 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDon't Let It Hallucinate: Premise Verification via Retrieval-Augmented Logical Reasoning
Apr 08, 2025Large language models (LLMs) have shown substantial capacity for generating fluent, contextually appropriate responses. However, they can produce hallucinated outputs, especially when a user query includes one or more false premises-claims that contradict established facts. Such premises can mislead LLMs into offering fabricated or misleading details. Existing approaches include pretraining, fine-tuning, and inference-time techniques that often rely on access to logits or address hallucinations after they occur. These methods tend to be computationally expensive, require extensive training data, or lack proactive mechanisms to prevent hallucination before generation, limiting their efficiency in real-time applications. We propose a retrieval-based framework that identifies and addresses false premises before generation. Our method first transforms a user's query into a logical representation, then applies retrieval-augmented generation (RAG) to assess the validity of each premise using factual sources. Finally, we incorporate the verification results into the LLM's prompt to maintain factual consistency in the final output. Experiments show that this approach effectively reduces hallucinations, improves factual accuracy, and does not require access to model logits or large-scale fine-tuning.
The Semantic Hub Hypothesis: Language Models Share Semantic Representations Across Languages and Modalities
Nov 07, 2024
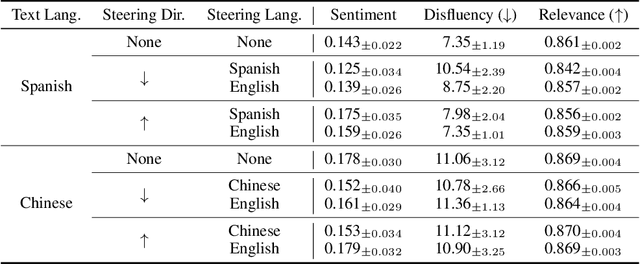
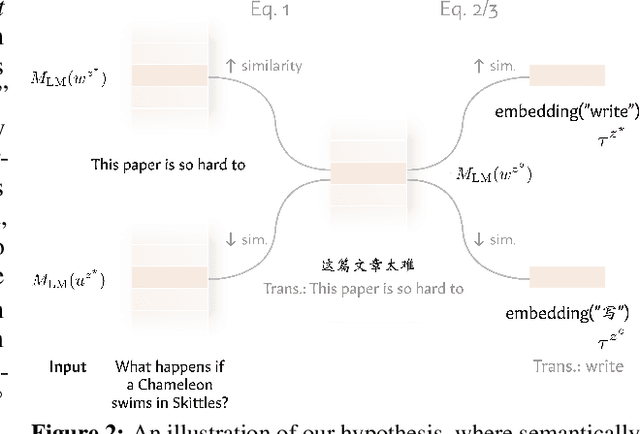
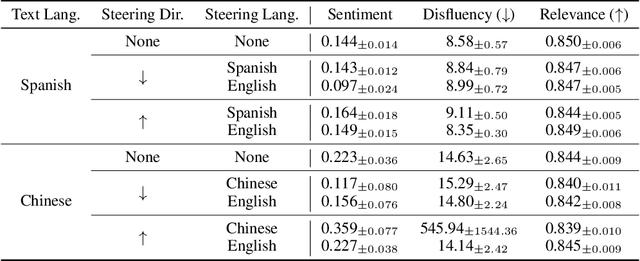
Modern language models can process inputs across diverse languages and modalities. We hypothesize that models acquire this capability through learning a shared representation space across heterogeneous data types (e.g., different languages and modalities), which places semantically similar inputs near one another, even if they are from different modalities/languages. We term this the semantic hub hypothesis, following the hub-and-spoke model from neuroscience (Patterson et al., 2007) which posits that semantic knowledge in the human brain is organized through a transmodal semantic "hub" which integrates information from various modality-specific "spokes" regions. We first show that model representations for semantically equivalent inputs in different languages are similar in the intermediate layers, and that this space can be interpreted using the model's dominant pretraining language via the logit lens. This tendency extends to other data types, including arithmetic expressions, code, and visual/audio inputs. Interventions in the shared representation space in one data type also predictably affect model outputs in other data types, suggesting that this shared representations space is not simply a vestigial byproduct of large-scale training on broad data, but something that is actively utilized by the model during input processing.
CodeRAG-Bench: Can Retrieval Augment Code Generation?
Jun 20, 2024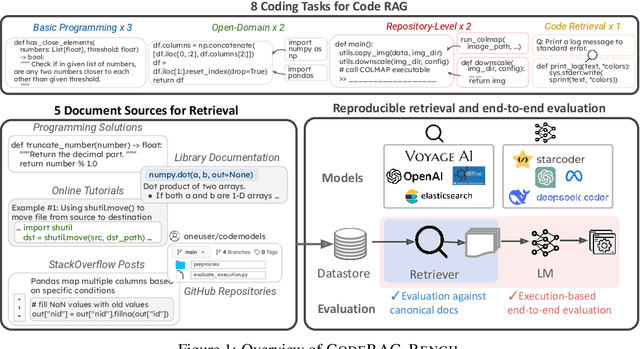
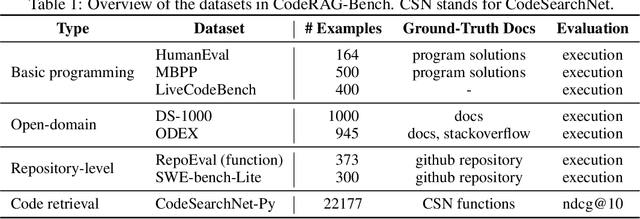
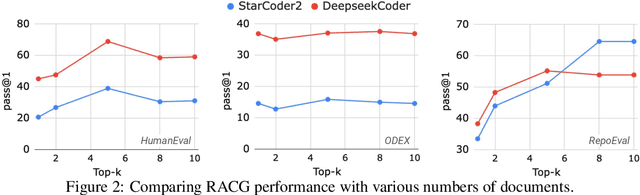
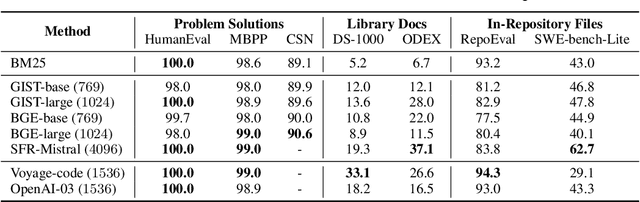
While language models (LMs) have proven remarkably adept at generating code, many programs are challenging for LMs to generate using their parametric knowledge alone. Providing external contexts such as library documentation can facilitate generating accurate and functional code. Despite the success of retrieval-augmented generation (RAG) in various text-oriented tasks, its potential for improving code generation remains under-explored. In this work, we conduct a systematic, large-scale analysis by asking: in what scenarios can retrieval benefit code generation models? and what challenges remain? We first curate a comprehensive evaluation benchmark, CodeRAG-Bench, encompassing three categories of code generation tasks, including basic programming, open-domain, and repository-level problems. We aggregate documents from five sources for models to retrieve contexts: competition solutions, online tutorials, library documentation, StackOverflow posts, and GitHub repositories. We examine top-performing models on CodeRAG-Bench by providing contexts retrieved from one or multiple sources. While notable gains are made in final code generation by retrieving high-quality contexts across various settings, our analysis reveals room for improvement -- current retrievers still struggle to fetch useful contexts especially with limited lexical overlap, and generators fail to improve with limited context lengths or abilities to integrate additional contexts. We hope CodeRAG-Bench serves as an effective testbed to encourage further development of advanced code-oriented RAG methods.
Principled Gradient-based Markov Chain Monte Carlo for Text Generation
Dec 29, 2023Recent papers have demonstrated the possibility of energy-based text generation by adapting gradient-based sampling algorithms, a paradigm of MCMC algorithms that promises fast convergence. However, as we show in this paper, previous attempts on this approach to text generation all fail to sample correctly from the target language model distributions. To address this limitation, we consider the problem of designing text samplers that are faithful, meaning that they have the target text distribution as its limiting distribution. We propose several faithful gradient-based sampling algorithms to sample from the target energy-based text distribution correctly, and study their theoretical properties. Through experiments on various forms of text generation, we demonstrate that faithful samplers are able to generate more fluent text while adhering to the control objectives better.
On Retrieval Augmentation and the Limitations of Language Model Training
Nov 16, 2023Augmenting a language model (LM) with $k$-nearest neighbors (kNN) retrieval on its training data alone can decrease its perplexity, though the underlying reasons for this remains elusive. In this work, we first rule out one previously posited possibility -- the "softmax bottleneck." We further identify the MLP hurdle phenomenon, where the final MLP layer in LMs may impede LM optimization early on. We explore memorization and generalization in language models with two new datasets, where advanced model like GPT-3.5-turbo find generalizing to irrelevant information in the training data challenging. However, incorporating kNN retrieval to vanilla GPT-2 117M can consistently improve performance in this setting.
BUFFET: Benchmarking Large Language Models for Few-shot Cross-lingual Transfer
May 24, 2023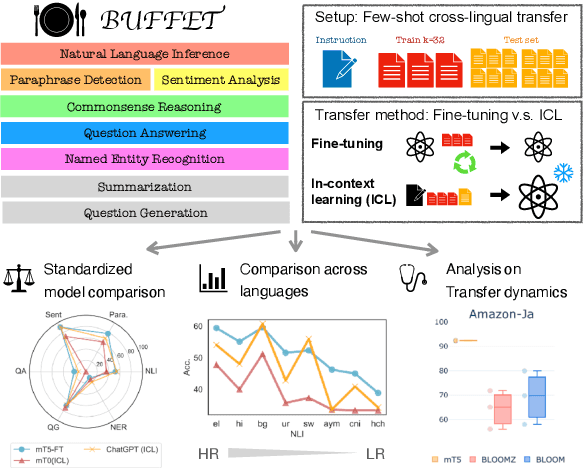
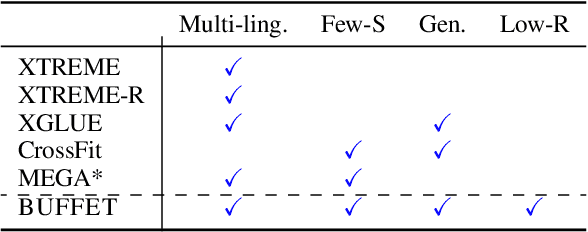
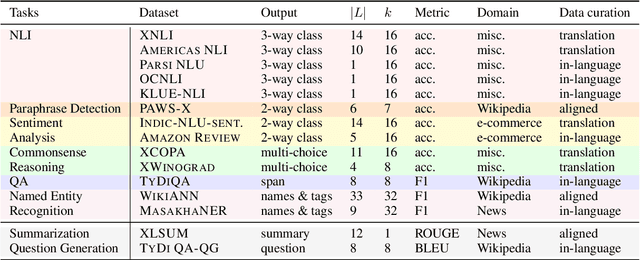
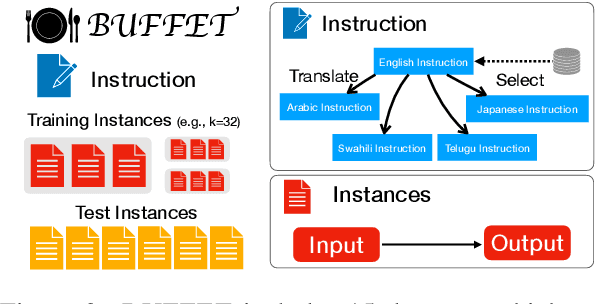
Despite remarkable advancements in few-shot generalization in natural language processing, most models are developed and evaluated primarily in English. To facilitate research on few-shot cross-lingual transfer, we introduce a new benchmark, called BUFFET, which unifies 15 diverse tasks across 54 languages in a sequence-to-sequence format and provides a fixed set of few-shot examples and instructions. BUFFET is designed to establish a rigorous and equitable evaluation framework for few-shot cross-lingual transfer across a broad range of tasks and languages. Using BUFFET, we perform thorough evaluations of state-of-the-art multilingual large language models with different transfer methods, namely in-context learning and fine-tuning. Our findings reveal significant room for improvement in few-shot in-context cross-lingual transfer. In particular, ChatGPT with in-context learning often performs worse than much smaller mT5-base models fine-tuned on English task data and few-shot in-language examples. Our analysis suggests various avenues for future research in few-shot cross-lingual transfer, such as improved pretraining, understanding, and future evaluations.
MURMUR: Modular Multi-Step Reasoning for Semi-Structured Data-to-Text Generation
Dec 16, 2022



Prompting large language models has enabled significant recent progress in multi-step reasoning over text. However, when applied to text generation from semi-structured data (e.g., graphs or tables), these methods typically suffer from low semantic coverage, hallucination, and logical inconsistency. We propose MURMUR, a neuro-symbolic modular approach to text generation from semi-structured data with multi-step reasoning. MURMUR is a best-first search method that generates reasoning paths using: (1) neural and symbolic modules with specific linguistic and logical skills, (2) a grammar whose production rules define valid compositions of modules, and (3) value functions that assess the quality of each reasoning step. We conduct experiments on two diverse data-to-text generation tasks like WebNLG and LogicNLG. These tasks differ in their data representations (graphs and tables) and span multiple linguistic and logical skills. MURMUR obtains significant improvements over recent few-shot baselines like direct prompting and chain-of-thought prompting, while also achieving comparable performance to fine-tuned GPT-2 on out-of-domain data. Moreover, human evaluation shows that MURMUR generates highly faithful and correct reasoning paths that lead to 26% more logically consistent summaries on LogicNLG, compared to direct prompting.
CREPE: Open-Domain Question Answering with False Presuppositions
Nov 30, 2022Information seeking users often pose questions with false presuppositions, especially when asking about unfamiliar topics. Most existing question answering (QA) datasets, in contrast, assume all questions have well defined answers. We introduce CREPE, a QA dataset containing a natural distribution of presupposition failures from online information-seeking forums. We find that 25% of questions contain false presuppositions, and provide annotations for these presuppositions and their corrections. Through extensive baseline experiments, we show that adaptations of existing open-domain QA models can find presuppositions moderately well, but struggle when predicting whether a presupposition is factually correct. This is in large part due to difficulty in retrieving relevant evidence passages from a large text corpus. CREPE provides a benchmark to study question answering in the wild, and our analyses provide avenues for future work in better modeling and further studying the task.
Beyond Counting Datasets: A Survey of Multilingual Dataset Construction and Necessary Resources
Nov 28, 2022While the NLP community is generally aware of resource disparities among languages, we lack research that quantifies the extent and types of such disparity. Prior surveys estimating the availability of resources based on the number of datasets can be misleading as dataset quality varies: many datasets are automatically induced or translated from English data. To provide a more comprehensive picture of language resources, we examine the characteristics of 156 publicly available NLP datasets. We manually annotate how they are created, including input text and label sources and tools used to build them, and what they study, tasks they address and motivations for their creation. After quantifying the qualitative NLP resource gap across languages, we discuss how to improve data collection in low-resource languages. We survey language-proficient NLP researchers and crowd workers per language, finding that their estimated availability correlates with dataset availability. Through crowdsourcing experiments, we identify strategies for collecting high-quality multilingual data on the Mechanical Turk platform. We conclude by making macro and micro-level suggestions to the NLP community and individual researchers for future multilingual data development.