaluation results show that R^3 achieves efficacy across diverse platforms, ensuring consistent latency performance and timing predictability with minimal overhead.
Sharing Lifelong Reinforcement Learning Knowledge via Modulating Masks
May 18, 2023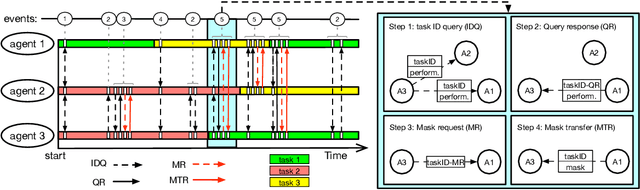
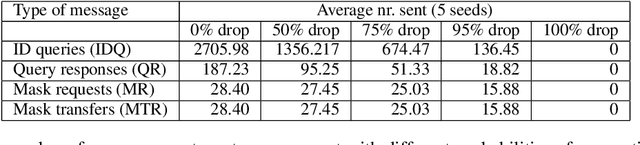
Lifelong learning agents aim to learn multiple tasks sequentially over a lifetime. This involves the ability to exploit previous knowledge when learning new tasks and to avoid forgetting. Modulating masks, a specific type of parameter isolation approach, have recently shown promise in both supervised and reinforcement learning. While lifelong learning algorithms have been investigated mainly within a single-agent approach, a question remains on how multiple agents can share lifelong learning knowledge with each other. We show that the parameter isolation mechanism used by modulating masks is particularly suitable for exchanging knowledge among agents in a distributed and decentralized system of lifelong learners. The key idea is that the isolation of specific task knowledge to specific masks allows agents to transfer only specific knowledge on-demand, resulting in robust and effective distributed lifelong learning. We assume fully distributed and asynchronous scenarios with dynamic agent numbers and connectivity. An on-demand communication protocol ensures agents query their peers for specific masks to be transferred and integrated into their policies when facing each task. Experiments indicate that on-demand mask communication is an effective way to implement distributed lifelong reinforcement learning and provides a lifelong learning benefit with respect to distributed RL baselines such as DD-PPO, IMPALA, and PPO+EWC. The system is particularly robust to connection drops and demonstrates rapid learning due to knowledge exchange.
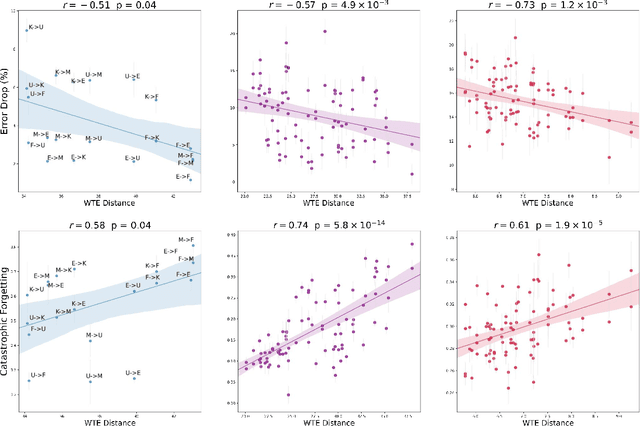
A Domain-Agnostic Approach for Characterization of Lifelong Learning Systems
Jan 18, 2023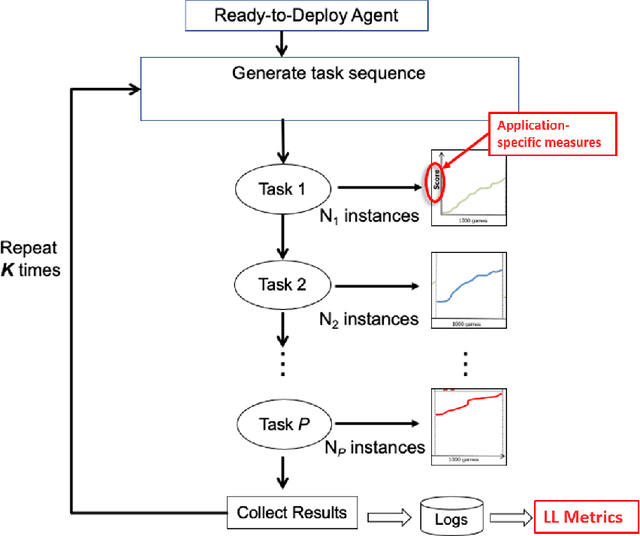
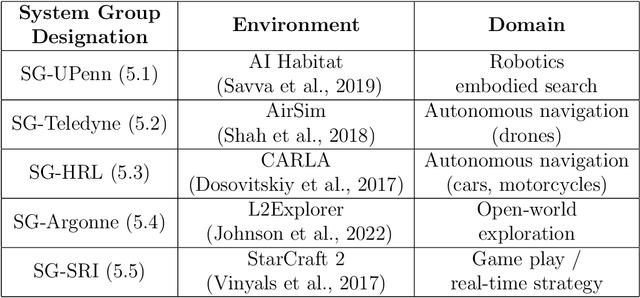


Despite the advancement of machine learning techniques in recent years, state-of-the-art systems lack robustness to "real world" events, where the input distributions and tasks encountered by the deployed systems will not be limited to the original training context, and systems will instead need to adapt to novel distributions and tasks while deployed. This critical gap may be addressed through the development of "Lifelong Learning" systems that are capable of 1) Continuous Learning, 2) Transfer and Adaptation, and 3) Scalability. Unfortunately, efforts to improve these capabilities are typically treated as distinct areas of research that are assessed independently, without regard to the impact of each separate capability on other aspects of the system. We instead propose a holistic approach, using a suite of metrics and an evaluation framework to assess Lifelong Learning in a principled way that is agnostic to specific domains or system techniques. Through five case studies, we show that this suite of metrics can inform the development of varied and complex Lifelong Learning systems. We highlight how the proposed suite of metrics quantifies performance trade-offs present during Lifelong Learning system development - both the widely discussed Stability-Plasticity dilemma and the newly proposed relationship between Sample Efficient and Robust Learning. Further, we make recommendations for the formulation and use of metrics to guide the continuing development of Lifelong Learning systems and assess their progress in the future.
Lifelong Reinforcement Learning with Modulating Masks
Dec 21, 2022Lifelong learning aims to create AI systems that continuously and incrementally learn during a lifetime, similar to biological learning. Attempts so far have met problems, including catastrophic forgetting, interference among tasks, and the inability to exploit previous knowledge. While considerable research has focused on learning multiple input distributions, typically in classification, lifelong reinforcement learning (LRL) must also deal with variations in the state and transition distributions, and in the reward functions. Modulating masks, recently developed for classification, are particularly suitable to deal with such a large spectrum of task variations. In this paper, we adapted modulating masks to work with deep LRL, specifically PPO and IMPALA agents. The comparison with LRL baselines in both discrete and continuous RL tasks shows competitive performance. We further investigated the use of a linear combination of previously learned masks to exploit previous knowledge when learning new tasks: not only is learning faster, the algorithm solves tasks that we could not otherwise solve from scratch due to extremely sparse rewards. The results suggest that RL with modulating masks is a promising approach to lifelong learning, to the composition of knowledge to learn increasingly complex tasks, and to knowledge reuse for efficient and faster learning.
Wasserstein Task Embedding for Measuring Task Similarities
Aug 24, 2022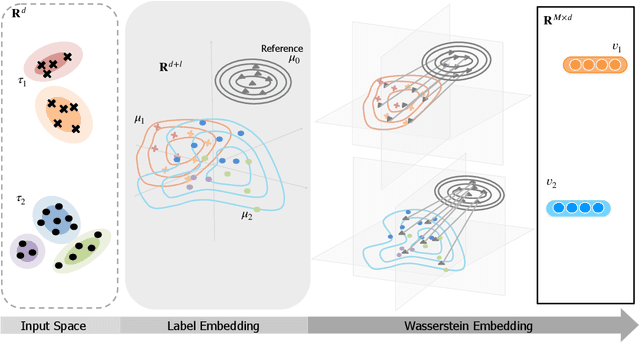
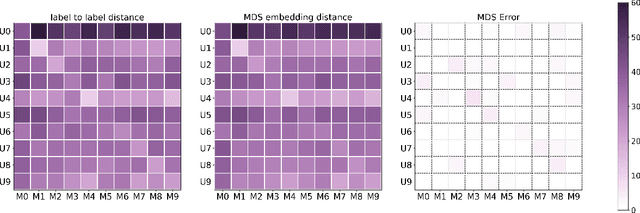
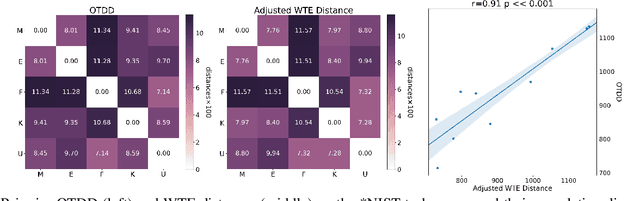
Measuring similarities between different tasks is critical in a broad spectrum of machine learning problems, including transfer, multi-task, continual, and meta-learning. Most current approaches to measuring task similarities are architecture-dependent: 1) relying on pre-trained models, or 2) training networks on tasks and using forward transfer as a proxy for task similarity. In this paper, we leverage the optimal transport theory and define a novel task embedding for supervised classification that is model-agnostic, training-free, and capable of handling (partially) disjoint label sets. In short, given a dataset with ground-truth labels, we perform a label embedding through multi-dimensional scaling and concatenate dataset samples with their corresponding label embeddings. Then, we define the distance between two datasets as the 2-Wasserstein distance between their updated samples. Lastly, we leverage the 2-Wasserstein embedding framework to embed tasks into a vector space in which the Euclidean distance between the embedded points approximates the proposed 2-Wasserstein distance between tasks. We show that the proposed embedding leads to a significantly faster comparison of tasks compared to related approaches like the Optimal Transport Dataset Distance (OTDD). Furthermore, we demonstrate the effectiveness of our proposed embedding through various numerical experiments and show statistically significant correlations between our proposed distance and the forward and backward transfer between tasks.
SLOSH: Set LOcality Sensitive Hashing via Sliced-Wasserstein Embeddings
Dec 11, 2021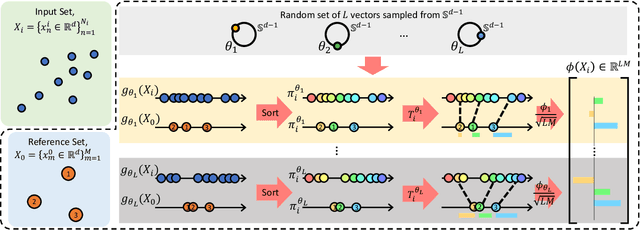

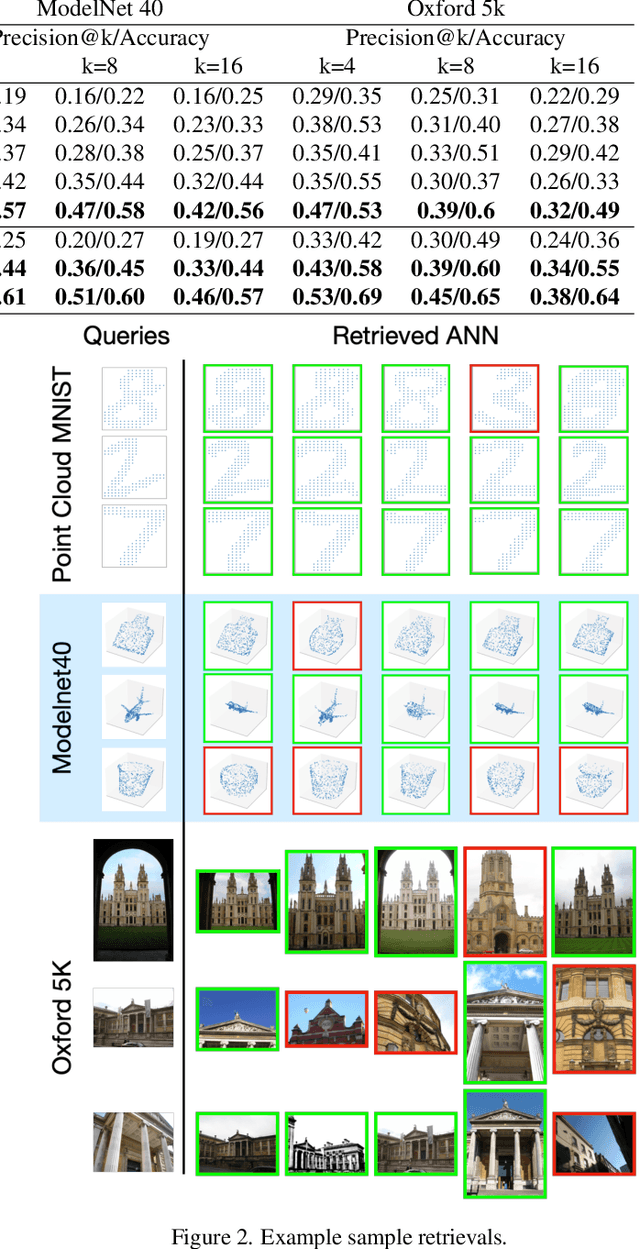
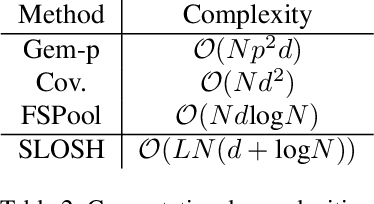
Learning from set-structured data is an essential problem with many applications in machine learning and computer vision. This paper focuses on non-parametric and data-independent learning from set-structured data using approximate nearest neighbor (ANN) solutions, particularly locality-sensitive hashing. We consider the problem of set retrieval from an input set query. Such retrieval problem requires: 1) an efficient mechanism to calculate the distances/dissimilarities between sets, and 2) an appropriate data structure for fast nearest neighbor search. To that end, we propose Sliced-Wasserstein set embedding as a computationally efficient "set-2-vector" mechanism that enables downstream ANN, with theoretical guarantees. The set elements are treated as samples from an unknown underlying distribution, and the Sliced-Wasserstein distance is used to compare sets. We demonstrate the effectiveness of our algorithm, denoted as Set-LOcality Sensitive Hashing (SLOSH), on various set retrieval datasets and compare our proposed embedding with standard set embedding approaches, including Generalized Mean (GeM) embedding/pooling, Featurewise Sort Pooling (FSPool), and Covariance Pooling and show consistent improvement in retrieval results. The code for replicating our results is available here: \href{https://github.com/mint-vu/SLOSH}{https://github.com/mint-vu/SLOSH}.
Context Meta-Reinforcement Learning via Neuromodulation
Oct 30, 2021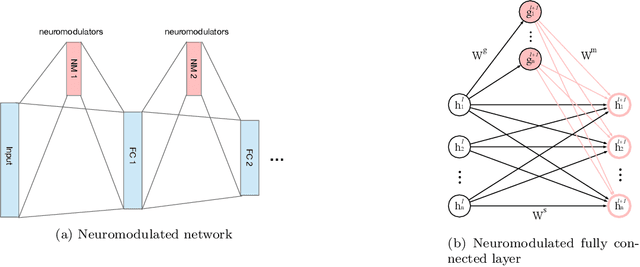
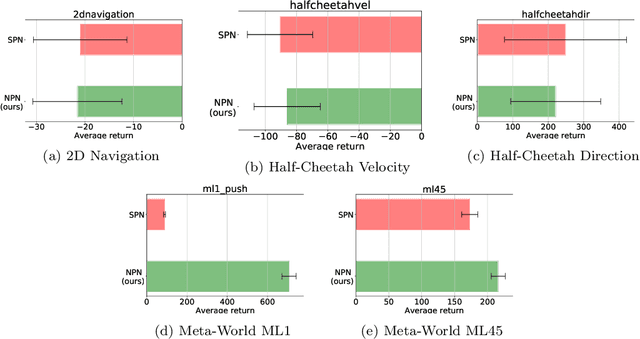
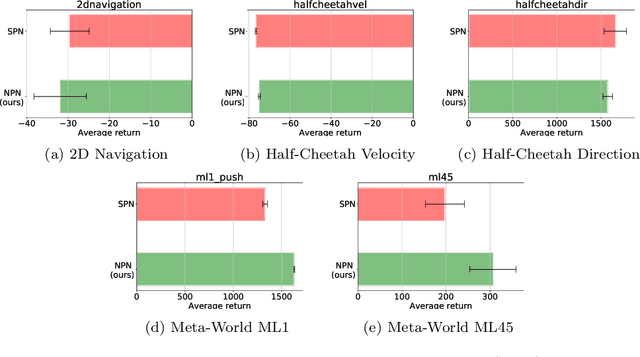

Meta-reinforcement learning (meta-RL) algorithms enable agents to adapt quickly to tasks from few samples in dynamic environments. Such a feat is achieved through dynamic representations in an agent's policy network (obtained via reasoning about task context, model parameter updates, or both). However, obtaining rich dynamic representations for fast adaptation beyond simple benchmark problems is challenging due to the burden placed on the policy network to accommodate different policies. This paper addresses the challenge by introducing neuromodulation as a modular component to augment a standard policy network that regulates neuronal activities in order to produce efficient dynamic representations for task adaptation. The proposed extension to the policy network is evaluated across multiple discrete and continuous control environments of increasing complexity. To prove the generality and benefits of the extension in meta-RL, the neuromodulated network was applied to two state-of-the-art meta-RL algorithms (CAVIA and PEARL). The result demonstrates that meta-RL augmented with neuromodulation produces significantly better result and richer dynamic representations in comparison to the baselines.