 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDevelopment of Domain-Invariant Visual Enhancement and Restoration (DIVER) Approach for Underwater Images
Jan 30, 2026Underwater images suffer severe degradation due to wavelength-dependent attenuation, scattering, and illumination non-uniformity that vary across water types and depths. We propose an unsupervised Domain-Invariant Visual Enhancement and Restoration (DIVER) framework that integrates empirical correction with physics-guided modeling for robust underwater image enhancement. DIVER first applies either IlluminateNet for adaptive luminance enhancement or a Spectral Equalization Filter for spectral normalization. An Adaptive Optical Correction Module then refines hue and contrast using channel-adaptive filtering, while Hydro-OpticNet employs physics-constrained learning to compensate for backscatter and wavelength-dependent attenuation. The parameters of IlluminateNet and Hydro-OpticNet are optimized via unsupervised learning using a composite loss function. DIVER is evaluated on eight diverse datasets covering shallow, deep, and highly turbid environments, including both naturally low-light and artificially illuminated scenes, using reference and non-reference metrics. While state-of-the-art methods such as WaterNet, UDNet, and Phaseformer perform reasonably in shallow water, their performance degrades in deep, unevenly illuminated, or artificially lit conditions. In contrast, DIVER consistently achieves best or near-best performance across all datasets, demonstrating strong domain-invariant capability. DIVER yields at least a 9% improvement over SOTA methods in UCIQE. On the low-light SeaThru dataset, where color-palette references enable direct evaluation of color restoration, DIVER achieves at least a 4.9% reduction in GPMAE compared to existing methods. Beyond visual quality, DIVER also improves robotic perception by enhancing ORB-based keypoint repeatability and matching performance, confirming its robustness across diverse underwater environments.
Prompt Tuning without Labeled Samples for Zero-Shot Node Classification in Text-Attributed Graphs
Jan 07, 2026Node classification is a fundamental problem in information retrieval with many real-world applications, such as community detection in social networks, grouping articles published online and product categorization in e-commerce. Zero-shot node classification in text-attributed graphs (TAGs) presents a significant challenge, particularly due to the absence of labeled data. In this paper, we propose a novel Zero-shot Prompt Tuning (ZPT) framework to address this problem by leveraging a Universal Bimodal Conditional Generator (UBCG). Our approach begins with pre-training a graph-language model to capture both the graph structure and the associated textual descriptions of each node. Following this, a conditional generative model is trained to learn the joint distribution of nodes in both graph and text modalities, enabling the generation of synthetic samples for each class based solely on the class name. These synthetic node and text embeddings are subsequently used to perform continuous prompt tuning, facilitating effective node classification in a zero-shot setting. Furthermore, we conduct extensive experiments on multiple benchmark datasets, demonstrating that our framework performs better than existing state-of-the-art baselines. We also provide ablation studies to validate the contribution of the bimodal generator. The code is provided at: https://github.com/Sethup123/ZPT.
SAGA: Semantic-Aware Gray color Augmentation for Visible-to-Thermal Domain Adaptation across Multi-View Drone and Ground-Based Vision Systems
Apr 22, 2025Domain-adaptive thermal object detection plays a key role in facilitating visible (RGB)-to-thermal (IR) adaptation by reducing the need for co-registered image pairs and minimizing reliance on large annotated IR datasets. However, inherent limitations of IR images, such as the lack of color and texture cues, pose challenges for RGB-trained models, leading to increased false positives and poor-quality pseudo-labels. To address this, we propose Semantic-Aware Gray color Augmentation (SAGA), a novel strategy for mitigating color bias and bridging the domain gap by extracting object-level features relevant to IR images. Additionally, to validate the proposed SAGA for drone imagery, we introduce the IndraEye, a multi-sensor (RGB-IR) dataset designed for diverse applications. The dataset contains 5,612 images with 145,666 instances, captured from diverse angles, altitudes, backgrounds, and times of day, offering valuable opportunities for multimodal learning, domain adaptation for object detection and segmentation, and exploration of sensor-specific strengths and weaknesses. IndraEye aims to enhance the development of more robust and accurate aerial perception systems, especially in challenging environments. Experimental results show that SAGA significantly improves RGB-to-IR adaptation for autonomous driving and IndraEye dataset, achieving consistent performance gains of +0.4% to +7.6% (mAP) when integrated with state-of-the-art domain adaptation techniques. The dataset and codes are available at https://github.com/airliisc/IndraEye.
Performance Analysis of Spatial and Temporal Learning Networks in the Presence of DVL Noise
Mar 07, 2025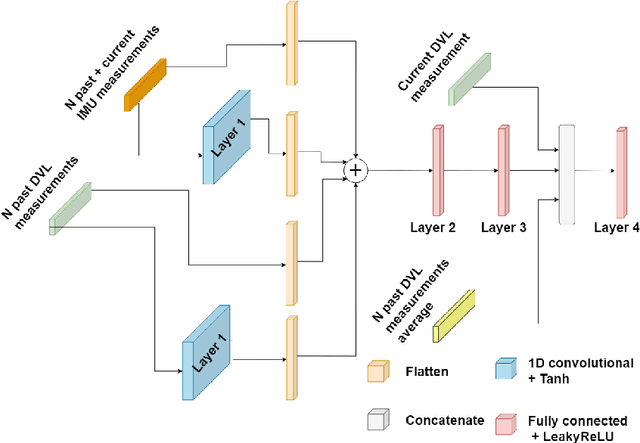
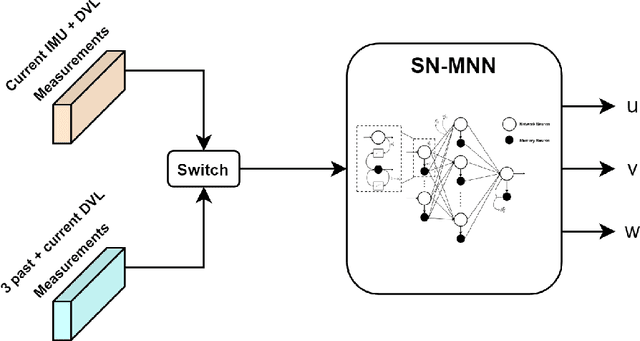
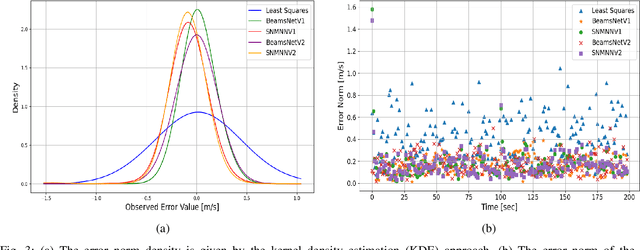

Navigation is a critical aspect of autonomous underwater vehicles (AUVs) operating in complex underwater environments. Since global navigation satellite system (GNSS) signals are unavailable underwater, navigation relies on inertial sensing, which tends to accumulate errors over time. To mitigate this, the Doppler velocity log (DVL) plays a crucial role in determining navigation accuracy. In this paper, we compare two neural network models: an adapted version of BeamsNet, based on a one-dimensional convolutional neural network, and a Spectrally Normalized Memory Neural Network (SNMNN). The former focuses on extracting spatial features, while the latter leverages memory and temporal features to provide more accurate velocity estimates while handling biased and noisy DVL data. The proposed approaches were trained and tested on real AUV data collected in the Mediterranean Sea. Both models are evaluated in terms of accuracy and estimation certainty and are benchmarked against the least squares (LS) method, the current model-based approach. The results show that the neural network models achieve over a 50% improvement in RMSE for the estimation of the AUV velocity, with a smaller standard deviation.
REAct: Rational Exponential Activation for Better Learning and Generalization in PINNs
Mar 04, 2025



Physics-Informed Neural Networks (PINNs) offer a promising approach to simulating physical systems. Still, their application is limited by optimization challenges, mainly due to the lack of activation functions that generalize well across several physical systems. Existing activation functions often lack such flexibility and generalization power. To address this issue, we introduce Rational Exponential Activation (REAct), a generalized form of tanh consisting of four learnable shape parameters. Experiments show that REAct outperforms many standard and benchmark activations, achieving an MSE three orders of magnitude lower than tanh on heat problems and generalizing well to finer grids and points beyond the training domain. It also excels at function approximation tasks and improves noise rejection in inverse problems, leading to more accurate parameter estimates across varying noise levels.
IRisPath: Enhancing Off-Road Navigation with Robust IR-RGB Fusion for Improved Day and Night Traversability
Dec 04, 2024

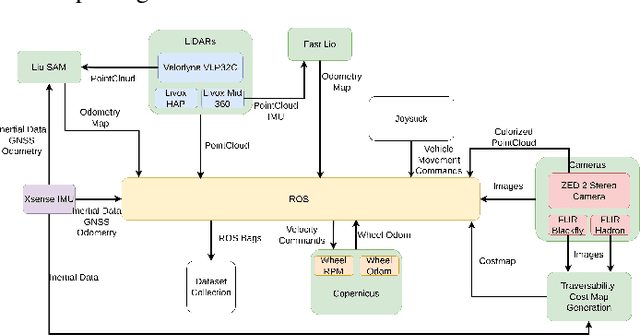

Autonomous off-road navigation is required for applications in agriculture, construction, search and rescue and defence. Traditional on-road autonomous methods struggle with dynamic terrains, leading to poor vehicle control on off-road. Recent deep-learning models have used perception sensors along with kinesthetic feedback for navigation on such terrains. However, this approach has out-of-domain uncertainty. Factors like change in weather and time of day impacts the performance of the model. We propose a multi modal fusion network FuseIsPath capable of using LWIR and RGB images to provide robustness against dynamic weather and light conditions. To aid further works in this domain, we also open-source a day-night dataset with LWIR and RGB images along with pseudo-labels for traversability. In order to co-register the two images we developed a novel method for targetless extrinsic calibration of LWIR, LiDAR and RGB cameras with translation accuracy of 1.7cm and rotation accuracy of 0.827degree.
EROAS: 3D Efficient Reactive Obstacle Avoidance System for Autonomous Underwater Vehicles using 2.5D Forward-Looking Sonar
Nov 08, 2024
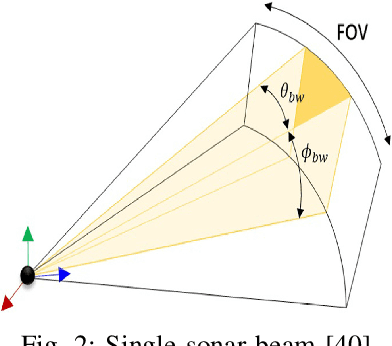
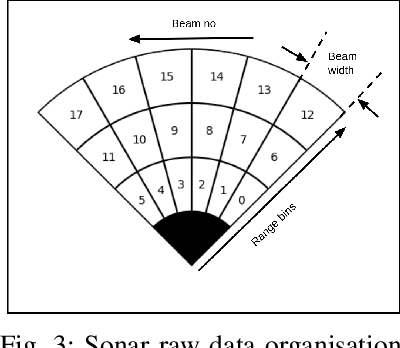
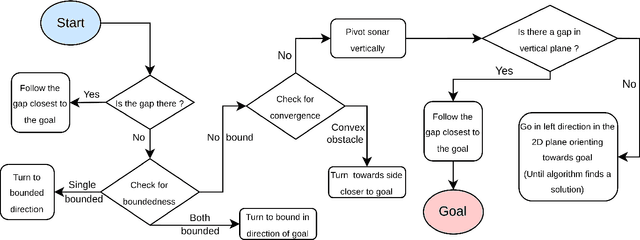
Advances in Autonomous Underwater Vehicles (AUVs) have evolved vastly in short period of time. While advancements in sonar and camera technology with deep learning aid the obstacle detection and path planning to a great extent, achieving the right balance between computational resources , precision and safety maintained remains a challenge. Finding optimal solutions for real-time navigation in cluttered environments becomes pivotal as systems have to process large amounts of data efficiently. In this work, we propose a novel obstacle avoidance method for navigating 3D underwater environments. This approach utilizes a standard multibeam forward-looking sonar to detect and map obstacle in 3D environment. Instead of using computationally expensive 3D sensors, we pivot the 2D sonar to get 3D heuristic data effectively transforming the sensor into a 2.5D sonar for real-time 3D navigation decisions. This approach enhances obstacle detection and navigation by leveraging the simplicity of 2D sonar with the depth perception typically associated with 3D systems. We have further incorporated Control Barrier Function (CBF) as a filter to ensure safety of the AUV. The effectiveness of this algorithm was tested on a six degrees of freedom (DOF) rover in various simulation scenarios. The results demonstrate that the system successfully avoids obstacles and navigates toward predefined goals, showcasing its capability to manage complex underwater environments with precision. This paper highlights the potential of 2.5D sonar for improving AUV navigation and offers insights into future enhancements and applications of this technology in underwater autonomous systems. \url{https://github.com/AIRLabIISc/EROAS}
IndraEye: Infrared Electro-Optical UAV-based Perception Dataset for Robust Downstream Tasks
Oct 28, 2024Deep neural networks (DNNs) have shown exceptional performance when trained on well-illuminated images captured by Electro-Optical (EO) cameras, which provide rich texture details. However, in critical applications like aerial perception, it is essential for DNNs to maintain consistent reliability across all conditions, including low-light scenarios where EO cameras often struggle to capture sufficient detail. Additionally, UAV-based aerial object detection faces significant challenges due to scale variability from varying altitudes and slant angles, adding another layer of complexity. Existing methods typically address only illumination changes or style variations as domain shifts, but in aerial perception, correlation shifts also impact DNN performance. In this paper, we introduce the IndraEye dataset, a multi-sensor (EO-IR) dataset designed for various tasks. It includes 5,612 images with 145,666 instances, encompassing multiple viewing angles, altitudes, seven backgrounds, and different times of the day across the Indian subcontinent. The dataset opens up several research opportunities, such as multimodal learning, domain adaptation for object detection and segmentation, and exploration of sensor-specific strengths and weaknesses. IndraEye aims to advance the field by supporting the development of more robust and accurate aerial perception systems, particularly in challenging conditions. IndraEye dataset is benchmarked with object detection and semantic segmentation tasks. Dataset and source codes are available at https://bit.ly/indraeye.
Distributed Online Life-Long Learning (DOL3) for Multi-agent Trust and Reputation Assessment in E-commerce
Oct 21, 2024
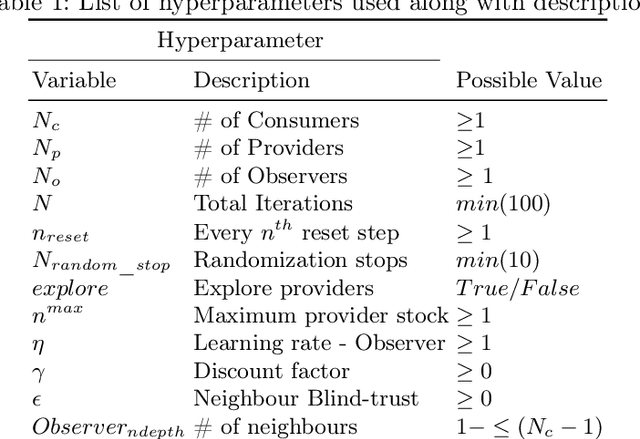

Trust and Reputation Assessment of service providers in citizen-focused environments like e-commerce is vital to maintain the integrity of the interactions among agents. The goals and objectives of both the service provider and service consumer agents are relevant to the goals of the respective citizens (end users). The provider agents often pursue selfish goals that can make the service quality highly volatile, contributing towards the non-stationary nature of the environment. The number of active service providers tends to change over time resulting in an open environment. This necessitates a rapid and continual assessment of the Trust and Reputation. A large number of service providers in the environment require a distributed multi-agent Trust and Reputation assessment. This paper addresses the problem of multi-agent Trust and Reputation Assessment in a non-stationary environment involving transactions between providers and consumers. In this setting, the observer agents carry out the assessment and communicate their assessed trust scores with each other over a network. We propose a novel Distributed Online Life-Long Learning (DOL3) algorithm that involves real-time rapid learning of trust and reputation scores of providers. Each observer carries out an adaptive learning and weighted fusion process combining their own assessment along with that of their neighbour in the communication network. Simulation studies reveal that the state-of-the-art methods, which usually involve training a model to assess an agent's trust and reputation, do not work well in such an environment. The simulation results show that the proposed DOL3 algorithm outperforms these methods and effectively handles the volatility in such environments. From the statistical evaluation, it is evident that DOL3 performs better compared to other models in 90% of the cases.
Syn2Real Domain Generalization for Underwater Mine-like Object Detection Using Side-Scan Sonar
Oct 16, 2024
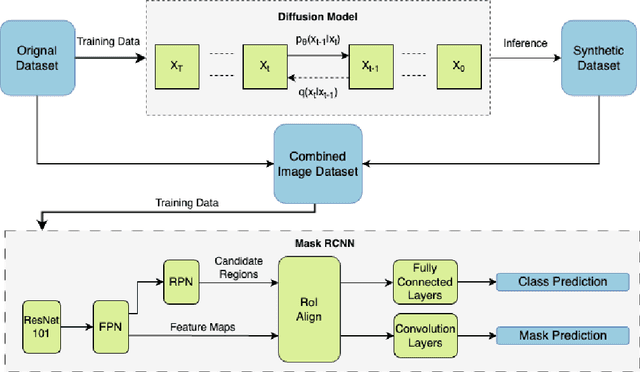

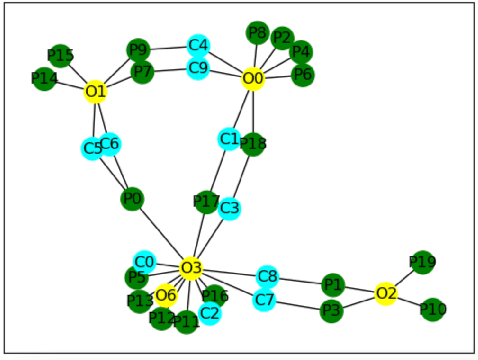
Underwater mine detection with deep learning suffers from limitations due to the scarcity of real-world data. This scarcity leads to overfitting, where models perform well on training data but poorly on unseen data. This paper proposes a Syn2Real (Synthetic to Real) domain generalization approach using diffusion models to address this challenge. We demonstrate that synthetic data generated with noise by DDPM and DDIM models, even if not perfectly realistic, can effectively augment real-world samples for training. The residual noise in the final sampled images improves the model's ability to generalize to real-world data with inherent noise and high variation. The baseline Mask-RCNN model when trained on a combination of synthetic and original training datasets, exhibited approximately a 60% increase in Average Precision (AP) compared to being trained solely on the original training data. This significant improvement highlights the potential of Syn2Real domain generalization for underwater mine detection tasks.