 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSupervised Image Translation from Visible to Infrared Domain for Object Detection
Paper and Code
Aug 03, 2024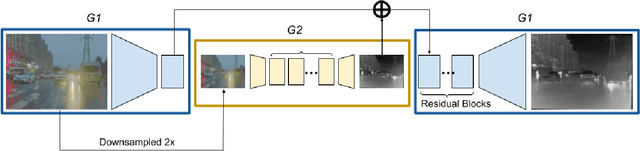

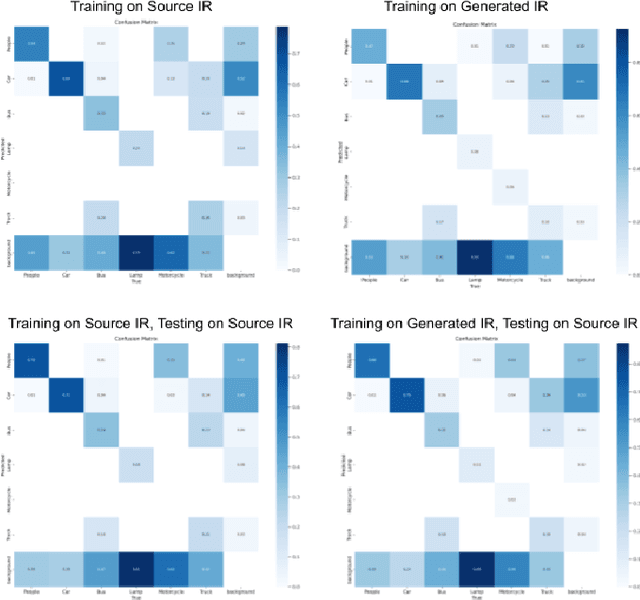
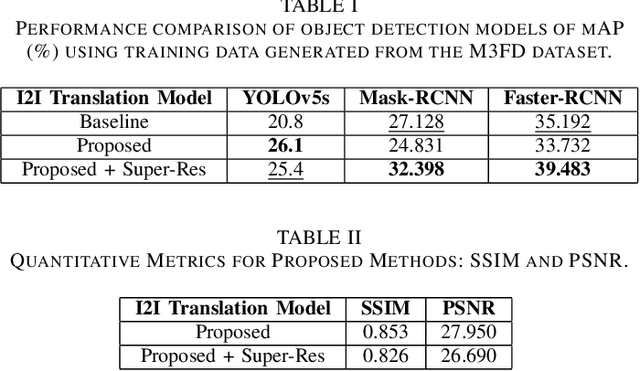
This study aims to learn a translation from visible to infrared imagery, bridging the domain gap between the two modalities so as to improve accuracy on downstream tasks including object detection. Previous approaches attempt to perform bi-domain feature fusion through iterative optimization or end-to-end deep convolutional networks. However, we pose the problem as similar to that of image translation, adopting a two-stage training strategy with a Generative Adversarial Network and an object detection model. The translation model learns a conversion that preserves the structural detail of visible images while preserving the texture and other characteristics of infrared images. Images so generated are used to train standard object detection frameworks including Yolov5, Mask and Faster RCNN. We also investigate the usefulness of integrating a super-resolution step into our pipeline to further improve model accuracy, and achieve an improvement of as high as 5.3% mAP.