 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCowPilot: A Framework for Autonomous and Human-Agent Collaborative Web Navigation
Jan 28, 2025



While much work on web agents emphasizes the promise of autonomously performing tasks on behalf of users, in reality, agents often fall short on complex tasks in real-world contexts and modeling user preference. This presents an opportunity for humans to collaborate with the agent and leverage the agent's capabilities effectively. We propose CowPilot, a framework supporting autonomous as well as human-agent collaborative web navigation, and evaluation across task success and task efficiency. CowPilot reduces the number of steps humans need to perform by allowing agents to propose next steps, while users are able to pause, reject, or take alternative actions. During execution, users can interleave their actions with the agent by overriding suggestions or resuming agent control when needed. We conducted case studies on five common websites and found that the human-agent collaborative mode achieves the highest success rate of 95% while requiring humans to perform only 15.2% of the total steps. Even with human interventions during task execution, the agent successfully drives up to half of task success on its own. CowPilot can serve as a useful tool for data collection and agent evaluation across websites, which we believe will enable research in how users and agents can work together. Video demonstrations are available at https://oaishi.github.io/cowpilot.html
TheAgentCompany: Benchmarking LLM Agents on Consequential Real World Tasks
Dec 18, 2024We interact with computers on an everyday basis, be it in everyday life or work, and many aspects of work can be done entirely with access to a computer and the Internet. At the same time, thanks to improvements in large language models (LLMs), there has also been a rapid development in AI agents that interact with and affect change in their surrounding environments. But how performant are AI agents at helping to accelerate or even autonomously perform work-related tasks? The answer to this question has important implications for both industry looking to adopt AI into their workflows, and for economic policy to understand the effects that adoption of AI may have on the labor market. To measure the progress of these LLM agents' performance on performing real-world professional tasks, in this paper, we introduce TheAgentCompany, an extensible benchmark for evaluating AI agents that interact with the world in similar ways to those of a digital worker: by browsing the Web, writing code, running programs, and communicating with other coworkers. We build a self-contained environment with internal web sites and data that mimics a small software company environment, and create a variety of tasks that may be performed by workers in such a company. We test baseline agents powered by both closed API-based and open-weights language models (LMs), and find that with the most competitive agent, 24% of the tasks can be completed autonomously. This paints a nuanced picture on task automation with LM agents -- in a setting simulating a real workplace, a good portion of simpler tasks could be solved autonomously, but more difficult long-horizon tasks are still beyond the reach of current systems.
The BrowserGym Ecosystem for Web Agent Research
Dec 10, 2024



The BrowserGym ecosystem addresses the growing need for efficient evaluation and benchmarking of web agents, particularly those leveraging automation and Large Language Models (LLMs) for web interaction tasks. Many existing benchmarks suffer from fragmentation and inconsistent evaluation methodologies, making it challenging to achieve reliable comparisons and reproducible results. BrowserGym aims to solve this by providing a unified, gym-like environment with well-defined observation and action spaces, facilitating standardized evaluation across diverse benchmarks. Combined with AgentLab, a complementary framework that aids in agent creation, testing, and analysis, BrowserGym offers flexibility for integrating new benchmarks while ensuring consistent evaluation and comprehensive experiment management. This standardized approach seeks to reduce the time and complexity of developing web agents, supporting more reliable comparisons and facilitating in-depth analysis of agent behaviors, and could result in more adaptable, capable agents, ultimately accelerating innovation in LLM-driven automation. As a supporting evidence, we conduct the first large-scale, multi-benchmark web agent experiment and compare the performance of 6 state-of-the-art LLMs across all benchmarks currently available in BrowserGym. Among other findings, our results highlight a large discrepancy between OpenAI and Anthropic's latests models, with Claude-3.5-Sonnet leading the way on almost all benchmarks, except on vision-related tasks where GPT-4o is superior. Despite these advancements, our results emphasize that building robust and efficient web agents remains a significant challenge, due to the inherent complexity of real-world web environments and the limitations of current models.
OpenDevin: An Open Platform for AI Software Developers as Generalist Agents
Jul 23, 2024



Software is one of the most powerful tools that we humans have at our disposal; it allows a skilled programmer to interact with the world in complex and profound ways. At the same time, thanks to improvements in large language models (LLMs), there has also been a rapid development in AI agents that interact with and affect change in their surrounding environments. In this paper, we introduce OpenDevin, a platform for the development of powerful and flexible AI agents that interact with the world in similar ways to those of a human developer: by writing code, interacting with a command line, and browsing the web. We describe how the platform allows for the implementation of new agents, safe interaction with sandboxed environments for code execution, coordination between multiple agents, and incorporation of evaluation benchmarks. Based on our currently incorporated benchmarks, we perform an evaluation of agents over 15 challenging tasks, including software engineering (e.g., SWE-Bench) and web browsing (e.g., WebArena), among others. Released under the permissive MIT license, OpenDevin is a community project spanning academia and industry with more than 1.3K contributions from over 160 contributors and will improve going forward.
CodeRAG-Bench: Can Retrieval Augment Code Generation?
Jun 20, 2024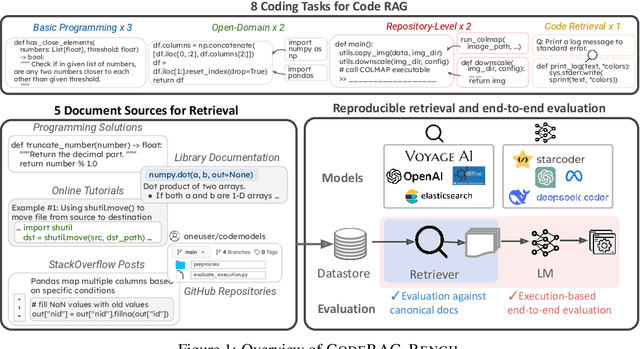
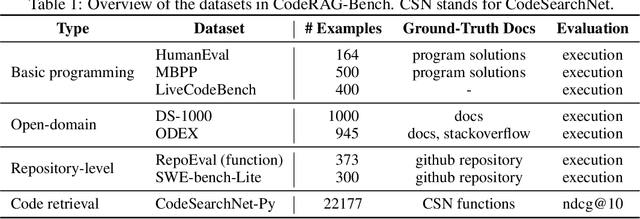
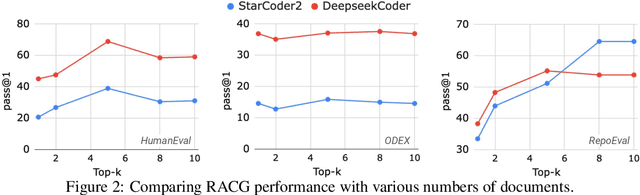
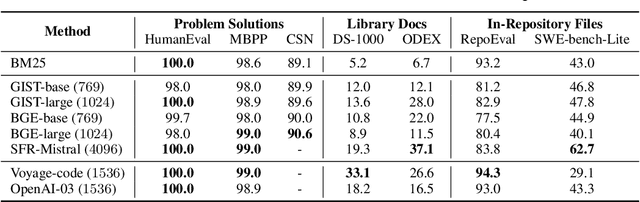
While language models (LMs) have proven remarkably adept at generating code, many programs are challenging for LMs to generate using their parametric knowledge alone. Providing external contexts such as library documentation can facilitate generating accurate and functional code. Despite the success of retrieval-augmented generation (RAG) in various text-oriented tasks, its potential for improving code generation remains under-explored. In this work, we conduct a systematic, large-scale analysis by asking: in what scenarios can retrieval benefit code generation models? and what challenges remain? We first curate a comprehensive evaluation benchmark, CodeRAG-Bench, encompassing three categories of code generation tasks, including basic programming, open-domain, and repository-level problems. We aggregate documents from five sources for models to retrieve contexts: competition solutions, online tutorials, library documentation, StackOverflow posts, and GitHub repositories. We examine top-performing models on CodeRAG-Bench by providing contexts retrieved from one or multiple sources. While notable gains are made in final code generation by retrieving high-quality contexts across various settings, our analysis reveals room for improvement -- current retrievers still struggle to fetch useful contexts especially with limited lexical overlap, and generators fail to improve with limited context lengths or abilities to integrate additional contexts. We hope CodeRAG-Bench serves as an effective testbed to encourage further development of advanced code-oriented RAG methods.
WebArena: A Realistic Web Environment for Building Autonomous Agents
Jul 25, 2023



With generative AI advances, the exciting potential for autonomous agents to manage daily tasks via natural language commands has emerged. However, cur rent agents are primarily created and tested in simplified synthetic environments, substantially limiting real-world scenario representation. In this paper, we build an environment for agent command and control that is highly realistic and reproducible. Specifically, we focus on agents that perform tasks on websites, and we create an environment with fully functional websites from four common domains: e-commerce, social forum discussions, collaborative software development, and content management. Our environment is enriched with tools (e.g., a map) and external knowledge bases (e.g., user manuals) to encourage human-like task-solving. Building upon our environment, we release a set of benchmark tasks focusing on evaluating the functional correctness of task completions. The tasks in our benchmark are diverse, long-horizon, and are designed to emulate tasks that humans routinely perform on the internet. We design and implement several autonomous agents, integrating recent techniques such as reasoning before acting. The results demonstrate that solving complex tasks is challenging: our best GPT-4-based agent only achieves an end-to-end task success rate of 10.59%. These results highlight the need for further development of robust agents, that current state-of-the-art LMs are far from perfect performance in these real-life tasks, and that WebArena can be used to measure such progress. Our code, data, environment reproduction resources, and video demonstrations are publicly available at https://webarena.dev/.
Hierarchical Prompting Assists Large Language Model on Web Navigation
May 23, 2023Large language models (LLMs) struggle on processing complicated observations in interactive decision making. To alleviate this issue, we propose a simple hierarchical prompting approach. Diverging from previous prompting approaches that always put the \emph{full} observation~(\eg a web page) to the prompt, we propose to first construct an action-aware observation which is more \emph{condensed} and \emph{relevant} with a dedicated \summ prompt. The \actor prompt then predicts the next action based on the summarized history. While our method has broad applicability, we particularly demonstrate its efficacy in the complex domain of web navigation where a full observation often contains redundant and irrelevant information. Our approach outperforms the previous state-of-the-art prompting mechanism with the same LLM by 6.2\% on task success rate, demonstrating its potential on interactive decision making tasks with long observation traces.
Active Retrieval Augmented Generation
May 11, 2023

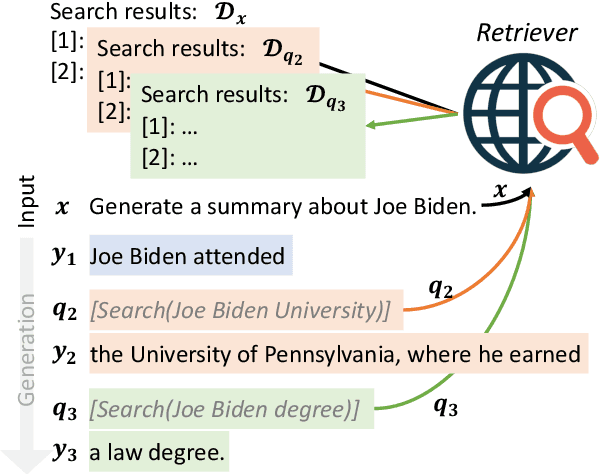

Despite the remarkable ability of large language models (LMs) to comprehend and generate language, they have a tendency to hallucinate and create factually inaccurate output. Augmenting LMs by retrieving information from external knowledge resources is one promising solution. Most existing retrieval-augmented LMs employ a retrieve-and-generate setup that only retrieves information once based on the input. This is limiting, however, in more general scenarios involving generation of long texts, where continually gathering information throughout the generation process is essential. There have been some past efforts to retrieve information multiple times while generating outputs, which mostly retrieve documents at fixed intervals using the previous context as queries. In this work, we provide a generalized view of active retrieval augmented generation, methods that actively decide when and what to retrieve across the course of the generation. We propose Forward-Looking Active REtrieval augmented generation (FLARE), a generic retrieval-augmented generation method which iteratively uses a prediction of the upcoming sentence to anticipate future content, which is then utilized as a query to retrieve relevant documents to regenerate the sentence if it contains low-confidence tokens. We test FLARE along with baselines comprehensively over 4 long-form knowledge-intensive generation tasks/datasets. FLARE achieves superior or competitive performance on all tasks, demonstrating the effectiveness of our method. Code and datasets are available at https://github.com/jzbjyb/FLARE.
Why do Nearest Neighbor Language Models Work?
Jan 17, 2023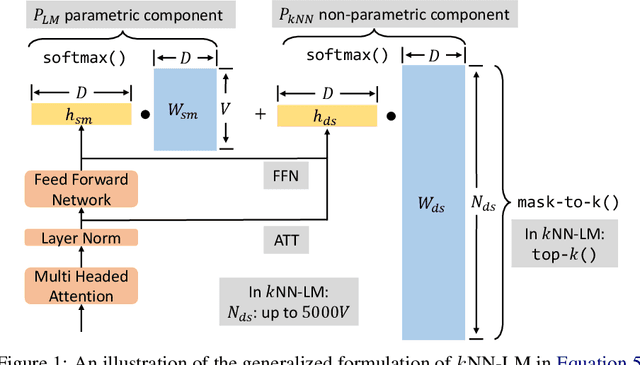


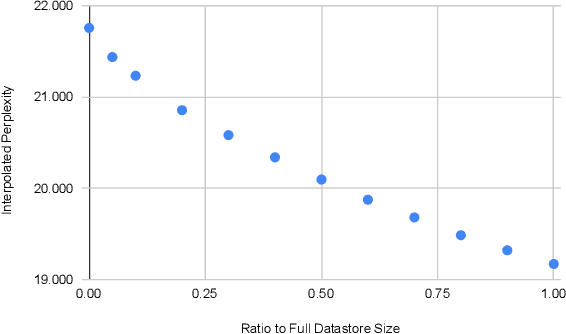
Language models (LMs) compute the probability of a text by sequentially computing a representation of an already-seen context and using this representation to predict the next word. Currently, most LMs calculate these representations through a neural network consuming the immediate previous context. However recently, retrieval-augmented LMs have shown to improve over standard neural LMs, by accessing information retrieved from a large datastore, in addition to their standard, parametric, next-word prediction. In this paper, we set out to understand why retrieval-augmented language models, and specifically why k-nearest neighbor language models (kNN-LMs) perform better than standard parametric LMs, even when the k-nearest neighbor component retrieves examples from the same training set that the LM was originally trained on. To this end, we perform a careful analysis of the various dimensions over which kNN-LM diverges from standard LMs, and investigate these dimensions one by one. Empirically, we identify three main reasons why kNN-LM performs better than standard LMs: using a different input representation for predicting the next tokens, approximate kNN search, and the importance of softmax temperature for the kNN distribution. Further, we incorporate these insights into the model architecture or the training procedure of the standard parametric LM, improving its results without the need for an explicit retrieval component. The code is available at https://github.com/frankxu2004/knnlm-why.
DocCoder: Generating Code by Retrieving and Reading Docs
Jul 13, 2022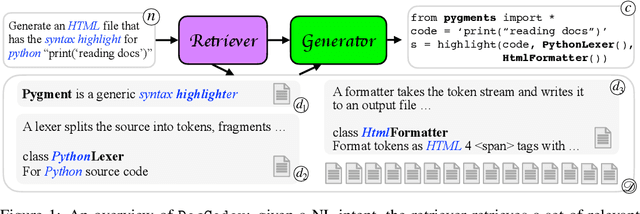
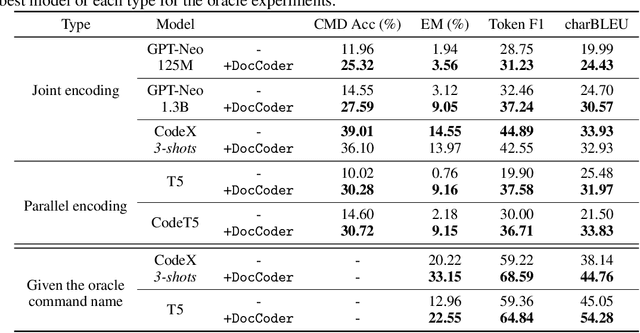
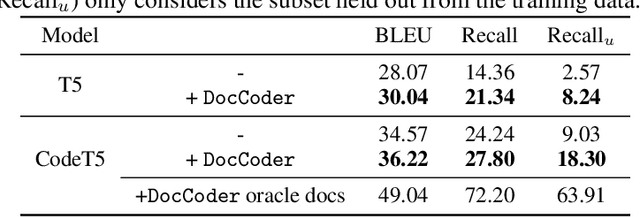
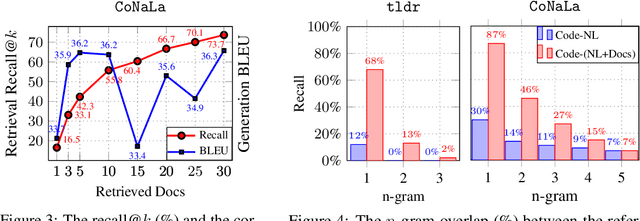
Natural-language-to-code models learn to generate a code snippet given a natural language (NL) intent. However, the rapid growth of both publicly available and proprietary libraries and functions makes it impossible to cover all APIs using training examples, as new libraries and functions are introduced daily. Thus, existing models inherently cannot generalize to using unseen functions and libraries merely through incorporating them into the training data. In contrast, when human programmers write programs, they frequently refer to textual resources such as code manuals, documentation, and tutorials, to explore and understand available library functionality. Inspired by this observation, we introduce DocCoder: an approach that explicitly leverages code manuals and documentation by (1) retrieving the relevant documentation given the NL intent, and (2) generating the code based on the NL intent and the retrieved documentation. Our approach is general, can be applied to any programming language, and is agnostic to the underlying neural model. We demonstrate that DocCoder consistently improves NL-to-code models: DocCoder achieves 11x higher exact match accuracy than strong baselines on a new Bash dataset tldr; on the popular Python CoNaLa benchmark, DocCoder improves over strong baselines by 1.65 BLEU.