 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDevelopment of Domain-Invariant Visual Enhancement and Restoration (DIVER) Approach for Underwater Images
Jan 30, 2026Underwater images suffer severe degradation due to wavelength-dependent attenuation, scattering, and illumination non-uniformity that vary across water types and depths. We propose an unsupervised Domain-Invariant Visual Enhancement and Restoration (DIVER) framework that integrates empirical correction with physics-guided modeling for robust underwater image enhancement. DIVER first applies either IlluminateNet for adaptive luminance enhancement or a Spectral Equalization Filter for spectral normalization. An Adaptive Optical Correction Module then refines hue and contrast using channel-adaptive filtering, while Hydro-OpticNet employs physics-constrained learning to compensate for backscatter and wavelength-dependent attenuation. The parameters of IlluminateNet and Hydro-OpticNet are optimized via unsupervised learning using a composite loss function. DIVER is evaluated on eight diverse datasets covering shallow, deep, and highly turbid environments, including both naturally low-light and artificially illuminated scenes, using reference and non-reference metrics. While state-of-the-art methods such as WaterNet, UDNet, and Phaseformer perform reasonably in shallow water, their performance degrades in deep, unevenly illuminated, or artificially lit conditions. In contrast, DIVER consistently achieves best or near-best performance across all datasets, demonstrating strong domain-invariant capability. DIVER yields at least a 9% improvement over SOTA methods in UCIQE. On the low-light SeaThru dataset, where color-palette references enable direct evaluation of color restoration, DIVER achieves at least a 4.9% reduction in GPMAE compared to existing methods. Beyond visual quality, DIVER also improves robotic perception by enhancing ORB-based keypoint repeatability and matching performance, confirming its robustness across diverse underwater environments.
Priority-based DREAM Approach for Highly Manoeuvring Intruders in A Perimeter Defense Problem
Jul 19, 2023



In this paper, a Priority-based Dynamic REsource Allocation with decentralized Multi-task assignment (P-DREAM) approach is presented to protect a territory from highly manoeuvring intruders. In the first part, static optimization problems are formulated to compute the following parameters of the perimeter defense problem; the number of reserve stations, their locations, the priority region, the monitoring region, and the minimum number of defenders required for the monitoring purpose. The concept of a prioritized intruder is proposed here to identify and handle those critical intruders (computed based on the velocity ratio and location) to be tackled on a priority basis. The computed priority region helps to assign reserve defenders sufficiently earlier such that they can neutralize the prioritized intruders. The monitoring region defines the minimum region to be monitored and is sufficient enough to handle the intruders. In the second part, the earlier developed DREAM approach is modified to incorporate the priority of an intruder. The proposed P-DREAM approach assigns the defenders to the prioritized intruders as the first task. A convex territory protection problem is simulated to illustrate the P-DREAM approach. It involves the computation of static parameters and solving the prioritized task assignments with dynamic resource allocation. Monte-Carlo results were conducted to verify the performance of P-DREAM, and the results clearly show that the P-DREAM approach can protect the territory with consistent performance against highly manoeuvring intruders.
Predictive Maneuver Planning with Deep Reinforcement Learning (PMP-DRL) for comfortable and safe autonomous driving
Jun 15, 2023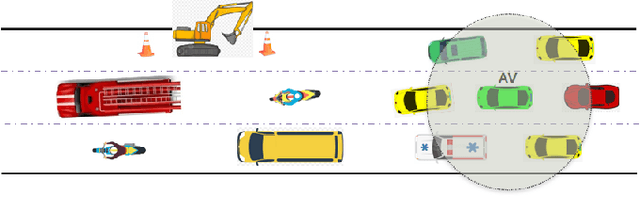
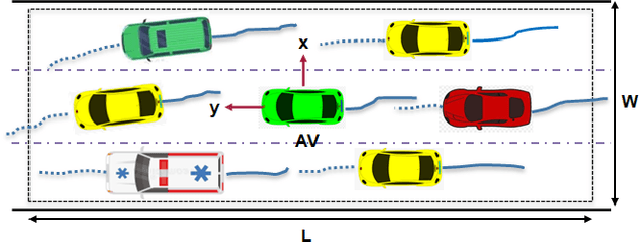
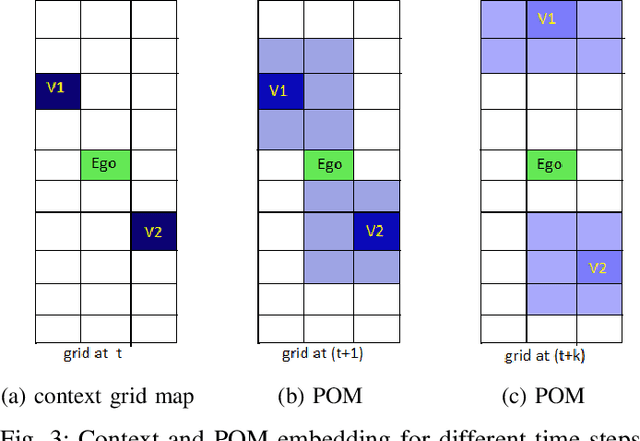
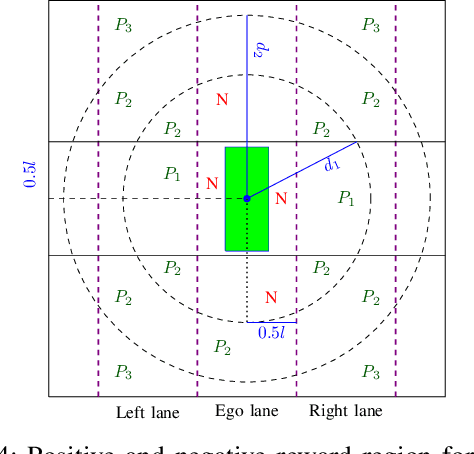
This paper presents a Predictive Maneuver Planning with Deep Reinforcement Learning (PMP-DRL) model for maneuver planning. Traditional rule-based maneuver planning approaches often have to improve their abilities to handle the variabilities of real-world driving scenarios. By learning from its experience, a Reinforcement Learning (RL)-based driving agent can adapt to changing driving conditions and improve its performance over time. Our proposed approach combines a predictive model and an RL agent to plan for comfortable and safe maneuvers. The predictive model is trained using historical driving data to predict the future positions of other surrounding vehicles. The surrounding vehicles' past and predicted future positions are embedded in context-aware grid maps. At the same time, the RL agent learns to make maneuvers based on this spatio-temporal context information. Performance evaluation of PMP-DRL has been carried out using simulated environments generated from publicly available NGSIM US101 and I80 datasets. The training sequence shows the continuous improvement in the driving experiences. It shows that proposed PMP-DRL can learn the trade-off between safety and comfortability. The decisions generated by the recent imitation learning-based model are compared with the proposed PMP-DRL for unseen scenarios. The results clearly show that PMP-DRL can handle complex real-world scenarios and make better comfortable and safe maneuver decisions than rule-based and imitative models.
Fully Complex-valued Fully Convolutional Multi-feature Fusion Network (FC2MFN) for Building Segmentation of InSAR images
Dec 14, 2022Building segmentation in high-resolution InSAR images is a challenging task that can be useful for large-scale surveillance. Although complex-valued deep learning networks perform better than their real-valued counterparts for complex-valued SAR data, phase information is not retained throughout the network, which causes a loss of information. This paper proposes a Fully Complex-valued, Fully Convolutional Multi-feature Fusion Network(FC2MFN) for building semantic segmentation on InSAR images using a novel, fully complex-valued learning scheme. The network learns multi-scale features, performs multi-feature fusion, and has a complex-valued output. For the particularity of complex-valued InSAR data, a new complex-valued pooling layer is proposed that compares complex numbers considering their magnitude and phase. This helps the network retain the phase information even through the pooling layer. Experimental results on the simulated InSAR dataset show that FC2MFN achieves better results compared to other state-of-the-art methods in terms of segmentation performance and model complexity.
An efficient Deep Spatio-Temporal Context Aware decision Network (DST-CAN) for Predictive Manoeuvre Planning
May 20, 2022
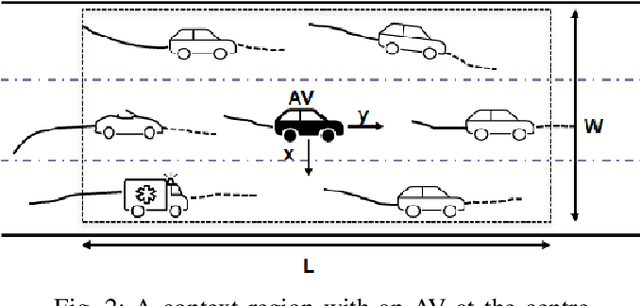

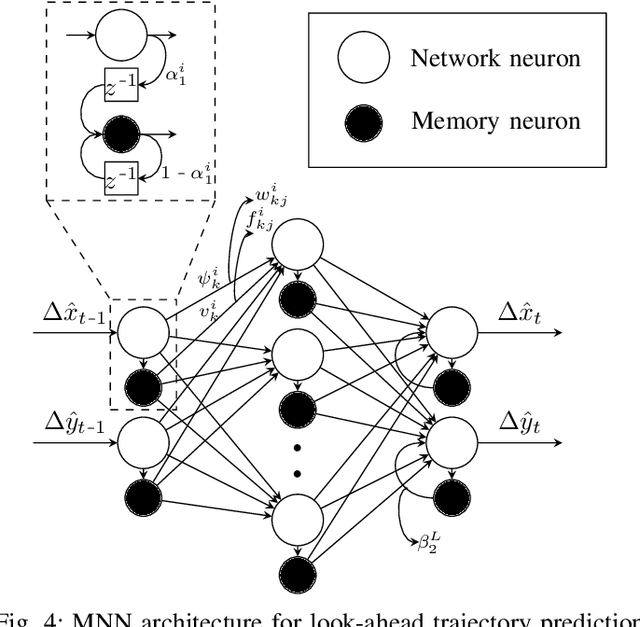
To ensure the safety and efficiency of its maneuvers, an Autonomous Vehicle (AV) should anticipate the future intentions of surrounding vehicles using its sensor information. If an AV can predict its surrounding vehicles' future trajectories, it can make safe and efficient manoeuvre decisions. In this paper, we present such a Deep Spatio-Temporal Context-Aware decision Network (DST-CAN) model for predictive manoeuvre planning of AVs. A memory neuron network is used to predict future trajectories of its surrounding vehicles. The driving environment's spatio-temporal information (past, present, and predicted future trajectories) are embedded into a context-aware grid. The proposed DST-CAN model employs these context-aware grids as inputs to a convolutional neural network to understand the spatial relationships between the vehicles and determine a safe and efficient manoeuvre decision. The DST-CAN model also uses information of human driving behavior on a highway. Performance evaluation of DST-CAN has been carried out using two publicly available NGSIM US-101 and I-80 datasets. Also, rule-based ground truth decisions have been compared with those generated by DST-CAN. The results clearly show that DST-CAN can make much better decisions with 3-sec of predicted trajectories of neighboring vehicles compared to currently existing methods that do not use this prediction.
Robust EMRAN based Neural Aided Learning Controller for Autonomous Vehicles
Jun 30, 2021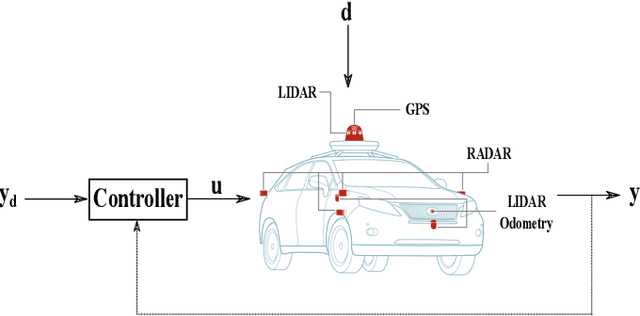
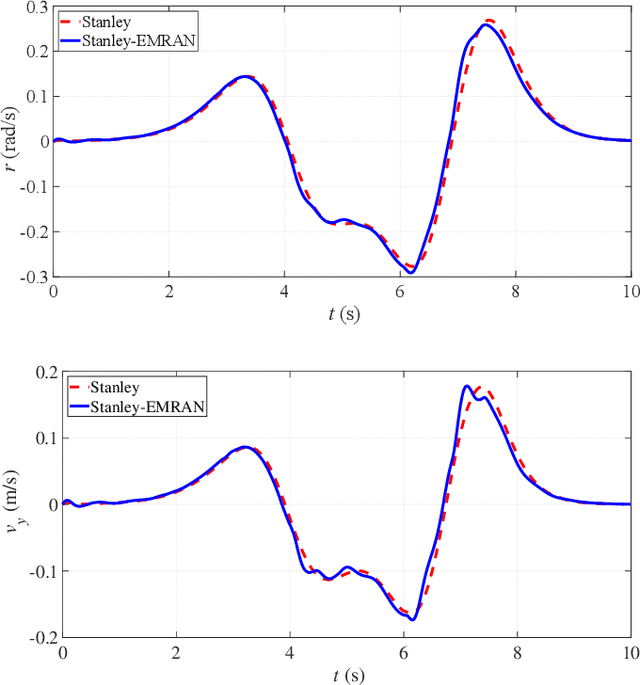

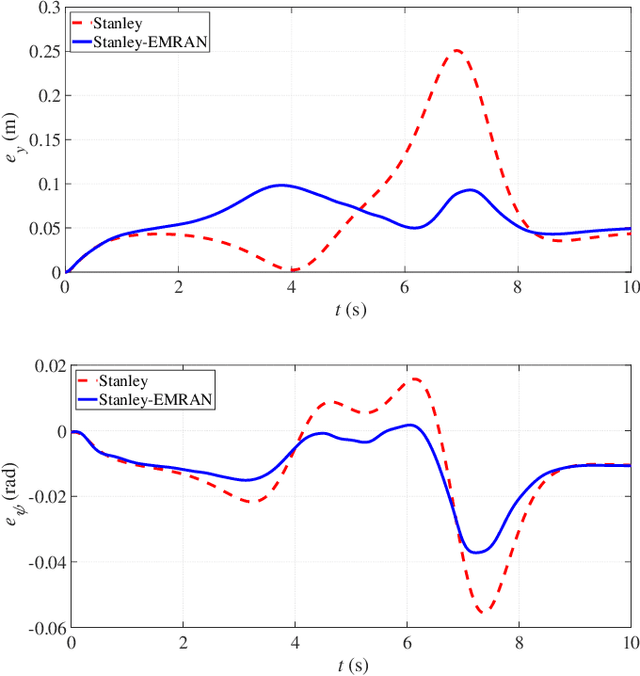
This paper presents an online evolving neural network-based inverse dynamics learning controller for an autonomous vehicle's longitudinal and lateral control under model uncertainties and disturbances. The inverse dynamics of the vehicle are approximated using a feedback error learning mechanism that utilizes a dynamic Radial Basis Function neural network, referred to as the Extended Minimal Resource Allocating Network (EMRAN). EMRAN uses an extended Kalman filter approach for learning and a growing/pruning condition helps in keeping the number of hidden neurons minimum. The online learning algorithm helps in handling the uncertainties and dynamic variations and also the unknown disturbances on the road. The proposed control architecture employs two coupled conventional controllers aided by the EMRAN inverse dynamics controller. The control architecture has a conventional PID controller for longitudinal cruise control and a Stanley controller for lateral path-tracking. Performances of both the longitudinal and lateral controllers are compared with existing control methods and the simulation results clearly indicate that the proposed control scheme handles the disturbances and parametric uncertainties better, and also provides better tracking performance in autonomous vehicles.
A Decentralized Multi-UAV Spatio-Temporal Multi-Task Allocation Approach for Perimeter Defense
Feb 15, 2021
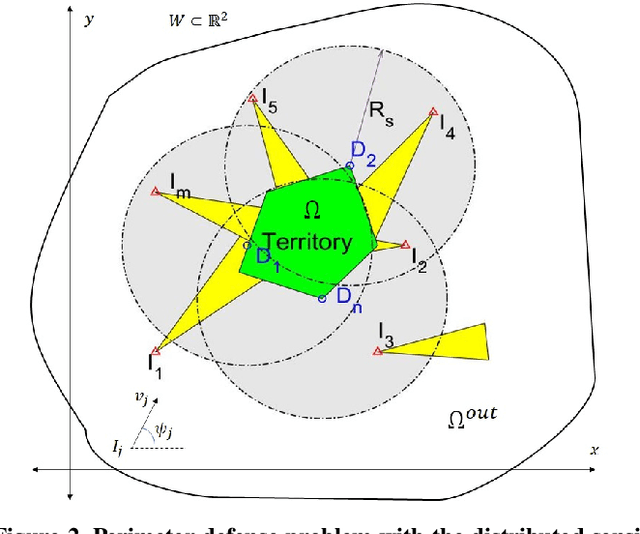
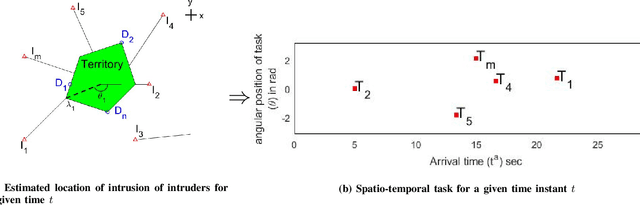
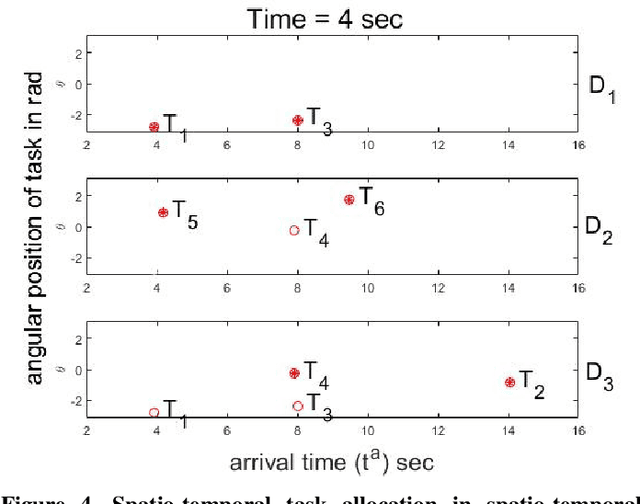
This paper provides a new solution approach to a multi-player perimeter defense game, in which the intruders' team tries to enter the territory, and a team of defenders protects the territory by capturing intruders on the perimeter of the territory. The objective of the defenders is to detect and capture the intruders before the intruders enter the territory. Each defender independently senses the intruder and computes his trajectory to capture the assigned intruders in a cooperative fashion. The intruder is estimated to reach a specific location on the perimeter at a specific time. Each intruder is viewed as a spatio-temporal task, and the defenders are assigned to execute these spatio-temporal tasks. At any given time, the perimeter defense problem is converted into a Decentralized Multi-UAV Spatio-Temporal Multi-Task Allocation (DMUST-MTA) problem. The cost of executing a task for a trajectory is defined by a composite cost function of both the spatial and temporal components. In this paper, a decentralized consensus-based bundle algorithm has been modified to solve the spatio-temporal multi-task allocation problem, and the performance evaluation of the proposed approach is carried out based on Monte-Carlo simulations. The simulation results show the effectiveness of the proposed approach to solve the perimeter defense game under different scenarios. Performance comparison with a state-of-the-art centralized approach with full observability, clearly indicates that DMUST-MTA achieves similar performance in a decentralized way with partial observability conditions with a lesser computational time and easy scaling up.