 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeECCO: Can We Improve Model-Generated Code Efficiency Without Sacrificing Functional Correctness?
Jul 19, 2024Although large language models (LLMs) have been largely successful in generating functionally correct programs, conditioning models to produce efficient solutions while ensuring correctness remains a challenge. Further, unreliability in benchmarking code efficiency is a hurdle across varying hardware specifications for popular interpreted languages such as Python. In this paper, we present ECCO, a reproducible benchmark for evaluating program efficiency via two paradigms: natural language (NL) based code generation and history-based code editing. On ECCO, we adapt and thoroughly investigate the three most promising existing LLM-based approaches: in-context learning, iterative refinement with execution or NL feedback, and fine-tuning conditioned on execution and editing history. While most methods degrade functional correctness and moderately increase program efficiency, we find that adding execution information often helps maintain functional correctness, and NL feedback enhances more on efficiency. We release our benchmark to support future work on LLM-based generation of efficient code.
Calc-CMU at SemEval-2024 Task 7: Pre-Calc -- Learning to Use the Calculator Improves Numeracy in Language Models
Apr 26, 2024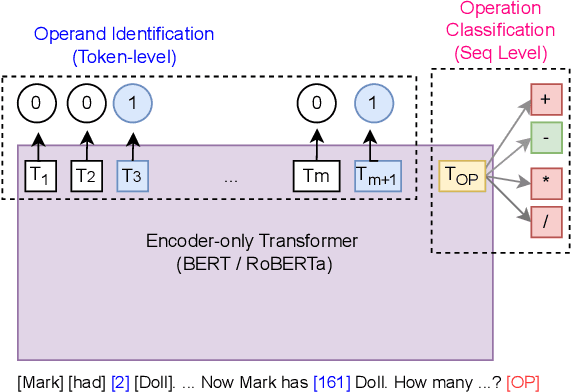
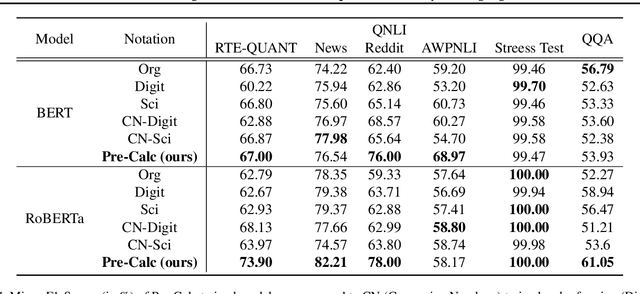
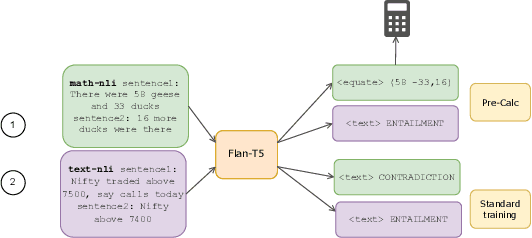
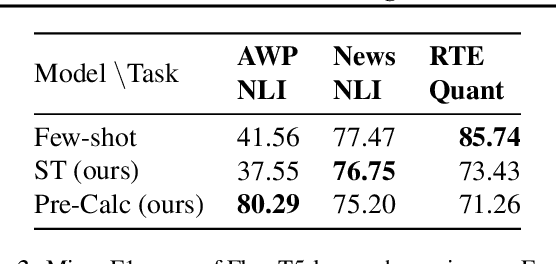
Quantitative and numerical comprehension in language is an important task in many fields like education and finance, but still remains a challenging task for language models. While tool and calculator usage has shown to be helpful to improve mathematical reasoning in large pretrained decoder-only language models, this remains unexplored for smaller language models with encoders. In this paper, we propose Pre-Calc, a simple pre-finetuning objective of learning to use the calculator for both encoder-only and encoder-decoder architectures, formulated as a discriminative and generative task respectively. We pre-train BERT and RoBERTa for discriminative calculator use and Flan-T5 for generative calculator use on the MAWPS, SVAMP, and AsDiv-A datasets, which improves performance on downstream tasks that require numerical understanding. Our code and data are available at https://github.com/calc-cmu/pre-calc.
ScripTONES: Sentiment-Conditioned Music Generation for Movie Scripts
Jan 13, 2024



Film scores are considered an essential part of the film cinematic experience, but the process of film score generation is often expensive and infeasible for small-scale creators. Automating the process of film score composition would provide useful starting points for music in small projects. In this paper, we propose a two-stage pipeline for generating music from a movie script. The first phase is the Sentiment Analysis phase where the sentiment of a scene from the film script is encoded into the valence-arousal continuous space. The second phase is the Conditional Music Generation phase which takes as input the valence-arousal vector and conditionally generates piano MIDI music to match the sentiment. We study the efficacy of various music generation architectures by performing a qualitative user survey and propose methods to improve sentiment-conditioning in VAE architectures.
XLDA: Linear Discriminant Analysis for Scaling Continual Learning to Extreme Classification at the Edge
Jul 21, 2023Streaming Linear Discriminant Analysis (LDA) while proven in Class-incremental Learning deployments at the edge with limited classes (upto 1000), has not been proven for deployment in extreme classification scenarios. In this paper, we present: (a) XLDA, a framework for Class-IL in edge deployment where LDA classifier is proven to be equivalent to FC layer including in extreme classification scenarios, and (b) optimizations to enable XLDA-based training and inference for edge deployment where there is a constraint on available compute resources. We show up to 42x speed up using a batched training approach and up to 5x inference speedup with nearest neighbor search on extreme datasets like AliProducts (50k classes) and Google Landmarks V2 (81k classes)
Predictive Maneuver Planning with Deep Reinforcement Learning (PMP-DRL) for comfortable and safe autonomous driving
Jun 15, 2023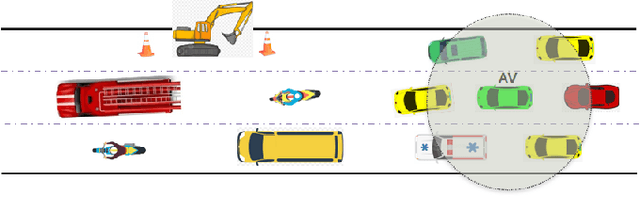
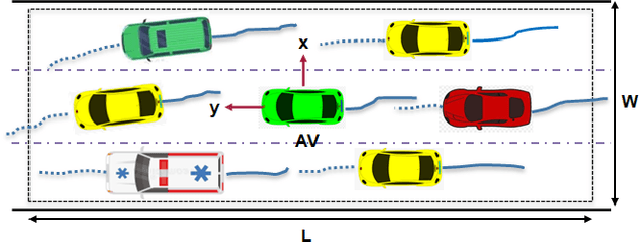
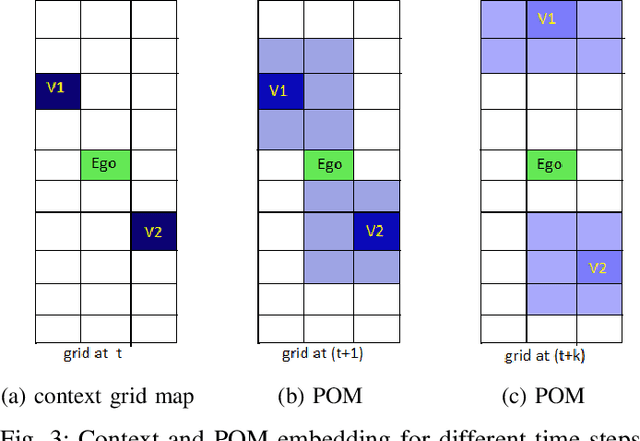
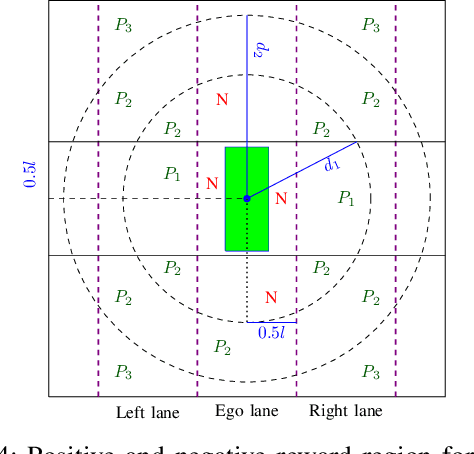
This paper presents a Predictive Maneuver Planning with Deep Reinforcement Learning (PMP-DRL) model for maneuver planning. Traditional rule-based maneuver planning approaches often have to improve their abilities to handle the variabilities of real-world driving scenarios. By learning from its experience, a Reinforcement Learning (RL)-based driving agent can adapt to changing driving conditions and improve its performance over time. Our proposed approach combines a predictive model and an RL agent to plan for comfortable and safe maneuvers. The predictive model is trained using historical driving data to predict the future positions of other surrounding vehicles. The surrounding vehicles' past and predicted future positions are embedded in context-aware grid maps. At the same time, the RL agent learns to make maneuvers based on this spatio-temporal context information. Performance evaluation of PMP-DRL has been carried out using simulated environments generated from publicly available NGSIM US101 and I80 datasets. The training sequence shows the continuous improvement in the driving experiences. It shows that proposed PMP-DRL can learn the trade-off between safety and comfortability. The decisions generated by the recent imitation learning-based model are compared with the proposed PMP-DRL for unseen scenarios. The results clearly show that PMP-DRL can handle complex real-world scenarios and make better comfortable and safe maneuver decisions than rule-based and imitative models.
A Comparative Study of Algorithms for Intelligent Traffic Signal Control
Sep 18, 2021
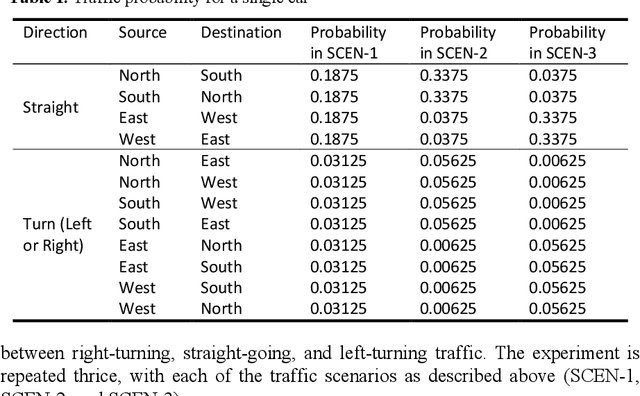
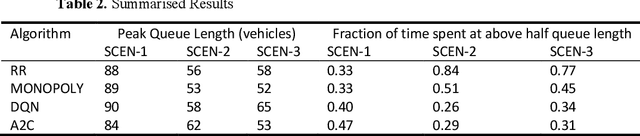
In this paper, methods have been explored to effectively optimise traffic signal control to minimise waiting times and queue lengths, thereby increasing traffic flow. The traffic intersection was first defined as a Markov Decision Process, and a state representation, actions and rewards were chosen. Simulation of Urban MObility (SUMO) was used to simulate an intersection and then compare a Round Robin Scheduler, a Feedback Control mechanism and two Reinforcement Learning techniques - Deep Q Network (DQN) and Advantage Actor-Critic (A2C), as the policy for the traffic signal in the simulation under different scenarios. Finally, the methods were tested on a simulation of a real-world intersection in Bengaluru, India.