 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSharing Lifelong Reinforcement Learning Knowledge via Modulating Masks
May 18, 2023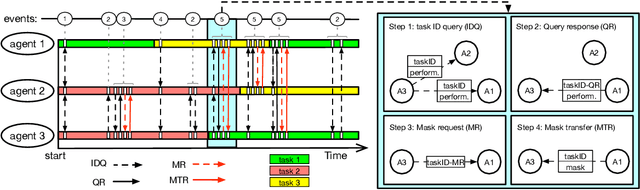
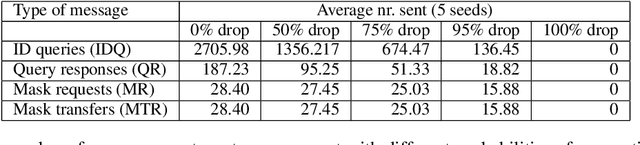
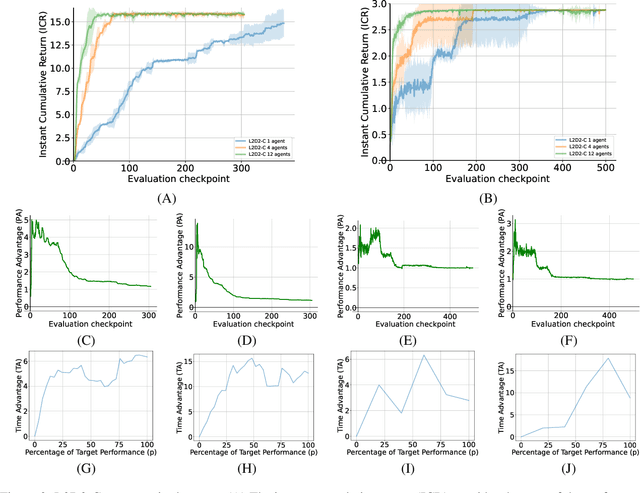
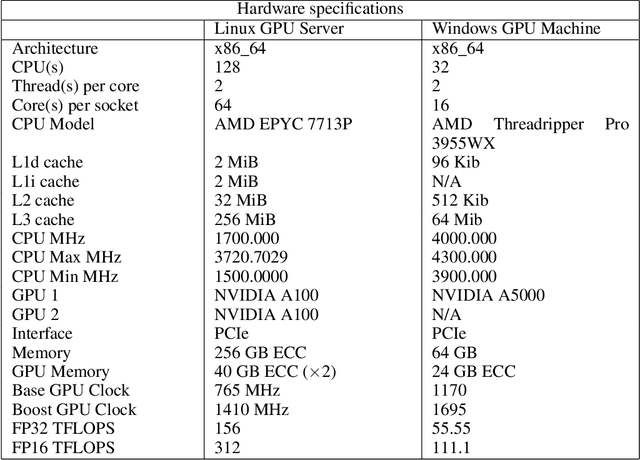
Lifelong learning agents aim to learn multiple tasks sequentially over a lifetime. This involves the ability to exploit previous knowledge when learning new tasks and to avoid forgetting. Modulating masks, a specific type of parameter isolation approach, have recently shown promise in both supervised and reinforcement learning. While lifelong learning algorithms have been investigated mainly within a single-agent approach, a question remains on how multiple agents can share lifelong learning knowledge with each other. We show that the parameter isolation mechanism used by modulating masks is particularly suitable for exchanging knowledge among agents in a distributed and decentralized system of lifelong learners. The key idea is that the isolation of specific task knowledge to specific masks allows agents to transfer only specific knowledge on-demand, resulting in robust and effective distributed lifelong learning. We assume fully distributed and asynchronous scenarios with dynamic agent numbers and connectivity. An on-demand communication protocol ensures agents query their peers for specific masks to be transferred and integrated into their policies when facing each task. Experiments indicate that on-demand mask communication is an effective way to implement distributed lifelong reinforcement learning and provides a lifelong learning benefit with respect to distributed RL baselines such as DD-PPO, IMPALA, and PPO+EWC. The system is particularly robust to connection drops and demonstrates rapid learning due to knowledge exchange.
Lifelong Reinforcement Learning with Modulating Masks
Dec 21, 2022Lifelong learning aims to create AI systems that continuously and incrementally learn during a lifetime, similar to biological learning. Attempts so far have met problems, including catastrophic forgetting, interference among tasks, and the inability to exploit previous knowledge. While considerable research has focused on learning multiple input distributions, typically in classification, lifelong reinforcement learning (LRL) must also deal with variations in the state and transition distributions, and in the reward functions. Modulating masks, recently developed for classification, are particularly suitable to deal with such a large spectrum of task variations. In this paper, we adapted modulating masks to work with deep LRL, specifically PPO and IMPALA agents. The comparison with LRL baselines in both discrete and continuous RL tasks shows competitive performance. We further investigated the use of a linear combination of previously learned masks to exploit previous knowledge when learning new tasks: not only is learning faster, the algorithm solves tasks that we could not otherwise solve from scratch due to extremely sparse rewards. The results suggest that RL with modulating masks is a promising approach to lifelong learning, to the composition of knowledge to learn increasingly complex tasks, and to knowledge reuse for efficient and faster learning.
Context Meta-Reinforcement Learning via Neuromodulation
Oct 30, 2021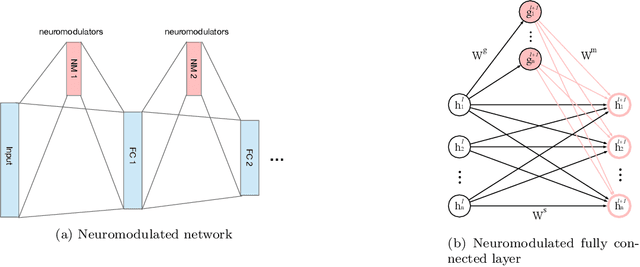
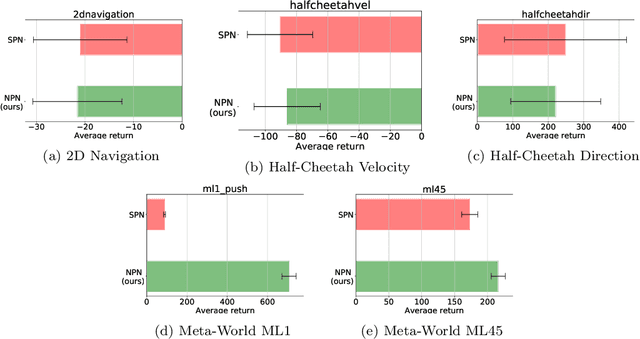
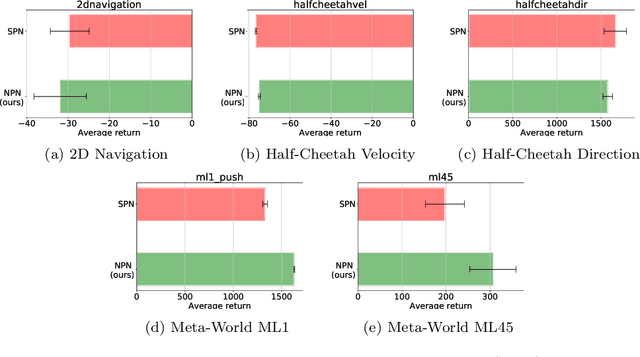

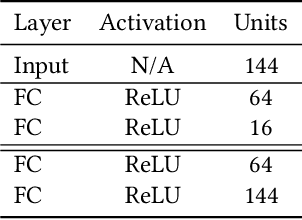
Meta-reinforcement learning (meta-RL) algorithms enable agents to adapt quickly to tasks from few samples in dynamic environments. Such a feat is achieved through dynamic representations in an agent's policy network (obtained via reasoning about task context, model parameter updates, or both). However, obtaining rich dynamic representations for fast adaptation beyond simple benchmark problems is challenging due to the burden placed on the policy network to accommodate different policies. This paper addresses the challenge by introducing neuromodulation as a modular component to augment a standard policy network that regulates neuronal activities in order to produce efficient dynamic representations for task adaptation. The proposed extension to the policy network is evaluated across multiple discrete and continuous control environments of increasing complexity. To prove the generality and benefits of the extension in meta-RL, the neuromodulated network was applied to two state-of-the-art meta-RL algorithms (CAVIA and PEARL). The result demonstrates that meta-RL augmented with neuromodulation produces significantly better result and richer dynamic representations in comparison to the baselines.
Evolving Inborn Knowledge For Fast Adaptation in Dynamic POMDP Problems
Apr 28, 2020
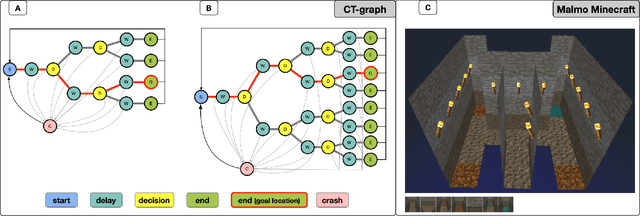
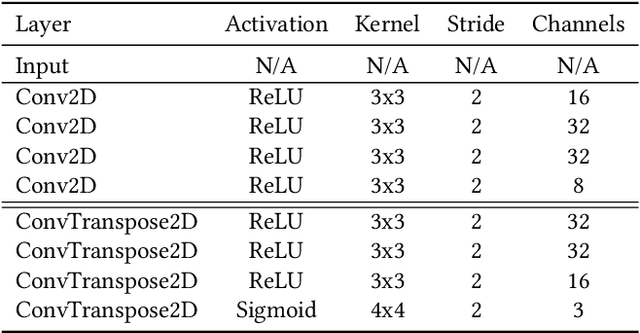
Rapid online adaptation to changing tasks is an important problem in machine learning and, recently, a focus of meta-reinforcement learning. However, reinforcement learning (RL) algorithms struggle in POMDP environments because the state of the system, essential in a RL framework, is not always visible. Additionally, hand-designed meta-RL architectures may not include suitable computational structures for specific learning problems. The evolution of online learning mechanisms, on the contrary, has the ability to incorporate learning strategies into an agent that can (i) evolve memory when required and (ii) optimize adaptation speed to specific online learning problems. In this paper, we exploit the highly adaptive nature of neuromodulated neural networks to evolve a controller that uses the latent space of an autoencoder in a POMDP. The analysis of the evolved networks reveals the ability of the proposed algorithm to acquire inborn knowledge in a variety of aspects such as the detection of cues that reveal implicit rewards, and the ability to evolve location neurons that help with navigation. The integration of inborn knowledge and online plasticity enabled fast adaptation and better performance in comparison to some non-evolutionary meta-reinforcement learning algorithms. The algorithm proved also to succeed in the 3D gaming environment Malmo Minecraft.
Deep Reinforcement Learning with Modulated Hebbian plus Q Network Architecture
Sep 21, 2019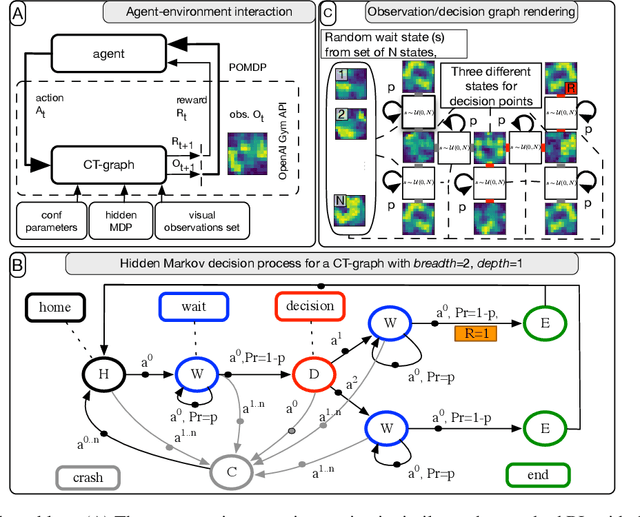
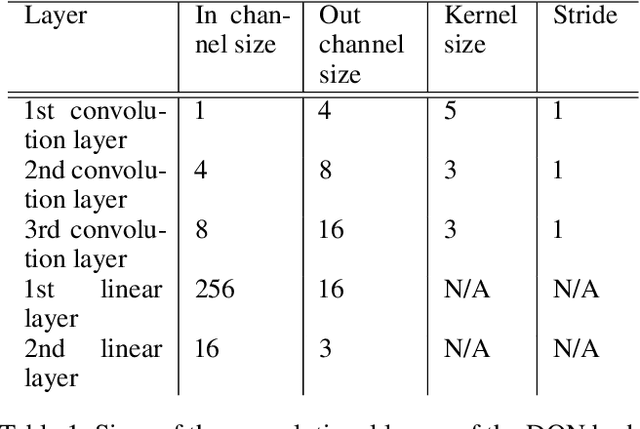
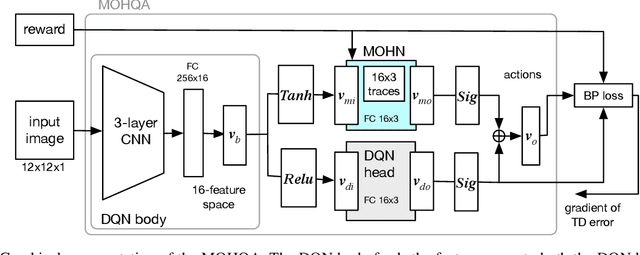
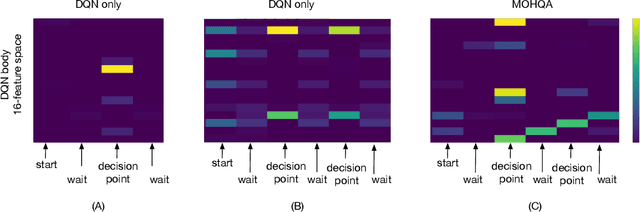
This paper introduces the modulated Hebbian plus Q network architecture (MOHQA) for solving challenging partially observable Markov decision processes (POMDPs) deep reinforcement learning problems with sparse rewards and confounding observations. The proposed architecture combines a deep Q-network (DQN), and a modulated Hebbian network with neural eligibility traces (MOHN). Bio-inspired neural traces are used to bridge temporal delays between actions and rewards. The purpose is to discover distal cause-effect relationships where confounding observations and sparse rewards cause standard RL algorithms to fail. Each of the two modules of the network (DQN and MOHN) is responsible for different aspects of learning. DQN learns low level features and control, while MOHN contributes to the high-level decisions by bridging rewards with past actions. The strength of the approach is to support a DQN standard framework when temporal difference errors are difficult to compute due to non-observable states. The system is tested on a set of generalized decision making problems encoded as decision tree graphs that deliver delayed rewards after key decision points and confounding observations. The simulations show that the proposed approach helps solve problems that are currently challenging for state-of-the-art deep reinforcement learning algorithms.