 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Well Does Agent Development Reflect Real-World Work?
Mar 01, 2026AI agents are increasingly developed and evaluated on benchmarks relevant to human work, yet it remains unclear how representative these benchmarking efforts are of the labor market as a whole. In this work, we systematically study the relationship between agent development efforts and the distribution of real-world human work by mapping benchmark instances to work domains and skills. We first analyze 43 benchmarks and 72,342 tasks, measuring their alignment with human employment and capital allocation across all 1,016 real-world occupations in the U.S. labor market. We reveal substantial mismatches between agent development that tends to be programming-centric, and the categories in which human labor and economic value are concentrated. Within work areas that agents currently target, we further characterize current agent utility by measuring their autonomy levels, providing practical guidance for agent interaction strategies across work scenarios. Building on these findings, we propose three measurable principles for designing benchmarks that better capture socially important and technically challenging forms of work: coverage, realism, and granular evaluation.
Modeling Distinct Human Interaction in Web Agents
Feb 19, 2026Despite rapid progress in autonomous web agents, human involvement remains essential for shaping preferences and correcting agent behavior as tasks unfold. However, current agentic systems lack a principled understanding of when and why humans intervene, often proceeding autonomously past critical decision points or requesting unnecessary confirmation. In this work, we introduce the task of modeling human intervention to support collaborative web task execution. We collect CowCorpus, a dataset of 400 real-user web navigation trajectories containing over 4,200 interleaved human and agent actions. We identify four distinct patterns of user interaction with agents -- hands-off supervision, hands-on oversight, collaborative task-solving, and full user takeover. Leveraging these insights, we train language models (LMs) to anticipate when users are likely to intervene based on their interaction styles, yielding a 61.4-63.4% improvement in intervention prediction accuracy over base LMs. Finally, we deploy these intervention-aware models in live web navigation agents and evaluate them in a user study, finding a 26.5% increase in user-rated agent usefulness. Together, our results show structured modeling of human intervention leads to more adaptive, collaborative agents.
Vision-as-Inverse-Graphics Agent via Interleaved Multimodal Reasoning
Jan 16, 2026Vision-as-inverse-graphics, the concept of reconstructing an image as an editable graphics program is a long-standing goal of computer vision. Yet even strong VLMs aren't able to achieve this in one-shot as they lack fine-grained spatial and physical grounding capability. Our key insight is that closing this gap requires interleaved multimodal reasoning through iterative execution and verification. Stemming from this, we present VIGA (Vision-as-Inverse-Graphic Agent) that starts from an empty world and reconstructs or edits scenes through a closed-loop write-run-render-compare-revise procedure. To support long-horizon reasoning, VIGA combines (i) a skill library that alternates generator and verifier roles and (ii) an evolving context memory that contains plans, code diffs, and render history. VIGA is task-agnostic as it doesn't require auxiliary modules, covering a wide range of tasks such as 3D reconstruction, multi-step scene editing, 4D physical interaction, and 2D document editing, etc. Empirically, we found VIGA substantially improves one-shot baselines on BlenderGym (35.32%) and SlideBench (117.17%). Moreover, VIGA is also model-agnostic as it doesn't require finetuning, enabling a unified protocol to evaluate heterogeneous foundation VLMs. To better support this protocol, we introduce BlenderBench, a challenging benchmark that stress-tests interleaved multimodal reasoning with graphics engine, where VIGA improves by 124.70%.
How Do AI Agents Do Human Work? Comparing AI and Human Workflows Across Diverse Occupations
Oct 26, 2025AI agents are continually optimized for tasks related to human work, such as software engineering and professional writing, signaling a pressing trend with significant impacts on the human workforce. However, these agent developments have often not been grounded in a clear understanding of how humans execute work, to reveal what expertise agents possess and the roles they can play in diverse workflows. In this work, we study how agents do human work by presenting the first direct comparison of human and agent workers across multiple essential work-related skills: data analysis, engineering, computation, writing, and design. To better understand and compare heterogeneous computer-use activities of workers, we introduce a scalable toolkit to induce interpretable, structured workflows from either human or agent computer-use activities. Using such induced workflows, we compare how humans and agents perform the same tasks and find that: (1) While agents exhibit promise in their alignment to human workflows, they take an overwhelmingly programmatic approach across all work domains, even for open-ended, visually dependent tasks like design, creating a contrast with the UI-centric methods typically used by humans. (2) Agents produce work of inferior quality, yet often mask their deficiencies via data fabrication and misuse of advanced tools. (3) Nonetheless, agents deliver results 88.3% faster and cost 90.4-96.2% less than humans, highlighting the potential for enabling efficient collaboration by delegating easily programmable tasks to agents.
OpenAgentSafety: A Comprehensive Framework for Evaluating Real-World AI Agent Safety
Jul 08, 2025



Recent advances in AI agents capable of solving complex, everyday tasks, from scheduling to customer service, have enabled deployment in real-world settings, but their possibilities for unsafe behavior demands rigorous evaluation. While prior benchmarks have attempted to assess agent safety, most fall short by relying on simulated environments, narrow task domains, or unrealistic tool abstractions. We introduce OpenAgentSafety, a comprehensive and modular framework for evaluating agent behavior across eight critical risk categories. Unlike prior work, our framework evaluates agents that interact with real tools, including web browsers, code execution environments, file systems, bash shells, and messaging platforms; and supports over 350 multi-turn, multi-user tasks spanning both benign and adversarial user intents. OpenAgentSafety is designed for extensibility, allowing researchers to add tools, tasks, websites, and adversarial strategies with minimal effort. It combines rule-based analysis with LLM-as-judge assessments to detect both overt and subtle unsafe behaviors. Empirical analysis of five prominent LLMs in agentic scenarios reveals unsafe behavior in 51.2% of safety-vulnerable tasks with Claude-Sonnet-3.7, to 72.7% with o3-mini, highlighting critical safety vulnerabilities and the need for stronger safeguards before real-world deployment.
Inducing Programmatic Skills for Agentic Tasks
Apr 09, 2025
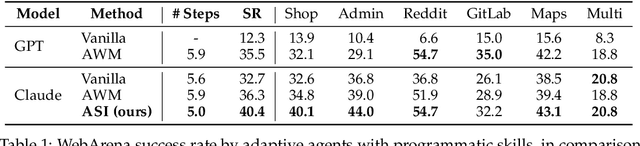
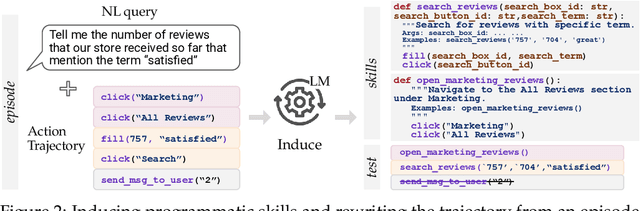

To succeed in common digital tasks such as web navigation, agents must carry out a variety of specialized tasks such as searching for products or planning a travel route. To tackle these tasks, agents can bootstrap themselves by learning task-specific skills online through interaction with the web environment. In this work, we demonstrate that programs are an effective representation for skills. We propose agent skill induction (ASI), which allows agents to adapt themselves by inducing, verifying, and utilizing program-based skills on the fly. We start with an evaluation on the WebArena agent benchmark and show that ASI outperforms the static baseline agent and its text-skill counterpart by 23.5% and 11.3% in success rate, mainly thanks to the programmatic verification guarantee during the induction phase. ASI also improves efficiency by reducing 10.7-15.3% of the steps over baselines, by composing primitive actions (e.g., click) into higher-level skills (e.g., search product). We then highlight the efficacy of ASI in remaining efficient and accurate under scaled-up web activities. Finally, we examine the generalizability of induced skills when transferring between websites, and find that ASI can effectively reuse common skills, while also updating incompatible skills to versatile website changes.
SkillWeaver: Web Agents can Self-Improve by Discovering and Honing Skills
Apr 09, 2025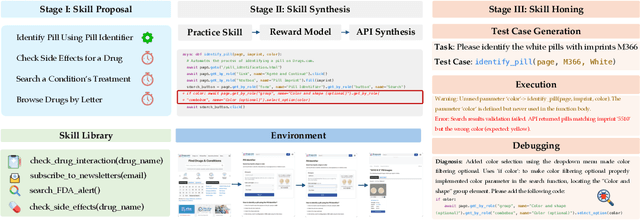
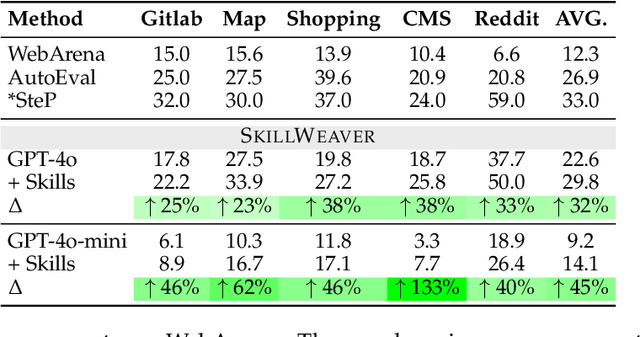

To survive and thrive in complex environments, humans have evolved sophisticated self-improvement mechanisms through environment exploration, hierarchical abstraction of experiences into reuseable skills, and collaborative construction of an ever-growing skill repertoire. Despite recent advancements, autonomous web agents still lack crucial self-improvement capabilities, struggling with procedural knowledge abstraction, refining skills, and skill composition. In this work, we introduce SkillWeaver, a skill-centric framework enabling agents to self-improve by autonomously synthesizing reusable skills as APIs. Given a new website, the agent autonomously discovers skills, executes them for practice, and distills practice experiences into robust APIs. Iterative exploration continually expands a library of lightweight, plug-and-play APIs, significantly enhancing the agent's capabilities. Experiments on WebArena and real-world websites demonstrate the efficacy of SkillWeaver, achieving relative success rate improvements of 31.8% and 39.8%, respectively. Additionally, APIs synthesized by strong agents substantially enhance weaker agents through transferable skills, yielding improvements of up to 54.3% on WebArena. These results demonstrate the effectiveness of honing diverse website interactions into APIs, which can be seamlessly shared among various web agents.
Benchmarking Failures in Tool-Augmented Language Models
Mar 18, 2025



The integration of tools has extended the capabilities of language models (LMs) beyond vanilla text generation to versatile scenarios. However, tool-augmented language models (TaLMs) often assume 'perfect' information access and tool availability, which may not hold in the real world. To systematically study TaLMs' imperfections, we introduce the FAIL-TALMS benchmark, featuring two major failures: under-specified user queries and non-available tools. FAIL-TALMS contains 1,749 examples using 906 tools across 21 categories, including single- and multi-tool usage. We evaluate top-performing proprietary and open-source models, and find all current models except for Claude struggle to recognize missing tools or information. Further, to study possible mitigation of the failures, we enable real-time human interaction, named the Ask-and-Help (AAH) method, to provide missing information or replace non-functional tools. While AAH can help models solve tasks more correctly when queries are under-specified, it brings minimal benefit when complex tools are broken.
CowPilot: A Framework for Autonomous and Human-Agent Collaborative Web Navigation
Jan 28, 2025



While much work on web agents emphasizes the promise of autonomously performing tasks on behalf of users, in reality, agents often fall short on complex tasks in real-world contexts and modeling user preference. This presents an opportunity for humans to collaborate with the agent and leverage the agent's capabilities effectively. We propose CowPilot, a framework supporting autonomous as well as human-agent collaborative web navigation, and evaluation across task success and task efficiency. CowPilot reduces the number of steps humans need to perform by allowing agents to propose next steps, while users are able to pause, reject, or take alternative actions. During execution, users can interleave their actions with the agent by overriding suggestions or resuming agent control when needed. We conducted case studies on five common websites and found that the human-agent collaborative mode achieves the highest success rate of 95% while requiring humans to perform only 15.2% of the total steps. Even with human interventions during task execution, the agent successfully drives up to half of task success on its own. CowPilot can serve as a useful tool for data collection and agent evaluation across websites, which we believe will enable research in how users and agents can work together. Video demonstrations are available at https://oaishi.github.io/cowpilot.html
AutoPresent: Designing Structured Visuals from Scratch
Jan 01, 2025
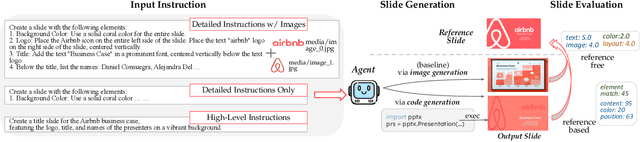
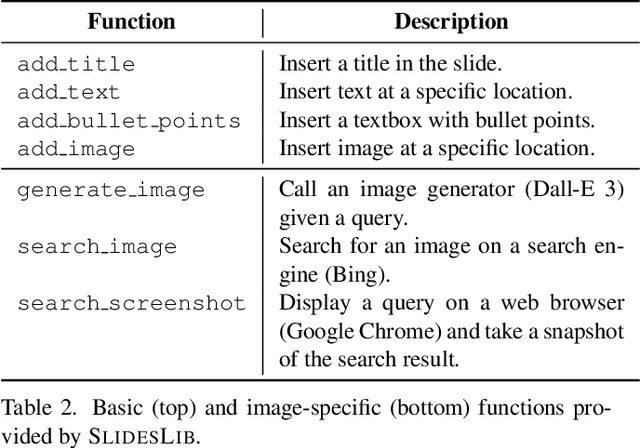
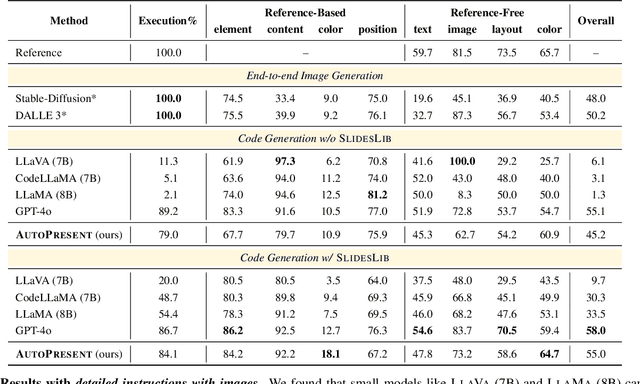
Designing structured visuals such as presentation slides is essential for communicative needs, necessitating both content creation and visual planning skills. In this work, we tackle the challenge of automated slide generation, where models produce slide presentations from natural language (NL) instructions. We first introduce the SlidesBench benchmark, the first benchmark for slide generation with 7k training and 585 testing examples derived from 310 slide decks across 10 domains. SlidesBench supports evaluations that are (i)reference-based to measure similarity to a target slide, and (ii)reference-free to measure the design quality of generated slides alone. We benchmark end-to-end image generation and program generation methods with a variety of models, and find that programmatic methods produce higher-quality slides in user-interactable formats. Built on the success of program generation, we create AutoPresent, an 8B Llama-based model trained on 7k pairs of instructions paired with code for slide generation, and achieve results comparable to the closed-source model GPT-4o. We further explore iterative design refinement where the model is tasked to self-refine its own output, and we found that this process improves the slide's quality. We hope that our work will provide a basis for future work on generating structured visuals.