 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSAGA: Semantic-Aware Gray color Augmentation for Visible-to-Thermal Domain Adaptation across Multi-View Drone and Ground-Based Vision Systems
Apr 22, 2025Domain-adaptive thermal object detection plays a key role in facilitating visible (RGB)-to-thermal (IR) adaptation by reducing the need for co-registered image pairs and minimizing reliance on large annotated IR datasets. However, inherent limitations of IR images, such as the lack of color and texture cues, pose challenges for RGB-trained models, leading to increased false positives and poor-quality pseudo-labels. To address this, we propose Semantic-Aware Gray color Augmentation (SAGA), a novel strategy for mitigating color bias and bridging the domain gap by extracting object-level features relevant to IR images. Additionally, to validate the proposed SAGA for drone imagery, we introduce the IndraEye, a multi-sensor (RGB-IR) dataset designed for diverse applications. The dataset contains 5,612 images with 145,666 instances, captured from diverse angles, altitudes, backgrounds, and times of day, offering valuable opportunities for multimodal learning, domain adaptation for object detection and segmentation, and exploration of sensor-specific strengths and weaknesses. IndraEye aims to enhance the development of more robust and accurate aerial perception systems, especially in challenging environments. Experimental results show that SAGA significantly improves RGB-to-IR adaptation for autonomous driving and IndraEye dataset, achieving consistent performance gains of +0.4% to +7.6% (mAP) when integrated with state-of-the-art domain adaptation techniques. The dataset and codes are available at https://github.com/airliisc/IndraEye.
IndraEye: Infrared Electro-Optical UAV-based Perception Dataset for Robust Downstream Tasks
Oct 28, 2024Deep neural networks (DNNs) have shown exceptional performance when trained on well-illuminated images captured by Electro-Optical (EO) cameras, which provide rich texture details. However, in critical applications like aerial perception, it is essential for DNNs to maintain consistent reliability across all conditions, including low-light scenarios where EO cameras often struggle to capture sufficient detail. Additionally, UAV-based aerial object detection faces significant challenges due to scale variability from varying altitudes and slant angles, adding another layer of complexity. Existing methods typically address only illumination changes or style variations as domain shifts, but in aerial perception, correlation shifts also impact DNN performance. In this paper, we introduce the IndraEye dataset, a multi-sensor (EO-IR) dataset designed for various tasks. It includes 5,612 images with 145,666 instances, encompassing multiple viewing angles, altitudes, seven backgrounds, and different times of the day across the Indian subcontinent. The dataset opens up several research opportunities, such as multimodal learning, domain adaptation for object detection and segmentation, and exploration of sensor-specific strengths and weaknesses. IndraEye aims to advance the field by supporting the development of more robust and accurate aerial perception systems, particularly in challenging conditions. IndraEye dataset is benchmarked with object detection and semantic segmentation tasks. Dataset and source codes are available at https://bit.ly/indraeye.
Syn2Real Domain Generalization for Underwater Mine-like Object Detection Using Side-Scan Sonar
Oct 16, 2024
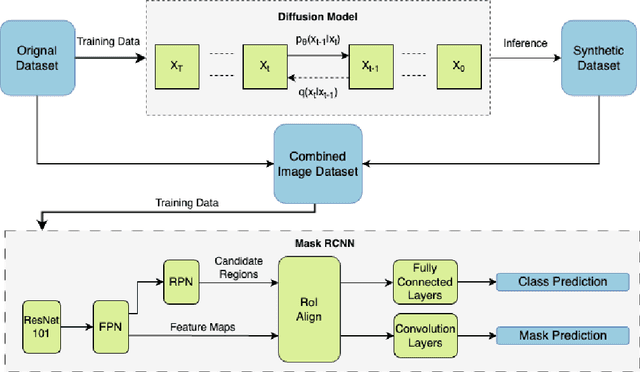

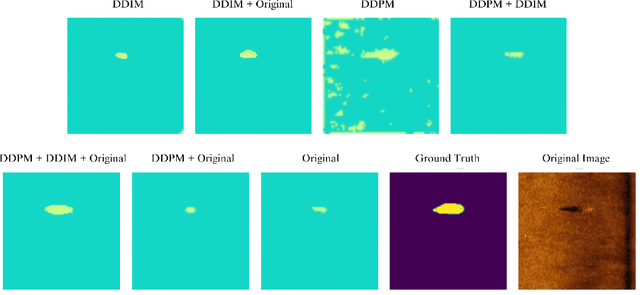
Underwater mine detection with deep learning suffers from limitations due to the scarcity of real-world data. This scarcity leads to overfitting, where models perform well on training data but poorly on unseen data. This paper proposes a Syn2Real (Synthetic to Real) domain generalization approach using diffusion models to address this challenge. We demonstrate that synthetic data generated with noise by DDPM and DDIM models, even if not perfectly realistic, can effectively augment real-world samples for training. The residual noise in the final sampled images improves the model's ability to generalize to real-world data with inherent noise and high variation. The baseline Mask-RCNN model when trained on a combination of synthetic and original training datasets, exhibited approximately a 60% increase in Average Precision (AP) compared to being trained solely on the original training data. This significant improvement highlights the potential of Syn2Real domain generalization for underwater mine detection tasks.
Supervised Image Translation from Visible to Infrared Domain for Object Detection
Aug 03, 2024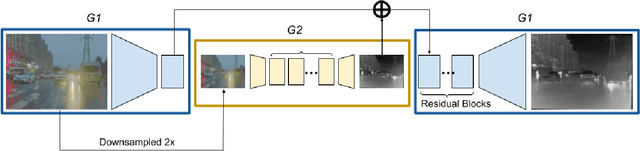

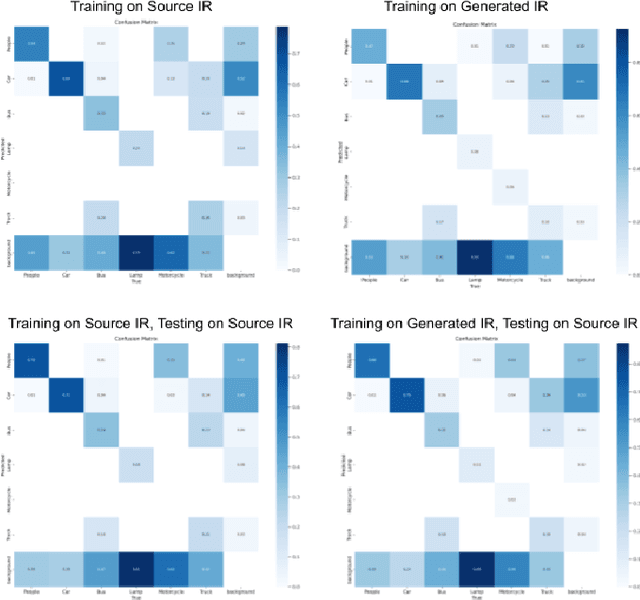
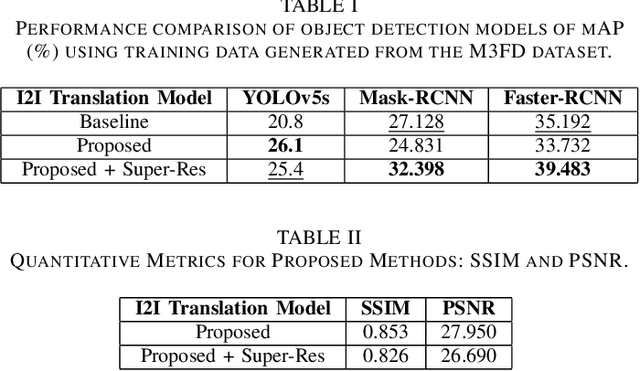
This study aims to learn a translation from visible to infrared imagery, bridging the domain gap between the two modalities so as to improve accuracy on downstream tasks including object detection. Previous approaches attempt to perform bi-domain feature fusion through iterative optimization or end-to-end deep convolutional networks. However, we pose the problem as similar to that of image translation, adopting a two-stage training strategy with a Generative Adversarial Network and an object detection model. The translation model learns a conversion that preserves the structural detail of visible images while preserving the texture and other characteristics of infrared images. Images so generated are used to train standard object detection frameworks including Yolov5, Mask and Faster RCNN. We also investigate the usefulness of integrating a super-resolution step into our pipeline to further improve model accuracy, and achieve an improvement of as high as 5.3% mAP.
Contrastive Learning-Based Spectral Knowledge Distillation for Multi-Modality and Missing Modality Scenarios in Semantic Segmentation
Dec 04, 2023Improving the performance of semantic segmentation models using multispectral information is crucial, especially for environments with low-light and adverse conditions. Multi-modal fusion techniques pursue either the learning of cross-modality features to generate a fused image or engage in knowledge distillation but address multimodal and missing modality scenarios as distinct issues, which is not an optimal approach for multi-sensor models. To address this, a novel multi-modal fusion approach called CSK-Net is proposed, which uses a contrastive learning-based spectral knowledge distillation technique along with an automatic mixed feature exchange mechanism for semantic segmentation in optical (EO) and infrared (IR) images. The distillation scheme extracts detailed textures from the optical images and distills them into the optical branch of CSK-Net. The model encoder consists of shared convolution weights with separate batch norm (BN) layers for both modalities, to capture the multi-spectral information from different modalities of the same objects. A Novel Gated Spectral Unit (GSU) and mixed feature exchange strategy are proposed to increase the correlation of modality-shared information and decrease the modality-specific information during the distillation process. Comprehensive experiments show that CSK-Net surpasses state-of-the-art models in multi-modal tasks and for missing modalities when exclusively utilizing IR data for inference across three public benchmarking datasets. For missing modality scenarios, the performance increase is achieved without additional computational costs compared to the baseline segmentation models.
MRFP: Learning Generalizable Semantic Segmentation from Sim-2-Real with Multi-Resolution Feature Perturbation
Nov 30, 2023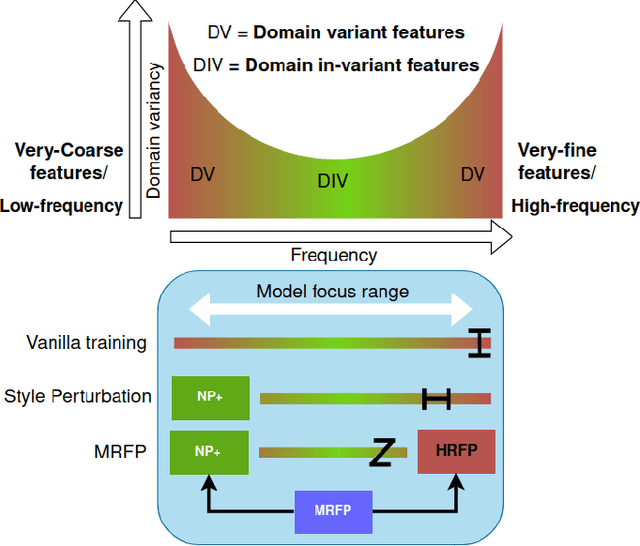
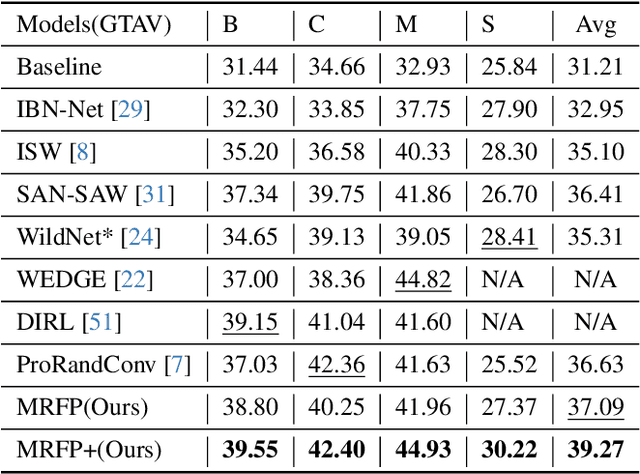
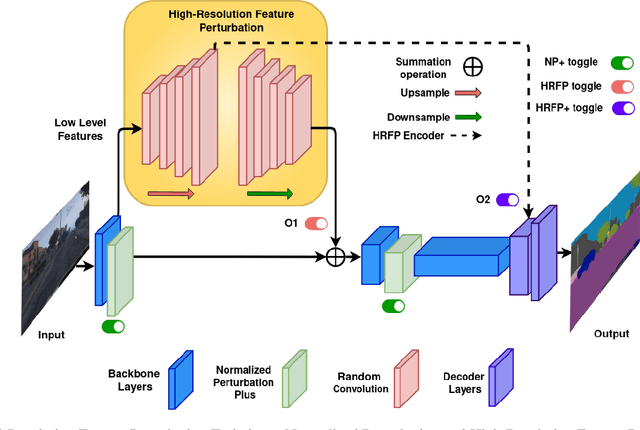
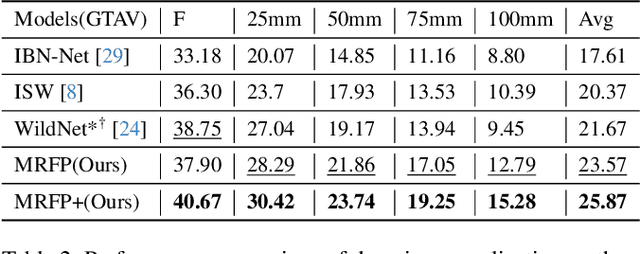
Deep neural networks have shown exemplary performance on semantic scene understanding tasks on source domains, but due to the absence of style diversity during training, enhancing performance on unseen target domains using only single source domain data remains a challenging task. Generation of simulated data is a feasible alternative to retrieving large style-diverse real-world datasets as it is a cumbersome and budget-intensive process. However, the large domain-specific inconsistencies between simulated and real-world data pose a significant generalization challenge in semantic segmentation. In this work, to alleviate this problem, we propose a novel MultiResolution Feature Perturbation (MRFP) technique to randomize domain-specific fine-grained features and perturb style of coarse features. Our experimental results on various urban-scene segmentation datasets clearly indicate that, along with the perturbation of style-information, perturbation of fine-feature components is paramount to learn domain invariant robust feature maps for semantic segmentation models. MRFP is a simple and computationally efficient, transferable module with no additional learnable parameters or objective functions, that helps state-of-the-art deep neural networks to learn robust domain invariant features for simulation-to-real semantic segmentation.
Multi-Modal Domain Fusion for Multi-modal Aerial View Object Classification
Dec 14, 2022Object detection and classification using aerial images is a challenging task as the information regarding targets are not abundant. Synthetic Aperture Radar(SAR) images can be used for Automatic Target Recognition(ATR) systems as it can operate in all-weather conditions and in low light settings. But, SAR images contain salt and pepper noise(speckle noise) that cause hindrance for the deep learning models to extract meaningful features. Using just aerial view Electro-optical(EO) images for ATR systems may also not result in high accuracy as these images are of low resolution and also do not provide ample information in extreme weather conditions. Therefore, information from multiple sensors can be used to enhance the performance of Automatic Target Recognition(ATR) systems. In this paper, we explore a methodology to use both EO and SAR sensor information to effectively improve the performance of the ATR systems by handling the shortcomings of each of the sensors. A novel Multi-Modal Domain Fusion(MDF) network is proposed to learn the domain invariant features from multi-modal data and use it to accurately classify the aerial view objects. The proposed MDF network achieves top-10 performance in the Track-1 with an accuracy of 25.3 % and top-5 performance in Track-2 with an accuracy of 34.26 % in the test phase on the PBVS MAVOC Challenge dataset [18].
Fully complex-valued deep learning model for visual perception
Dec 14, 2022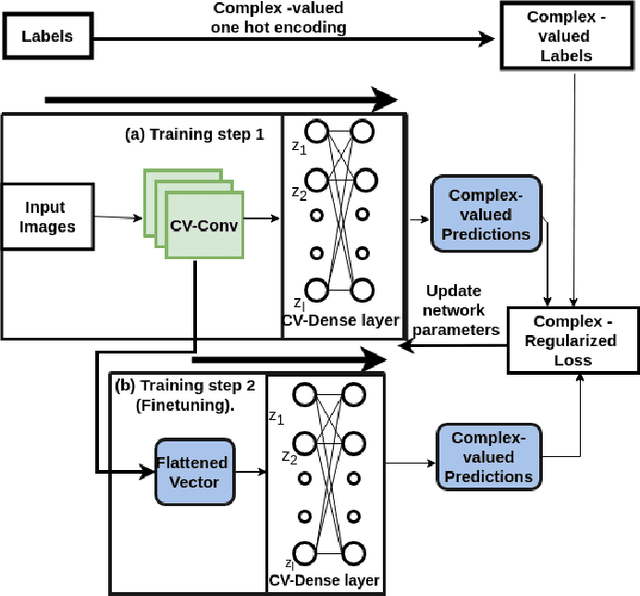
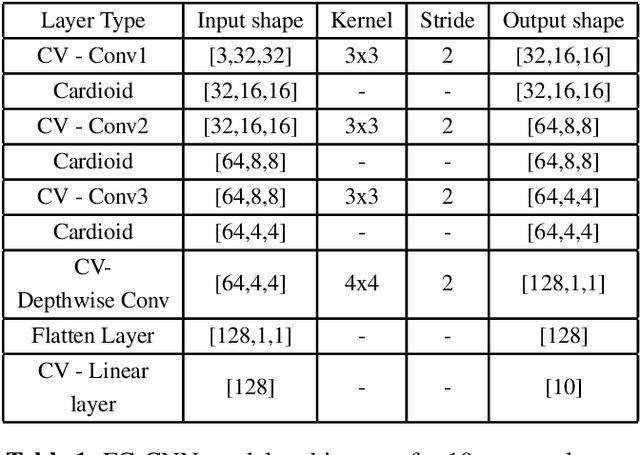
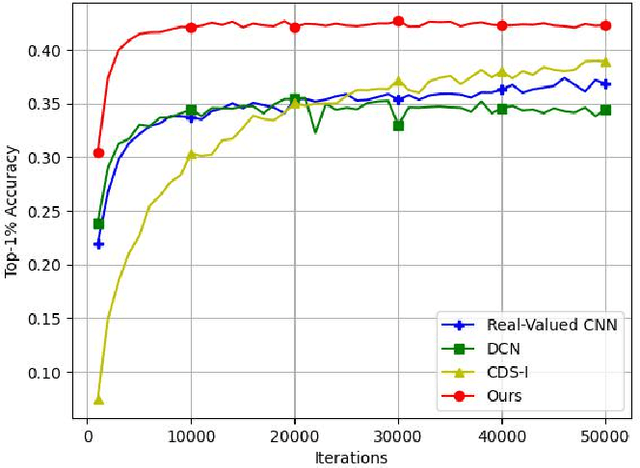

Deep learning models operating in the complex domain are used due to their rich representation capacity. However, most of these models are either restricted to the first quadrant of the complex plane or project the complex-valued data into the real domain, causing a loss of information. This paper proposes that operating entirely in the complex domain increases the overall performance of complex-valued models. A novel, fully complex-valued learning scheme is proposed to train a Fully Complex-valued Convolutional Neural Network (FC-CNN) using a newly proposed complex-valued loss function and training strategy. Benchmarked on CIFAR-10, SVHN, and CIFAR-100, FC-CNN has a 4-10% gain compared to its real-valued counterpart, maintaining the model complexity. With fewer parameters, it achieves comparable performance to state-of-the-art complex-valued models on CIFAR-10 and SVHN. For the CIFAR-100 dataset, it achieves state-of-the-art performance with 25% fewer parameters. FC-CNN shows better training efficiency and much faster convergence than all the other models.
Fully Complex-valued Fully Convolutional Multi-feature Fusion Network (FC2MFN) for Building Segmentation of InSAR images
Dec 14, 2022Building segmentation in high-resolution InSAR images is a challenging task that can be useful for large-scale surveillance. Although complex-valued deep learning networks perform better than their real-valued counterparts for complex-valued SAR data, phase information is not retained throughout the network, which causes a loss of information. This paper proposes a Fully Complex-valued, Fully Convolutional Multi-feature Fusion Network(FC2MFN) for building semantic segmentation on InSAR images using a novel, fully complex-valued learning scheme. The network learns multi-scale features, performs multi-feature fusion, and has a complex-valued output. For the particularity of complex-valued InSAR data, a new complex-valued pooling layer is proposed that compares complex numbers considering their magnitude and phase. This helps the network retain the phase information even through the pooling layer. Experimental results on the simulated InSAR dataset show that FC2MFN achieves better results compared to other state-of-the-art methods in terms of segmentation performance and model complexity.