 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructBreak: Structural Cognitive Overload-Induced Safety Failures in MLLMs
May 25, 2026Multimodal Large Language Models (MLLMs) excel at structural reasoning yet suffer from a sharp logical brittleness in structural consistency. We term this phenomenon Structural Cognitive Overload (SCO), a byproduct of the contention between deep reasoning and safety alignment. However, prior work has predominantly targeted typographic and pixel-level perturbations, leaving the study of SCO largely unexplored. To this end, we propose StructBreak, an automated end-to-end framework designed to quantify SCO. By leveraging StructBreak, we uncover a novel higher-order cognitive overload attack paradigm; notably, this attack operates under a practical black-box setting, requiring no internal model access. Consequently, we utilize this framework to establish a comprehensive benchmark spanning ten diverse threat scenarios. Empirical evaluations on six leading MLLMs reveal that SCO readily triggers toxic generation, yielding a 92% average ASR (up to 97% on Gemini 2.5). To elucidate the mechanism of SCO, we further conduct model-level interpretations spanning attention dynamics, latent space topology, and geometric analysis. Our findings reveal that StructBreak acts as a novel structural channel to circumvent safety filters. Furthermore, the limited efficacy of inherent safety mechanisms underscores that current alignment paradigms are insufficient for the era of complex multimodal reasoning.
Min Generalized Sliced Gromov Wasserstein: A Scalable Path to Gromov Wasserstein
May 13, 2026We propose min Generalized Sliced Gromov--Wasserstein (min-GSGW), a sliced formulation for the Gromov--Wasserstein (GW) problem using expressive generalized slicers. The key idea is to learn coupled nonlinear slicers that assign compatible push-forward values to both input measures, so that monotone coupling in the projected domain lifts to a transport plan evaluated against the GW objective in the original spaces. The resulting plan induces a GW objective value, and min-GSGW minimizes this cost directly in the original spaces. We further show that min-GSGW is rigid-motion invariant, a crucial property for geometric matching and shape analysis tasks. Our contributions are threefold: 1) we introduce generalized slicers into the sliced GW framework, 2) we construct a slicing-based efficient GW transport plan; and 3) we develop an amortized variant that replaces per-instance optimization with a learned slicer for unseen input pairs. We perform experiments on animal mesh matching, horse mesh interpolation, and ShapeNet part transfer. Results show that min-GSGW produces meaningful geometric correspondences and GW objective values at substantially lower computational cost than existing GW solvers.
GhostCite: A Large-Scale Analysis of Citation Validity in the Age of Large Language Models
Feb 06, 2026Citations provide the basis for trusting scientific claims; when they are invalid or fabricated, this trust collapses. With the advent of Large Language Models (LLMs), this risk has intensified: LLMs are increasingly used for academic writing, yet their tendency to fabricate citations (``ghost citations'') poses a systemic threat to citation validity. To quantify this threat and inform mitigation, we develop CiteVerifier, an open-source framework for large-scale citation verification, and conduct the first comprehensive study of citation validity in the LLM era through three experiments built on it. We benchmark 13 state-of-the-art LLMs on citation generation across 40 research domains, finding that all models hallucinate citations at rates from 14.23\% to 94.93\%, with significant variation across research domains. Moreover, we analyze 2.2 million citations from 56,381 papers published at top-tier AI/ML and Security venues (2020--2025), confirming that 1.07\% of papers contain invalid or fabricated citations (604 papers), with an 80.9\% increase in 2025 alone. Furthermore, we survey 97 researchers and analyze 94 valid responses after removing 3 conflicting samples, revealing a critical ``verification gap'': 41.5\% of researchers copy-paste BibTeX without checking and 44.4\% choose no-action responses when encountering suspicious references; meanwhile, 76.7\% of reviewers do not thoroughly check references and 80.0\% never suspect fake citations. Our findings reveal an accelerating crisis where unreliable AI tools, combined with inadequate human verification by researchers and insufficient peer review scrutiny, enable fabricated citations to contaminate the scientific record. We propose interventions for researchers, venues, and tool developers to protect citation integrity.
AsarRec: Adaptive Sequential Augmentation for Robust Self-supervised Sequential Recommendation
Dec 16, 2025
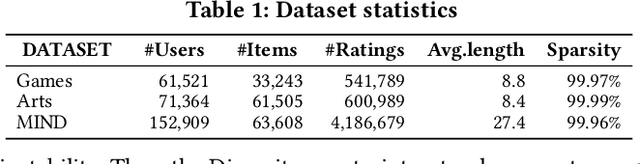


Sequential recommender systems have demonstrated strong capabilities in modeling users' dynamic preferences and capturing item transition patterns. However, real-world user behaviors are often noisy due to factors such as human errors, uncertainty, and behavioral ambiguity, which can lead to degraded recommendation performance. To address this issue, recent approaches widely adopt self-supervised learning (SSL), particularly contrastive learning, by generating perturbed views of user interaction sequences and maximizing their mutual information to improve model robustness. However, these methods heavily rely on their pre-defined static augmentation strategies~(where the augmentation type remains fixed once chosen) to construct augmented views, leading to two critical challenges: (1) the optimal augmentation type can vary significantly across different scenarios; (2) inappropriate augmentations may even degrade recommendation performance, limiting the effectiveness of SSL. To overcome these limitations, we propose an adaptive augmentation framework. We first unify existing basic augmentation operations into a unified formulation via structured transformation matrices. Building on this, we introduce AsarRec (Adaptive Sequential Augmentation for Robust Sequential Recommendation), which learns to generate transformation matrices by encoding user sequences into probabilistic transition matrices and projecting them into hard semi-doubly stochastic matrices via a differentiable Semi-Sinkhorn algorithm. To ensure that the learned augmentations benefit downstream performance, we jointly optimize three objectives: diversity, semantic invariance, and informativeness. Extensive experiments on three benchmark datasets under varying noise levels validate the effectiveness of AsarRec, demonstrating its superior robustness and consistent improvements.
LUNA: Linear Universal Neural Attention with Generalization Guarantees
Dec 08, 2025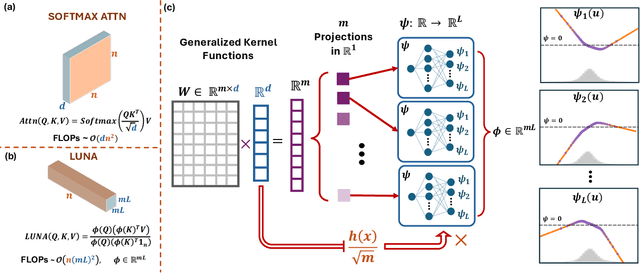
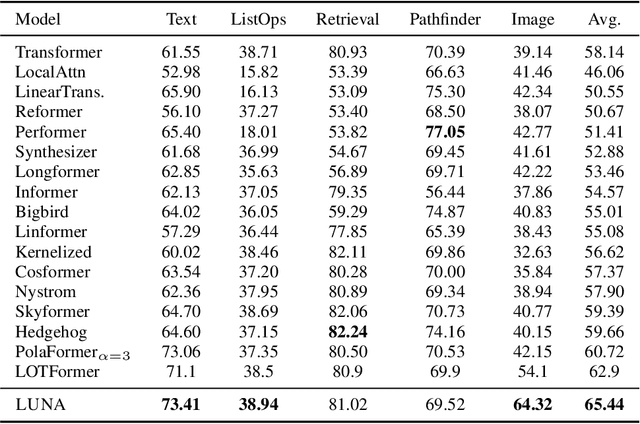
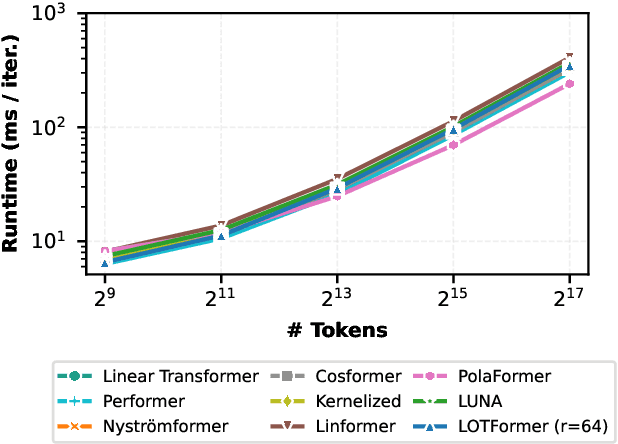
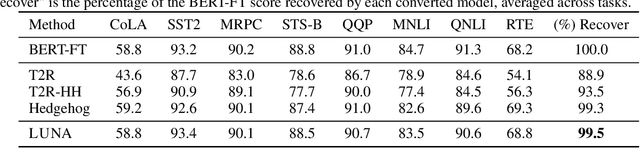
Scaling attention faces a critical bottleneck: the $\mathcal{O}(n^2)$ quadratic computational cost of softmax attention, which limits its application in long-sequence domains. While linear attention mechanisms reduce this cost to $\mathcal{O}(n)$, they typically rely on fixed random feature maps, such as random Fourier features or hand-crafted functions. This reliance on static, data-agnostic kernels creates a fundamental trade-off, forcing practitioners to sacrifice significant model accuracy for computational efficiency. We introduce \textsc{LUNA}, a kernelized linear attention mechanism that eliminates this trade-off, retaining linear cost while matching and surpassing the accuracy of quadratic attention. \textsc{LUNA} is built on the key insight that the kernel feature map itself should be learned rather than fixed a priori. By parameterizing the kernel, \textsc{LUNA} learns a feature basis tailored to the specific data and task, overcoming the expressive limitations of fixed-feature methods. \textsc{Luna} implements this with a learnable feature map that induces a positive-definite kernel and admits a streaming form, yielding linear time and memory scaling in the sequence length. Empirical evaluations validate our approach across diverse settings. On the Long Range Arena (LRA), \textsc{Luna} achieves state-of-the-art average accuracy among efficient Transformers under compute parity, using the same parameter count, training steps, and approximate FLOPs. \textsc{Luna} also excels at post-hoc conversion: replacing softmax in fine-tuned BERT and ViT-B/16 checkpoints and briefly fine-tuning recovers most of the original performance, substantially outperforming fixed linearizations.
Driving by Hybrid Navigation: An Online HD-SD Map Association Framework and Benchmark for Autonomous Vehicles
Jul 10, 2025



Autonomous vehicles rely on global standard-definition (SD) maps for road-level route planning and online local high-definition (HD) maps for lane-level navigation. However, recent work concentrates on construct online HD maps, often overlooking the association of global SD maps with online HD maps for hybrid navigation, making challenges in utilizing online HD maps in the real world. Observing the lack of the capability of autonomous vehicles in navigation, we introduce \textbf{O}nline \textbf{M}ap \textbf{A}ssociation, the first benchmark for the association of hybrid navigation-oriented online maps, which enhances the planning capabilities of autonomous vehicles. Based on existing datasets, the OMA contains 480k of roads and 260k of lane paths and provides the corresponding metrics to evaluate the performance of the model. Additionally, we propose a novel framework, named Map Association Transformer, as the baseline method, using path-aware attention and spatial attention mechanisms to enable the understanding of geometric and topological correspondences. The code and dataset can be accessed at https://github.com/WallelWan/OMA-MAT.
Collaborative Learning in Agentic Systems: A Collective AI is Greater Than the Sum of Its Parts
Jun 05, 2025Agentic AI has gained significant interest as a research paradigm focused on autonomy, self-directed learning, and long-term reliability of decision making. Real-world agentic systems operate in decentralized settings on a large set of tasks or data distributions with constraints such as limited bandwidth, asynchronous execution, and the absence of a centralized model or even common objectives. We posit that exploiting previously learned skills, task similarities, and communication capabilities in a collective of agentic AI are challenging but essential elements to enabling scalability, open-endedness, and beneficial collaborative learning dynamics. In this paper, we introduce Modular Sharing and Composition in Collective Learning (MOSAIC), an agentic algorithm that allows multiple agents to independently solve different tasks while also identifying, sharing, and reusing useful machine-learned knowledge, without coordination, synchronization, or centralized control. MOSAIC combines three mechanisms: (1) modular policy composition via neural network masks, (2) cosine similarity estimation using Wasserstein embeddings for knowledge selection, and (3) asynchronous communication and policy integration. Results on a set of RL benchmarks show that MOSAIC has a greater sample efficiency than isolated learners, i.e., it learns significantly faster, and in some cases, finds solutions to tasks that cannot be solved by isolated learners. The collaborative learning and sharing dynamics are also observed to result in the emergence of ideal curricula of tasks, from easy to hard. These findings support the case for collaborative learning in agentic systems to achieve better and continuously evolving performance both at the individual and collective levels.
FutureSightDrive: Thinking Visually with Spatio-Temporal CoT for Autonomous Driving
May 23, 2025Visual language models (VLMs) have attracted increasing interest in autonomous driving due to their powerful reasoning capabilities. However, existing VLMs typically utilize discrete text Chain-of-Thought (CoT) tailored to the current scenario, which essentially represents highly abstract and symbolic compression of visual information, potentially leading to spatio-temporal relationship ambiguity and fine-grained information loss. Is autonomous driving better modeled on real-world simulation and imagination than on pure symbolic logic? In this paper, we propose a spatio-temporal CoT reasoning method that enables models to think visually. First, VLM serves as a world model to generate unified image frame for predicting future world states: where perception results (e.g., lane divider and 3D detection) represent the future spatial relationships, and ordinary future frame represent the temporal evolution relationships. This spatio-temporal CoT then serves as intermediate reasoning steps, enabling the VLM to function as an inverse dynamics model for trajectory planning based on current observations and future predictions. To implement visual generation in VLMs, we propose a unified pretraining paradigm integrating visual generation and understanding, along with a progressive visual CoT enhancing autoregressive image generation. Extensive experimental results demonstrate the effectiveness of the proposed method, advancing autonomous driving towards visual reasoning.
Accelerated Quasi-Static FEM for Real-Time Modeling of Continuum Robots with Multiple Contacts and Large Deformation
Mar 10, 2025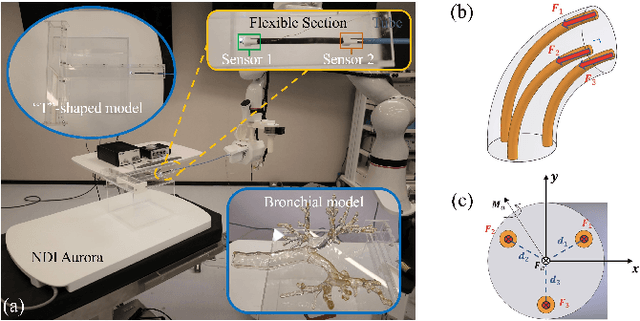
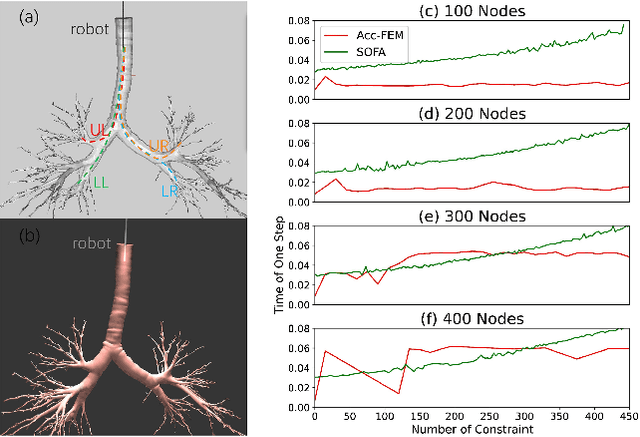
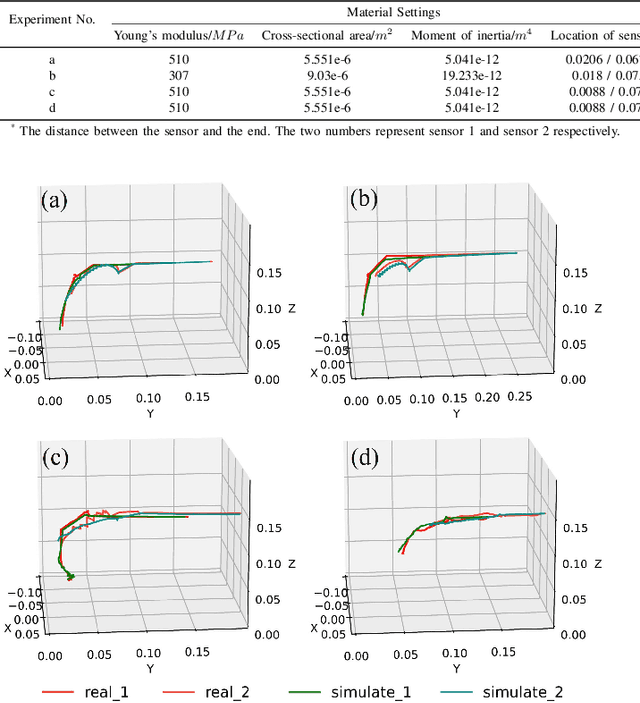

Continuum robots offer high flexibility and multiple degrees of freedom, making them ideal for navigating narrow lumens. However, accurately modeling their behavior under large deformations and frequent environmental contacts remains challenging. Current methods for solving the deformation of these robots, such as the Model Order Reduction and Gauss-Seidel (GS) methods, suffer from significant drawbacks. They experience reduced computational speed as the number of contact points increases and struggle to balance speed with model accuracy. To overcome these limitations, we introduce a novel finite element method (FEM) named Acc-FEM. Acc-FEM employs a large deformation quasi-static finite element model and integrates an accelerated solver scheme to handle multi-contact simulations efficiently. Additionally, it utilizes parallel computing with Graphics Processing Units (GPU) for real-time updates of the finite element models and collision detection. Extensive numerical experiments demonstrate that Acc-FEM significantly improves computational efficiency in modeling continuum robots with multiple contacts while achieving satisfactory accuracy, addressing the deficiencies of existing methods.
DGFM: Full Body Dance Generation Driven by Music Foundation Models
Feb 27, 2025In music-driven dance motion generation, most existing methods use hand-crafted features and neglect that music foundation models have profoundly impacted cross-modal content generation. To bridge this gap, we propose a diffusion-based method that generates dance movements conditioned on text and music. Our approach extracts music features by combining high-level features obtained by music foundation model with hand-crafted features, thereby enhancing the quality of generated dance sequences. This method effectively leverages the advantages of high-level semantic information and low-level temporal details to improve the model's capability in music feature understanding. To show the merits of the proposed method, we compare it with four music foundation models and two sets of hand-crafted music features. The results demonstrate that our method obtains the most realistic dance sequences and achieves the best match with the input music.