 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCollaborative Learning in Agentic Systems: A Collective AI is Greater Than the Sum of Its Parts
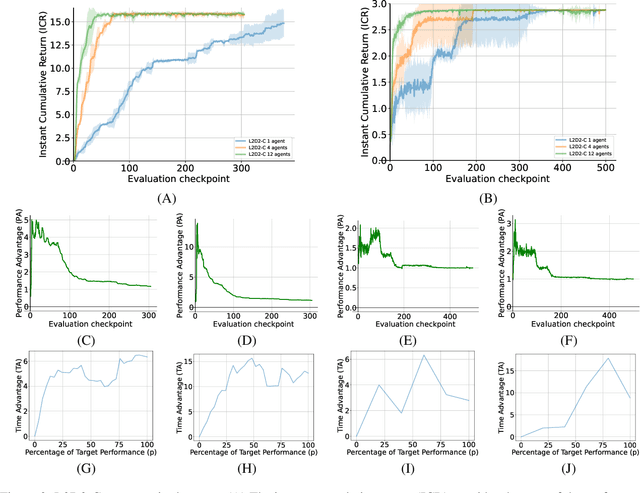
Jun 05, 2025Agentic AI has gained significant interest as a research paradigm focused on autonomy, self-directed learning, and long-term reliability of decision making. Real-world agentic systems operate in decentralized settings on a large set of tasks or data distributions with constraints such as limited bandwidth, asynchronous execution, and the absence of a centralized model or even common objectives. We posit that exploiting previously learned skills, task similarities, and communication capabilities in a collective of agentic AI are challenging but essential elements to enabling scalability, open-endedness, and beneficial collaborative learning dynamics. In this paper, we introduce Modular Sharing and Composition in Collective Learning (MOSAIC), an agentic algorithm that allows multiple agents to independently solve different tasks while also identifying, sharing, and reusing useful machine-learned knowledge, without coordination, synchronization, or centralized control. MOSAIC combines three mechanisms: (1) modular policy composition via neural network masks, (2) cosine similarity estimation using Wasserstein embeddings for knowledge selection, and (3) asynchronous communication and policy integration. Results on a set of RL benchmarks show that MOSAIC has a greater sample efficiency than isolated learners, i.e., it learns significantly faster, and in some cases, finds solutions to tasks that cannot be solved by isolated learners. The collaborative learning and sharing dynamics are also observed to result in the emergence of ideal curricula of tasks, from easy to hard. These findings support the case for collaborative learning in agentic systems to achieve better and continuously evolving performance both at the individual and collective levels.
Synaptic Modulation using Interspike Intervals Increases Energy Efficiency of Spiking Neural Networks
Aug 06, 2024


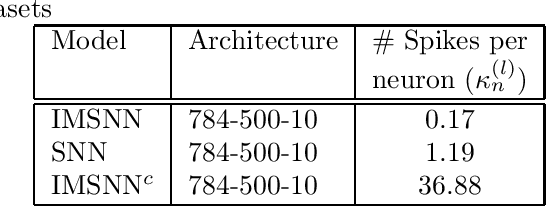
Despite basic differences between Spiking Neural Networks (SNN) and Artificial Neural Networks (ANN), most research on SNNs involve adapting ANN-based methods for SNNs. Pruning (dropping connections) and quantization (reducing precision) are often used to improve energy efficiency of SNNs. These methods are very effective for ANNs whose energy needs are determined by signals transmitted on synapses. However, the event-driven paradigm in SNNs implies that energy is consumed by spikes. In this paper, we propose a new synapse model whose weights are modulated by Interspike Intervals (ISI) i.e. time difference between two spikes. SNNs composed of this synapse model, termed ISI Modulated SNNs (IMSNN), can use gradient descent to estimate how the ISI of a neuron changes after updating its synaptic parameters. A higher ISI implies fewer spikes and vice-versa. The learning algorithm for IMSNNs exploits this information to selectively propagate gradients such that learning is achieved by increasing the ISIs resulting in a network that generates fewer spikes. The performance of IMSNNs with dense and convolutional layers have been evaluated in terms of classification accuracy and the number of spikes using the MNIST and FashionMNIST datasets. The performance comparison with conventional SNNs shows that IMSNNs exhibit upto 90% reduction in the number of spikes while maintaining similar classification accuracy.
Towards Improved Imbalance Robustness in Continual Multi-Label Learning with Dual Output Spiking Architecture (DOSA)
Feb 07, 2024Algorithms designed for addressing typical supervised classification problems can only learn from a fixed set of samples and labels, making them unsuitable for the real world, where data arrives as a stream of samples often associated with multiple labels over time. This motivates the study of task-agnostic continual multi-label learning problems. While algorithms using deep learning approaches for continual multi-label learning have been proposed in the recent literature, they tend to be computationally heavy. Although spiking neural networks (SNNs) offer a computationally efficient alternative to artificial neural networks, existing literature has not used SNNs for continual multi-label learning. Also, accurately determining multiple labels with SNNs is still an open research problem. This work proposes a dual output spiking architecture (DOSA) to bridge these research gaps. A novel imbalance-aware loss function is also proposed, improving the multi-label classification performance of the model by making it more robust to data imbalance. A modified F1 score is presented to evaluate the effectiveness of the proposed loss function in handling imbalance. Experiments on several benchmark multi-label datasets show that DOSA trained with the proposed loss function shows improved robustness to data imbalance and obtains better continual multi-label learning performance than CIFDM, a previous state-of-the-art algorithm.
Deep Predictive Coding with Bi-directional Propagation for Classification and Reconstruction
May 29, 2023This paper presents a new learning algorithm, termed Deep Bi-directional Predictive Coding (DBPC) that allows developing networks to simultaneously perform classification and reconstruction tasks using the same weights. Predictive Coding (PC) has emerged as a prominent theory underlying information processing in the brain. The general concept for learning in PC is that each layer learns to predict the activities of neurons in the previous layer which enables local computation of error and in-parallel learning across layers. In this paper, we extend existing PC approaches by developing a network which supports both feedforward and feedback propagation of information. Each layer in the networks trained using DBPC learn to predict the activities of neurons in the previous and next layer which allows the network to simultaneously perform classification and reconstruction tasks using feedforward and feedback propagation, respectively. DBPC also relies on locally available information for learning, thus enabling in-parallel learning across all layers in the network. The proposed approach has been developed for training both, fully connected networks and convolutional neural networks. The performance of DBPC has been evaluated on both, classification and reconstruction tasks using the MNIST and FashionMNIST datasets. The classification and the reconstruction performance of networks trained using DBPC is similar to other approaches used for comparison but DBPC uses a significantly smaller network. Further, the significant benefit of DBPC is its ability to achieve this performance using locally available information and in-parallel learning mechanisms which results in an efficient training protocol. This results clearly indicate that DBPC is a much more efficient approach for developing networks that can simultaneously perform both classification and reconstruction.
A Decentralized Spike-based Learning Framework for Sequential Capture in Discrete Perimeter Defense Problem
May 26, 2023



This paper proposes a novel Decentralized Spike-based Learning (DSL) framework for the discrete Perimeter Defense Problem (d-PDP). A team of defenders is operating on the perimeter to protect the circular territory from radially incoming intruders. At first, the d-PDP is formulated as a spatio-temporal multi-task assignment problem (STMTA). The problem of STMTA is then converted into a multi-label learning problem to obtain labels of segments that defenders have to visit in order to protect the perimeter. The DSL framework uses a Multi-Label Classifier using Synaptic Efficacy Function spiking neuRON (MLC-SEFRON) network for deterministic multi-label learning. Each defender contains a single MLC-SEFRON network. Each MLC-SEFRON network is trained independently using input from its own perspective for decentralized operations. The input spikes to the MLC-SEFRON network can be directly obtained from the spatio-temporal information of defenders and intruders without any extra pre-processing step. The output of MLC-SEFRON contains the labels of segments that a defender has to visit in order to protect the perimeter. Based on the multi-label output from the MLC-SEFRON a trajectory is generated for a defender using a Consensus-Based Bundle Algorithm (CBBA) in order to capture the intruders. The target multi-label output for training MLC-SEFRON is obtained from an expert policy. Also, the MLC-SEFRON trained for a defender can be directly used for obtaining labels of segments assigned to another defender without any retraining. The performance of MLC-SEFRON has been evaluated for full observation and partial observation scenarios of the defender. The overall performance of the DSL framework is then compared with expert policy along with other existing learning algorithms. The scalability of the DSL has been evaluated using an increasing number of defenders.
Sharing Lifelong Reinforcement Learning Knowledge via Modulating Masks
May 18, 2023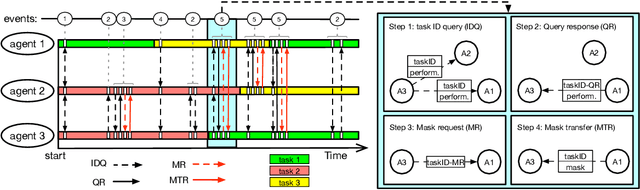
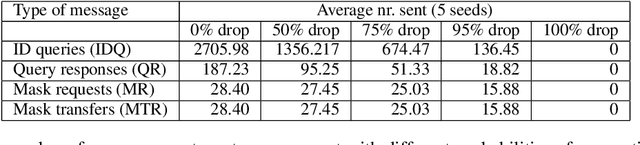
Lifelong learning agents aim to learn multiple tasks sequentially over a lifetime. This involves the ability to exploit previous knowledge when learning new tasks and to avoid forgetting. Modulating masks, a specific type of parameter isolation approach, have recently shown promise in both supervised and reinforcement learning. While lifelong learning algorithms have been investigated mainly within a single-agent approach, a question remains on how multiple agents can share lifelong learning knowledge with each other. We show that the parameter isolation mechanism used by modulating masks is particularly suitable for exchanging knowledge among agents in a distributed and decentralized system of lifelong learners. The key idea is that the isolation of specific task knowledge to specific masks allows agents to transfer only specific knowledge on-demand, resulting in robust and effective distributed lifelong learning. We assume fully distributed and asynchronous scenarios with dynamic agent numbers and connectivity. An on-demand communication protocol ensures agents query their peers for specific masks to be transferred and integrated into their policies when facing each task. Experiments indicate that on-demand mask communication is an effective way to implement distributed lifelong reinforcement learning and provides a lifelong learning benefit with respect to distributed RL baselines such as DD-PPO, IMPALA, and PPO+EWC. The system is particularly robust to connection drops and demonstrates rapid learning due to knowledge exchange.
MuPNet: Multi-modal Predictive Coding Network for Place Recognition by Unsupervised Learning of Joint Visuo-Tactile Latent Representations
Sep 16, 2019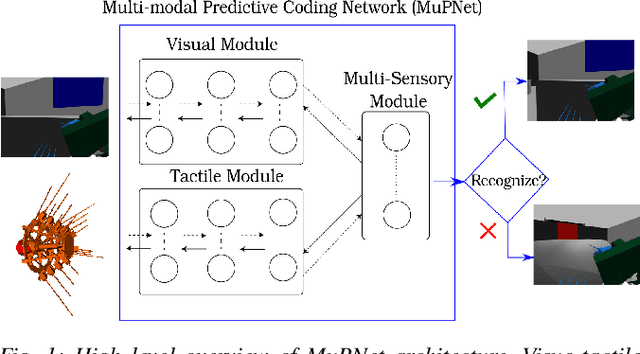
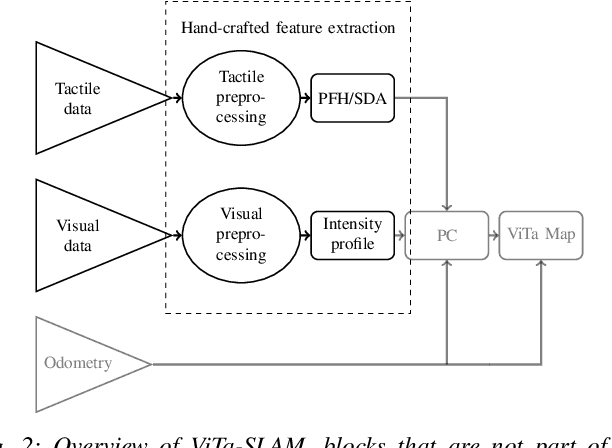

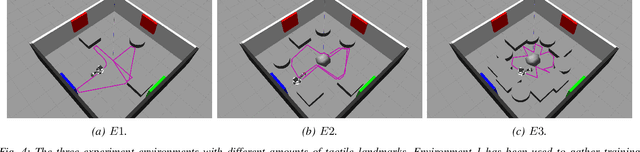
Extracting and binding salient information from different sensory modalities to determine common features in the environment is a significant challenge in robotics. Here we present MuPNet (Multi-modal Predictive Coding Network), a biologically plausible network architecture for extracting joint latent features from visuo-tactile sensory data gathered from a biomimetic mobile robot. In this study we evaluate MuPNet applied to place recognition as a simulated biomimetic robot platform explores visually aliased environments. The F1 scores demonstrate that its performance over prior hand-crafted sensory feature extraction techniques is equivalent under controlled conditions, with significant improvement when operating in novel environments.