 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeREAct: Rational Exponential Activation for Better Learning and Generalization in PINNs
Mar 04, 2025



Physics-Informed Neural Networks (PINNs) offer a promising approach to simulating physical systems. Still, their application is limited by optimization challenges, mainly due to the lack of activation functions that generalize well across several physical systems. Existing activation functions often lack such flexibility and generalization power. To address this issue, we introduce Rational Exponential Activation (REAct), a generalized form of tanh consisting of four learnable shape parameters. Experiments show that REAct outperforms many standard and benchmark activations, achieving an MSE three orders of magnitude lower than tanh on heat problems and generalizing well to finer grids and points beyond the training domain. It also excels at function approximation tasks and improves noise rejection in inverse problems, leading to more accurate parameter estimates across varying noise levels.
Towards Improved Imbalance Robustness in Continual Multi-Label Learning with Dual Output Spiking Architecture (DOSA)
Feb 07, 2024Algorithms designed for addressing typical supervised classification problems can only learn from a fixed set of samples and labels, making them unsuitable for the real world, where data arrives as a stream of samples often associated with multiple labels over time. This motivates the study of task-agnostic continual multi-label learning problems. While algorithms using deep learning approaches for continual multi-label learning have been proposed in the recent literature, they tend to be computationally heavy. Although spiking neural networks (SNNs) offer a computationally efficient alternative to artificial neural networks, existing literature has not used SNNs for continual multi-label learning. Also, accurately determining multiple labels with SNNs is still an open research problem. This work proposes a dual output spiking architecture (DOSA) to bridge these research gaps. A novel imbalance-aware loss function is also proposed, improving the multi-label classification performance of the model by making it more robust to data imbalance. A modified F1 score is presented to evaluate the effectiveness of the proposed loss function in handling imbalance. Experiments on several benchmark multi-label datasets show that DOSA trained with the proposed loss function shows improved robustness to data imbalance and obtains better continual multi-label learning performance than CIFDM, a previous state-of-the-art algorithm.
Confidence Conditioned Knowledge Distillation
Jul 06, 2021
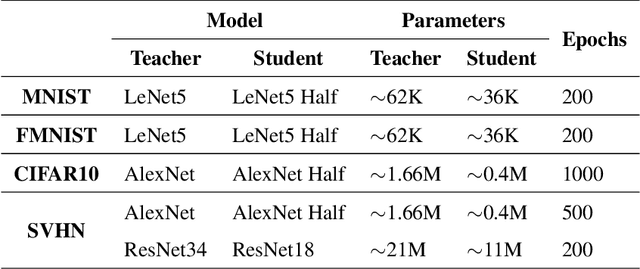
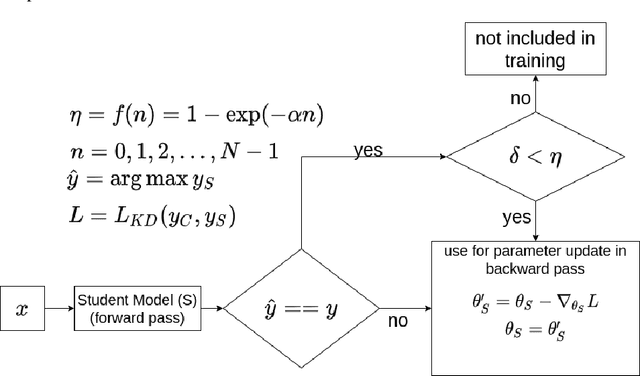
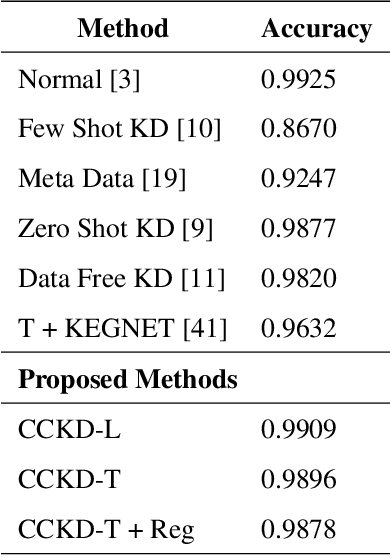
In this paper, a novel confidence conditioned knowledge distillation (CCKD) scheme for transferring the knowledge from a teacher model to a student model is proposed. Existing state-of-the-art methods employ fixed loss functions for this purpose and ignore the different levels of information that need to be transferred for different samples. In addition to that, these methods are also inefficient in terms of data usage. CCKD addresses these issues by leveraging the confidence assigned by the teacher model to the correct class to devise sample-specific loss functions (CCKD-L formulation) and targets (CCKD-T formulation). Further, CCKD improves the data efficiency by employing self-regulation to stop those samples from participating in the distillation process on which the student model learns faster. Empirical evaluations on several benchmark datasets show that CCKD methods achieve at least as much generalization performance levels as other state-of-the-art methods while being data efficient in the process. Student models trained through CCKD methods do not retain most of the misclassifications commited by the teacher model on the training set. Distillation through CCKD methods improves the resilience of the student models against adversarial attacks compared to the conventional KD method. Experiments show at least 3% increase in performance against adversarial attacks for the MNIST and the Fashion MNIST datasets, and at least 6% increase for the CIFAR10 dataset.
Self Regulated Learning Mechanism for Data Efficient Knowledge Distillation
Feb 14, 2021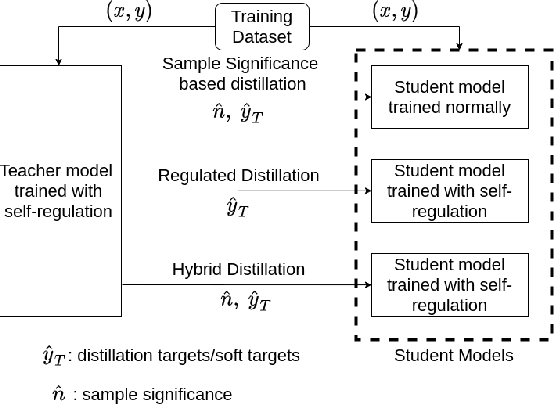
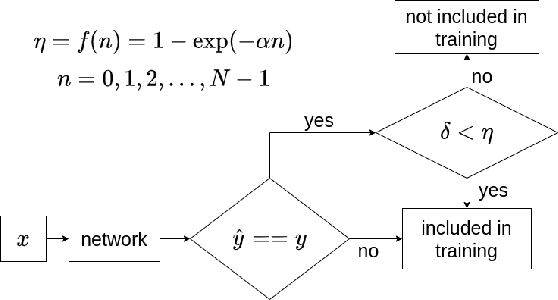
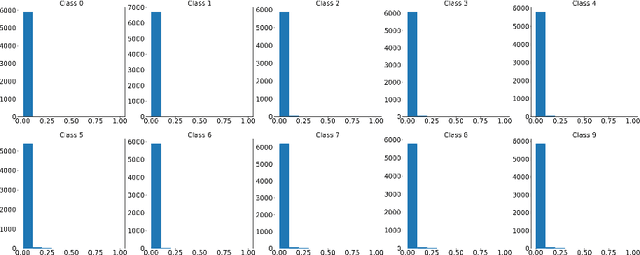
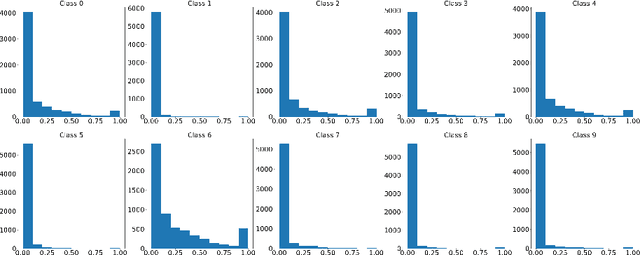
Existing methods for distillation use the conventional training approach where all samples participate equally in the process and are thus highly inefficient in terms of data utilization. In this paper, a novel data-efficient approach to transfer the knowledge from a teacher model to a student model is presented. Here, the teacher model uses self-regulation to select appropriate samples for training and identifies their significance in the process. During distillation, the significance information can be used along with the soft-targets to supervise the students. Depending on the use of self-regulation and sample significance information in supervising the knowledge transfer process, three types of distillations are proposed - significance-based, regulated, and hybrid, respectively. Experiments on benchmark datasets show that the proposed methods achieve similar performance as other state-of-the-art methods for knowledge distillation while utilizing a significantly less number of samples.
Assessing Robustness of Deep learning Methods in Dermatological Workflow
Jan 15, 2020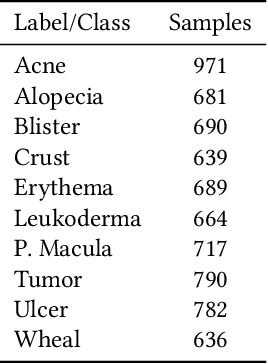
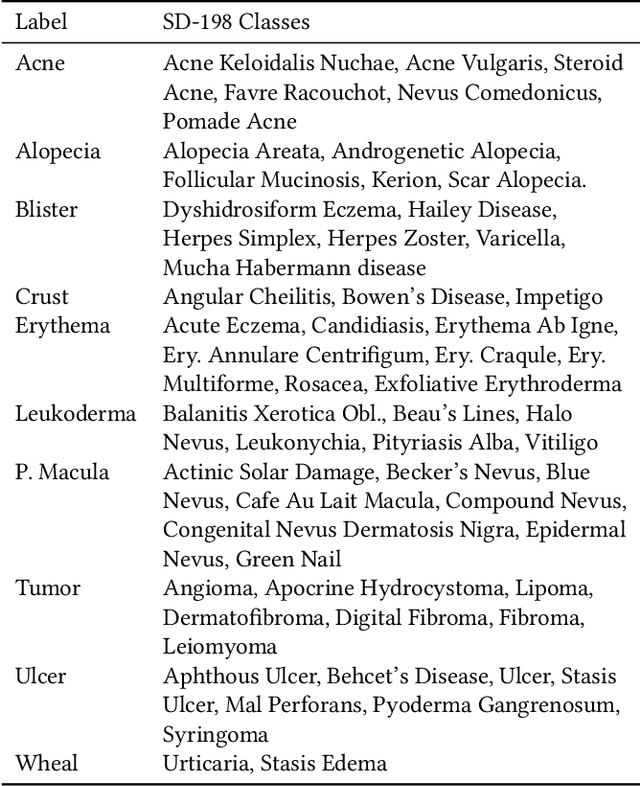
This paper aims to evaluate the suitability of current deep learning methods for clinical workflow especially by focusing on dermatology. Although deep learning methods have been attempted to get dermatologist level accuracy in several individual conditions, it has not been rigorously tested for common clinical complaints. Most projects involve data acquired in well-controlled laboratory conditions. This may not reflect regular clinical evaluation where corresponding image quality is not always ideal. We test the robustness of deep learning methods by simulating non-ideal characteristics on user submitted images of ten classes of diseases. Assessing via imitated conditions, we have found the overall accuracy to drop and individual predictions change significantly in many cases despite of robust training.
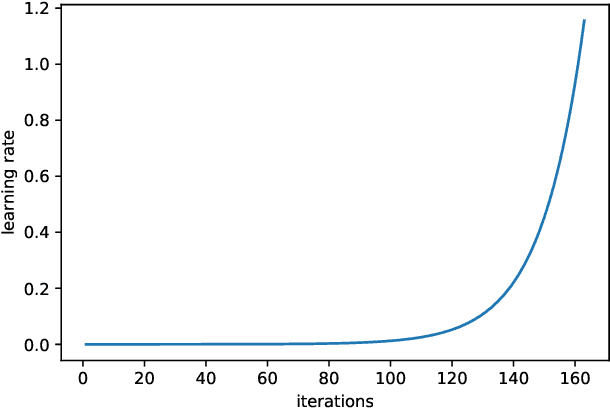
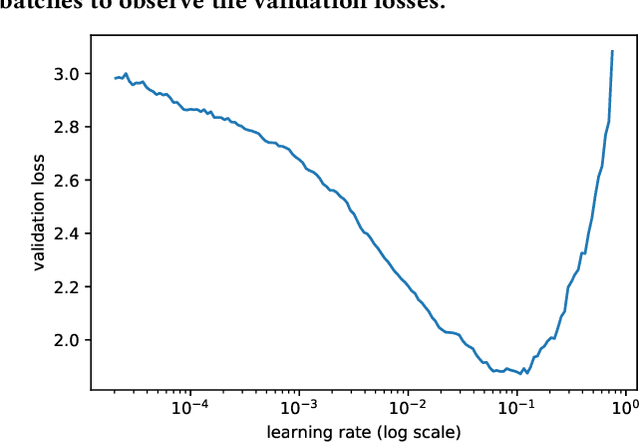
Improving image classifiers for small datasets by learning rate adaptations
Mar 27, 2019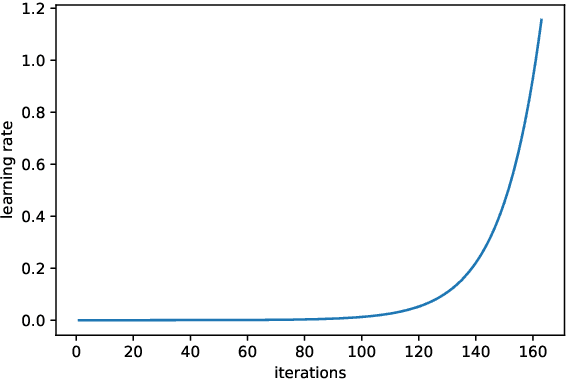

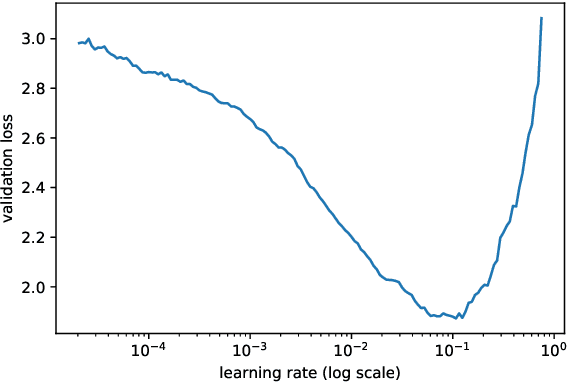

Our paper introduces an efficient combination of established techniques to improve classifier performance, in terms of accuracy and training time. We achieve two-fold to ten-fold speedup in nearing state of the art accuracy, over different model architectures, by dynamically tuning the learning rate. We find it especially beneficial in the case of a small dataset, where reliability of machine reasoning is lower. We validate our approach by comparing our method versus vanilla training on CIFAR-10. We also demonstrate its practical viability by implementing on an unbalanced corpus of diagnostic images.
Supervised classification of Dermatological diseases by Deep learning
Jul 31, 2018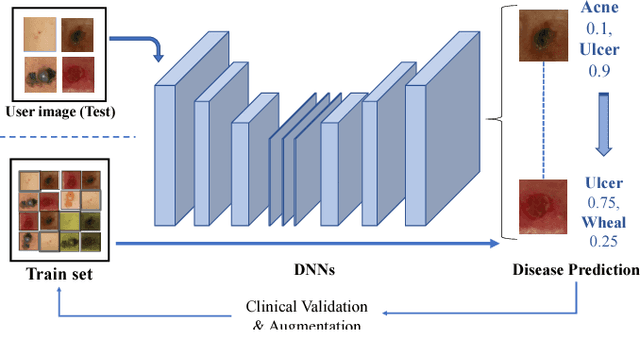
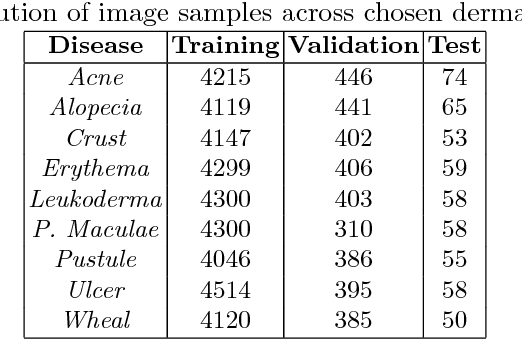

This paper introduces a deep-learning based efficient classifier for common dermatological conditions, aimed at people without easy access to skin specialists. We report approximately 80% accuracy, in a situation where primary care doctors have attained 57% success rate, according to recent literature. The rationale of its design is centered on deploying and updating it on handheld devices in near future. Dermatological diseases are common in every population and have a wide spectrum in severity. With a shortage of dermatological expertise being observed in several countries, machine learning solutions can augment medical services and advise regarding existence of common diseases. The paper implements supervised classification of nine distinct conditions which have high occurrence in East Asian countries. Our current attempt establishes that deep learning based techniques are viable avenues for preliminary information to aid patients.