 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCollaborative Learning in Agentic Systems: A Collective AI is Greater Than the Sum of Its Parts
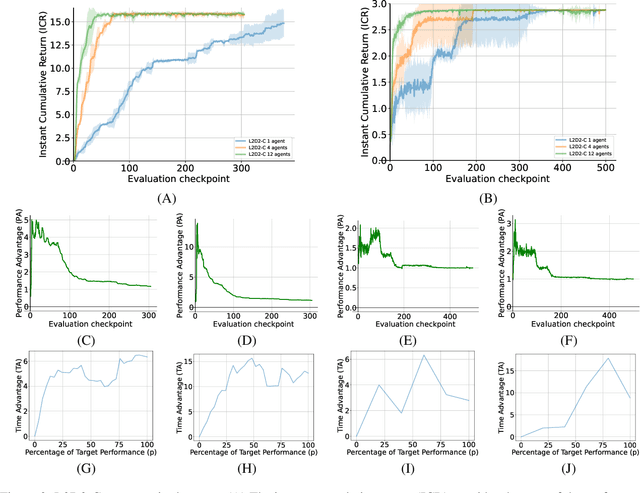
Jun 05, 2025Agentic AI has gained significant interest as a research paradigm focused on autonomy, self-directed learning, and long-term reliability of decision making. Real-world agentic systems operate in decentralized settings on a large set of tasks or data distributions with constraints such as limited bandwidth, asynchronous execution, and the absence of a centralized model or even common objectives. We posit that exploiting previously learned skills, task similarities, and communication capabilities in a collective of agentic AI are challenging but essential elements to enabling scalability, open-endedness, and beneficial collaborative learning dynamics. In this paper, we introduce Modular Sharing and Composition in Collective Learning (MOSAIC), an agentic algorithm that allows multiple agents to independently solve different tasks while also identifying, sharing, and reusing useful machine-learned knowledge, without coordination, synchronization, or centralized control. MOSAIC combines three mechanisms: (1) modular policy composition via neural network masks, (2) cosine similarity estimation using Wasserstein embeddings for knowledge selection, and (3) asynchronous communication and policy integration. Results on a set of RL benchmarks show that MOSAIC has a greater sample efficiency than isolated learners, i.e., it learns significantly faster, and in some cases, finds solutions to tasks that cannot be solved by isolated learners. The collaborative learning and sharing dynamics are also observed to result in the emergence of ideal curricula of tasks, from easy to hard. These findings support the case for collaborative learning in agentic systems to achieve better and continuously evolving performance both at the individual and collective levels.
Statistical Context Detection for Deep Lifelong Reinforcement Learning
May 29, 2024Context detection involves labeling segments of an online stream of data as belonging to different tasks. Task labels are used in lifelong learning algorithms to perform consolidation or other procedures that prevent catastrophic forgetting. Inferring task labels from online experiences remains a challenging problem. Most approaches assume finite and low-dimension observation spaces or a preliminary training phase during which task labels are learned. Moreover, changes in the transition or reward functions can be detected only in combination with a policy, and therefore are more difficult to detect than changes in the input distribution. This paper presents an approach to learning both policies and labels in an online deep reinforcement learning setting. The key idea is to use distance metrics, obtained via optimal transport methods, i.e., Wasserstein distance, on suitable latent action-reward spaces to measure distances between sets of data points from past and current streams. Such distances can then be used for statistical tests based on an adapted Kolmogorov-Smirnov calculation to assign labels to sequences of experiences. A rollback procedure is introduced to learn multiple policies by ensuring that only the appropriate data is used to train the corresponding policy. The combination of task detection and policy deployment allows for the optimization of lifelong reinforcement learning agents without an oracle that provides task labels. The approach is tested using two benchmarks and the results show promising performance when compared with related context detection algorithms. The results suggest that optimal transport statistical methods provide an explainable and justifiable procedure for online context detection and reward optimization in lifelong reinforcement learning.
Sharing Lifelong Reinforcement Learning Knowledge via Modulating Masks
May 18, 2023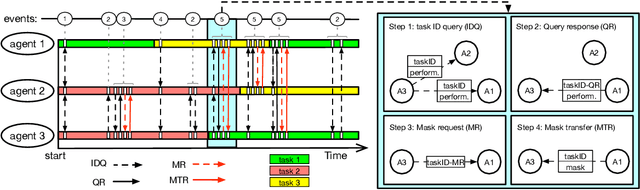
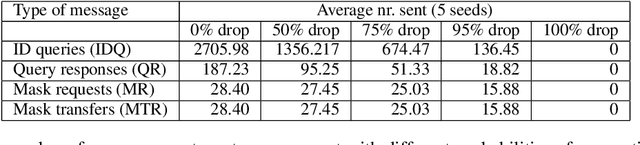
Lifelong learning agents aim to learn multiple tasks sequentially over a lifetime. This involves the ability to exploit previous knowledge when learning new tasks and to avoid forgetting. Modulating masks, a specific type of parameter isolation approach, have recently shown promise in both supervised and reinforcement learning. While lifelong learning algorithms have been investigated mainly within a single-agent approach, a question remains on how multiple agents can share lifelong learning knowledge with each other. We show that the parameter isolation mechanism used by modulating masks is particularly suitable for exchanging knowledge among agents in a distributed and decentralized system of lifelong learners. The key idea is that the isolation of specific task knowledge to specific masks allows agents to transfer only specific knowledge on-demand, resulting in robust and effective distributed lifelong learning. We assume fully distributed and asynchronous scenarios with dynamic agent numbers and connectivity. An on-demand communication protocol ensures agents query their peers for specific masks to be transferred and integrated into their policies when facing each task. Experiments indicate that on-demand mask communication is an effective way to implement distributed lifelong reinforcement learning and provides a lifelong learning benefit with respect to distributed RL baselines such as DD-PPO, IMPALA, and PPO+EWC. The system is particularly robust to connection drops and demonstrates rapid learning due to knowledge exchange.