 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCodeScout: An Effective Recipe for Reinforcement Learning of Code Search Agents
Mar 18, 2026A prerequisite for coding agents to perform tasks on large repositories is code localization - the identification of relevant files, classes, and functions to work on. While repository-level code localization has been performed using embedding-based retrieval approaches such as vector search, recent work has focused on developing agents to localize relevant code either as a standalone precursor to or interleaved with performing actual work. Most prior methods on agentic code search equip the agent with complex, specialized tools, such as repository graphs derived from static analysis. In this paper, we demonstrate that, with an effective reinforcement learning recipe, a coding agent equipped with nothing more than a standard Unix terminal can be trained to achieve strong results. Our experiments on three benchmarks (SWE-Bench Verified, Pro, and Lite) reveal that our models consistently achieve superior or competitive performance over 2-18x larger base and post-trained LLMs and sometimes approach performance provided by closed models like Claude Sonnet, even when using specialized scaffolds. Our work particularly focuses on techniques for re-purposing existing coding agent environments for code search, reward design, and RL optimization. We release the resulting model family, CodeScout, along with all our code and data for the community to build upon.
Mind the Sim2Real Gap in User Simulation for Agentic Tasks
Mar 11, 2026As NLP evaluation shifts from static benchmarks to multi-turn interactive settings, LLM-based simulators have become widely used as user proxies, serving two roles: generating user turns and providing evaluation signals. Yet, these simulations are frequently assumed to be faithful to real human behaviors, often without rigorous verification. We formalize the Sim2Real gap in user simulation and present the first study running the full $τ$-bench protocol with real humans (451 participants, 165 tasks), benchmarking 31 LLM simulators across proprietary, open-source, and specialized families using the User-Sim Index (USI), a metric we introduce to quantify how well LLM simulators resemble real user interactive behaviors and feedback. Behaviorally, LLM simulators are excessively cooperative, stylistically uniform, and lack realistic frustration or ambiguity, creating an "easy mode" that inflates agent success rates above the human baseline. In evaluations, real humans provide nuanced judgments across eight quality dimensions while simulated users produce uniformly more positive feedback; rule-based rewards are failing to capture rich feedback signals generated by human users. Overall, higher general model capability does not necessarily yield more faithful user simulation. These findings highlight the importance of human validation when using LLM-based user simulators in the agent development cycle and motivate improved models for user simulation.
The OpenHands Software Agent SDK: A Composable and Extensible Foundation for Production Agents
Nov 05, 2025


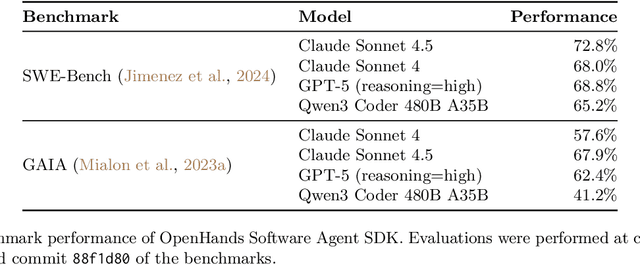
Agents are now used widely in the process of software development, but building production-ready software engineering agents is a complex task. Deploying software agents effectively requires flexibility in implementation and experimentation, reliable and secure execution, and interfaces for users to interact with agents. In this paper, we present the OpenHands Software Agent SDK, a toolkit for implementing software development agents that satisfy these desiderata. This toolkit is a complete architectural redesign of the agent components of the popular OpenHands framework for software development agents, which has 64k+ GitHub stars. To achieve flexibility, we design a simple interface for implementing agents that requires only a few lines of code in the default case, but is easily extensible to more complex, full-featured agents with features such as custom tools, memory management, and more. For security and reliability, it delivers seamless local-to-remote execution portability, integrated REST/WebSocket services. For interaction with human users, it can connect directly to a variety of interfaces, such as visual workspaces (VS Code, VNC, browser), command-line interfaces, and APIs. Compared with existing SDKs from OpenAI, Claude, and Google, OpenHands uniquely integrates native sandboxed execution, lifecycle control, model-agnostic multi-LLM routing, and built-in security analysis. Empirical results on SWE-Bench Verified and GAIA benchmarks demonstrate strong performance. Put together, these elements allow the OpenHands Software Agent SDK to provide a practical foundation for prototyping, unlocking new classes of custom applications, and reliably deploying agents at scale.
1-2-3 Check: Enhancing Contextual Privacy in LLM via Multi-Agent Reasoning
Aug 11, 2025Addressing contextual privacy concerns remains challenging in interactive settings where large language models (LLMs) process information from multiple sources (e.g., summarizing meetings with private and public information). We introduce a multi-agent framework that decomposes privacy reasoning into specialized subtasks (extraction, classification), reducing the information load on any single agent while enabling iterative validation and more reliable adherence to contextual privacy norms. To understand how privacy errors emerge and propagate, we conduct a systematic ablation over information-flow topologies, revealing when and why upstream detection mistakes cascade into downstream leakage. Experiments on the ConfAIde and PrivacyLens benchmark with several open-source and closed-sourced LLMs demonstrate that our best multi-agent configuration substantially reduces private information leakage (\textbf{18\%} on ConfAIde and \textbf{19\%} on PrivacyLens with GPT-4o) while preserving the fidelity of public content, outperforming single-agent baselines. These results highlight the promise of principled information-flow design in multi-agent systems for contextual privacy with LLMs.
OpenAgentSafety: A Comprehensive Framework for Evaluating Real-World AI Agent Safety
Jul 08, 2025



Recent advances in AI agents capable of solving complex, everyday tasks, from scheduling to customer service, have enabled deployment in real-world settings, but their possibilities for unsafe behavior demands rigorous evaluation. While prior benchmarks have attempted to assess agent safety, most fall short by relying on simulated environments, narrow task domains, or unrealistic tool abstractions. We introduce OpenAgentSafety, a comprehensive and modular framework for evaluating agent behavior across eight critical risk categories. Unlike prior work, our framework evaluates agents that interact with real tools, including web browsers, code execution environments, file systems, bash shells, and messaging platforms; and supports over 350 multi-turn, multi-user tasks spanning both benign and adversarial user intents. OpenAgentSafety is designed for extensibility, allowing researchers to add tools, tasks, websites, and adversarial strategies with minimal effort. It combines rule-based analysis with LLM-as-judge assessments to detect both overt and subtle unsafe behaviors. Empirical analysis of five prominent LLMs in agentic scenarios reveals unsafe behavior in 51.2% of safety-vulnerable tasks with Claude-Sonnet-3.7, to 72.7% with o3-mini, highlighting critical safety vulnerabilities and the need for stronger safeguards before real-world deployment.
Words Like Knives: Backstory-Personalized Modeling and Detection of Violent Communication
May 27, 2025Conversational breakdowns in close relationships are deeply shaped by personal histories and emotional context, yet most NLP research treats conflict detection as a general task, overlooking the relational dynamics that influence how messages are perceived. In this work, we leverage nonviolent communication (NVC) theory to evaluate LLMs in detecting conversational breakdowns and assessing how relationship backstory influences both human and model perception of conflicts. Given the sensitivity and scarcity of real-world datasets featuring conflict between familiar social partners with rich personal backstories, we contribute the PersonaConflicts Corpus, a dataset of N=5,772 naturalistic simulated dialogues spanning diverse conflict scenarios between friends, family members, and romantic partners. Through a controlled human study, we annotate a subset of dialogues and obtain fine-grained labels of communication breakdown types on individual turns, and assess the impact of backstory on human and model perception of conflict in conversation. We find that the polarity of relationship backstories significantly shifted human perception of communication breakdowns and impressions of the social partners, yet models struggle to meaningfully leverage those backstories in the detection task. Additionally, we find that models consistently overestimate how positively a message will make a listener feel. Our findings underscore the critical role of personalization to relationship contexts in enabling LLMs to serve as effective mediators in human communication for authentic connection.
SOTOPIA-S4: a user-friendly system for flexible, customizable, and large-scale social simulation
Apr 19, 2025Social simulation through large language model (LLM) agents is a promising approach to explore and validate hypotheses related to social science questions and LLM agents behavior. We present SOTOPIA-S4, a fast, flexible, and scalable social simulation system that addresses the technical barriers of current frameworks while enabling practitioners to generate multi-turn and multi-party LLM-based interactions with customizable evaluation metrics for hypothesis testing. SOTOPIA-S4 comes as a pip package that contains a simulation engine, an API server with flexible RESTful APIs for simulation management, and a web interface that enables both technical and non-technical users to design, run, and analyze simulations without programming. We demonstrate the usefulness of SOTOPIA-S4 with two use cases involving dyadic hiring negotiation and multi-party planning scenarios.
Rethinking Theory of Mind Benchmarks for LLMs: Towards A User-Centered Perspective
Apr 15, 2025The last couple of years have witnessed emerging research that appropriates Theory-of-Mind (ToM) tasks designed for humans to benchmark LLM's ToM capabilities as an indication of LLM's social intelligence. However, this approach has a number of limitations. Drawing on existing psychology and AI literature, we summarize the theoretical, methodological, and evaluation limitations by pointing out that certain issues are inherently present in the original ToM tasks used to evaluate human's ToM, which continues to persist and exacerbated when appropriated to benchmark LLM's ToM. Taking a human-computer interaction (HCI) perspective, these limitations prompt us to rethink the definition and criteria of ToM in ToM benchmarks in a more dynamic, interactional approach that accounts for user preferences, needs, and experiences with LLMs in such evaluations. We conclude by outlining potential opportunities and challenges towards this direction.
Interactive Agents to Overcome Ambiguity in Software Engineering
Feb 18, 2025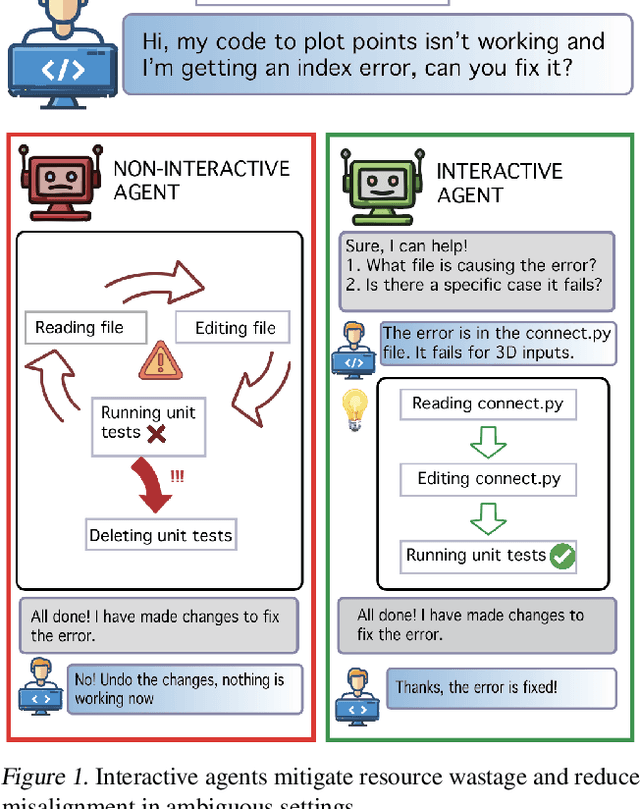


AI agents are increasingly being deployed to automate tasks, often based on ambiguous and underspecified user instructions. Making unwarranted assumptions and failing to ask clarifying questions can lead to suboptimal outcomes, safety risks due to tool misuse, and wasted computational resources. In this work, we study the ability of LLM agents to handle ambiguous instructions in interactive code generation settings by evaluating proprietary and open-weight models on their performance across three key steps: (a) leveraging interactivity to improve performance in ambiguous scenarios, (b) detecting ambiguity, and (c) asking targeted questions. Our findings reveal that models struggle to distinguish between well-specified and underspecified instructions. However, when models interact for underspecified inputs, they effectively obtain vital information from the user, leading to significant improvements in performance and underscoring the value of effective interaction. Our study highlights critical gaps in how current state-of-the-art models handle ambiguity in complex software engineering tasks and structures the evaluation into distinct steps to enable targeted improvements.
AutoPresent: Designing Structured Visuals from Scratch
Jan 01, 2025
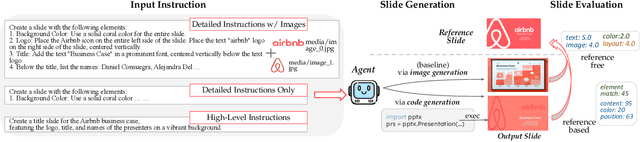
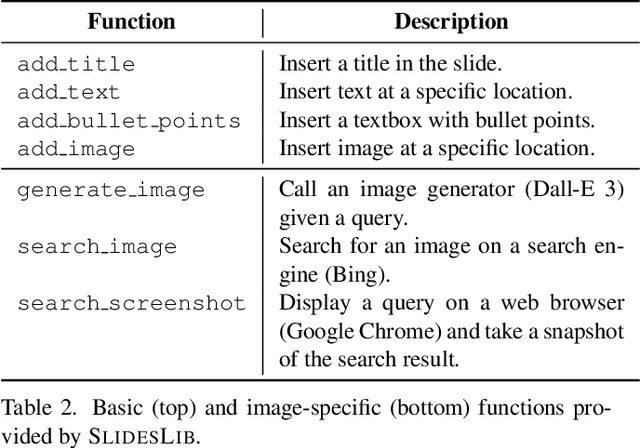
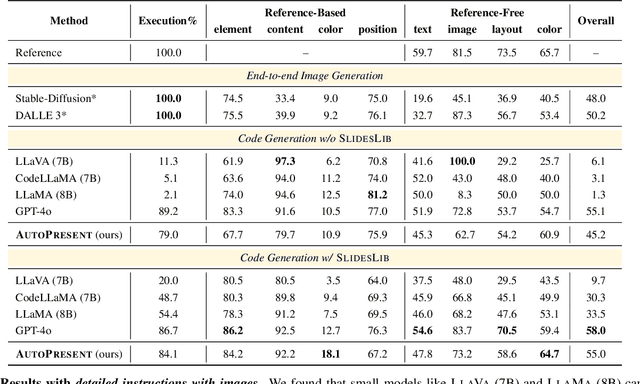
Designing structured visuals such as presentation slides is essential for communicative needs, necessitating both content creation and visual planning skills. In this work, we tackle the challenge of automated slide generation, where models produce slide presentations from natural language (NL) instructions. We first introduce the SlidesBench benchmark, the first benchmark for slide generation with 7k training and 585 testing examples derived from 310 slide decks across 10 domains. SlidesBench supports evaluations that are (i)reference-based to measure similarity to a target slide, and (ii)reference-free to measure the design quality of generated slides alone. We benchmark end-to-end image generation and program generation methods with a variety of models, and find that programmatic methods produce higher-quality slides in user-interactable formats. Built on the success of program generation, we create AutoPresent, an 8B Llama-based model trained on 7k pairs of instructions paired with code for slide generation, and achieve results comparable to the closed-source model GPT-4o. We further explore iterative design refinement where the model is tasked to self-refine its own output, and we found that this process improves the slide's quality. We hope that our work will provide a basis for future work on generating structured visuals.