 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConfidence Conditioned Knowledge Distillation
Paper and Code
Jul 06, 2021
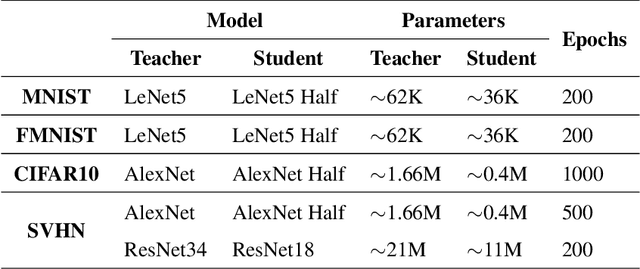
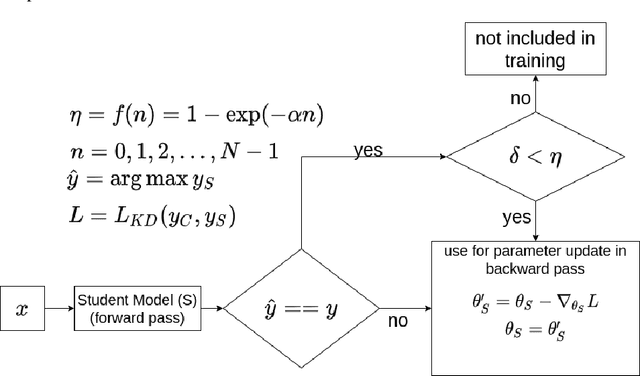
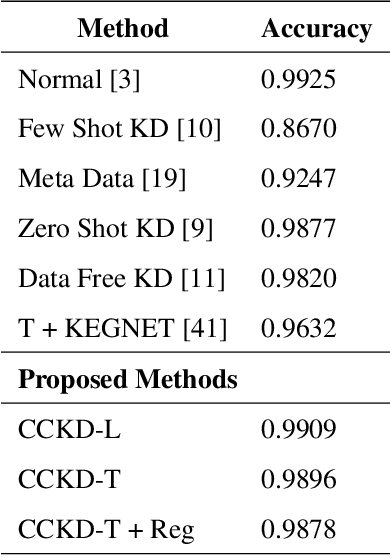
In this paper, a novel confidence conditioned knowledge distillation (CCKD) scheme for transferring the knowledge from a teacher model to a student model is proposed. Existing state-of-the-art methods employ fixed loss functions for this purpose and ignore the different levels of information that need to be transferred for different samples. In addition to that, these methods are also inefficient in terms of data usage. CCKD addresses these issues by leveraging the confidence assigned by the teacher model to the correct class to devise sample-specific loss functions (CCKD-L formulation) and targets (CCKD-T formulation). Further, CCKD improves the data efficiency by employing self-regulation to stop those samples from participating in the distillation process on which the student model learns faster. Empirical evaluations on several benchmark datasets show that CCKD methods achieve at least as much generalization performance levels as other state-of-the-art methods while being data efficient in the process. Student models trained through CCKD methods do not retain most of the misclassifications commited by the teacher model on the training set. Distillation through CCKD methods improves the resilience of the student models against adversarial attacks compared to the conventional KD method. Experiments show at least 3% increase in performance against adversarial attacks for the MNIST and the Fashion MNIST datasets, and at least 6% increase for the CIFAR10 dataset.