 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDWTSumm: Discrete Wavelet Transform for Document Summarization
Apr 22, 2026Summarizing long, domain-specific documents with large language models (LLMs) remains challenging due to context limitations, information loss, and hallucinations, particularly in clinical and legal settings. We propose a Discrete Wavelet Transform (DWT)-based multi-resolution framework that treats text as a semantic signal and decomposes it into global (approximation) and local (detail) components. Applied to sentence- or word-level embeddings, DWT yields compact representations that preserve overall structure and critical domain-specific details, which are used directly as summaries or to guide LLM generation. Experiments on clinical and legal benchmarks demonstrate comparable ROUGE-L scores. Compared to a GPT-4o baseline, the DWT based summarization consistently improve semantic similarity and grounding, achieving gains of over 2% in BERTScore, more than 4\% in Semantic Fidelity, factual consistency in legal tasks, and large METEOR improvements indicative of preserved domain-specific semantics. Across multiple embedding models, Fidelity reaches up to 97%, suggesting that DWT acts as a semantic denoising mechanism that reduces hallucinations and strengthens factual grounding. Overall, DWT provides a lightweight, generalizable method for reliable long-document and domain-specific summarization with LLMs.
Personal Information Parroting in Language Models
Feb 24, 2026Modern language models (LM) are trained on large scrapes of the Web, containing millions of personal information (PI) instances, many of which LMs memorize, increasing privacy risks. In this work, we develop the regexes and rules (R&R) detector suite to detect email addresses, phone numbers, and IP addresses, which outperforms the best regex-based PI detectors. On a manually curated set of 483 instances of PI, we measure memorization: finding that 13.6% are parroted verbatim by the Pythia-6.9b model, i.e., when the model is prompted with the tokens that precede the PI in the original document, greedy decoding generates the entire PI span exactly. We expand this analysis to study models of varying sizes (160M-6.9B) and pretraining time steps (70k-143k iterations) in the Pythia model suite and find that both model size and amount of pretraining are positively correlated with memorization. Even the smallest model, Pythia-160m, parrots 2.7% of the instances exactly. Consequently, we strongly recommend that pretraining datasets be aggressively filtered and anonymized to minimize PI parroting.
Sentipolis: Emotion-Aware Agents for Social Simulations
Jan 25, 2026LLM agents are increasingly used for social simulation, yet emotion is often treated as a transient cue, causing emotional amnesia and weak long-horizon continuity. We present Sentipolis, a framework for emotionally stateful agents that integrates continuous Pleasure-Arousal-Dominance (PAD) representation, dual-speed emotion dynamics, and emotion--memory coupling. Across thousands of interactions over multiple base models and evaluators, Sentipolis improves emotionally grounded behavior, boosting communication, and emotional continuity. Gains are model-dependent: believability increases for higher-capacity models but can drop for smaller ones, and emotion-awareness can mildly reduce adherence to social norms, reflecting a human-like tension between emotion-driven behavior and rule compliance in social simulation. Network-level diagnostics show reciprocal, moderately clustered, and temporally stable relationship structures, supporting the study of cumulative social dynamics such as alliance formation and gradual relationship change.
StressRoBERTa: Cross-Condition Transfer Learning from Depression, Anxiety, and PTSD to Stress Detection
Dec 29, 2025The prevalence of chronic stress represents a significant public health concern, with social media platforms like Twitter serving as important venues for individuals to share their experiences. This paper introduces StressRoBERTa, a cross-condition transfer learning approach for automatic detection of self-reported chronic stress in English tweets. The investigation examines whether continual training on clinically related conditions (depression, anxiety, PTSD), disorders with high comorbidity with chronic stress, improves stress detection compared to general language models and broad mental health models. RoBERTa is continually trained on the Stress-SMHD corpus (108M words from users with self-reported diagnoses of depression, anxiety, and PTSD) and fine-tuned on the SMM4H 2022 Task 8 dataset. StressRoBERTa achieves 82% F1-score, outperforming the best shared task system (79% F1) by 3 percentage points. The results demonstrate that focused cross-condition transfer from stress-related disorders (+1% F1 over vanilla RoBERTa) provides stronger representations than general mental health training. Evaluation on Dreaddit (81% F1) further demonstrates transfer from clinical mental health contexts to situational stress discussions.
Taming Object Hallucinations with Verified Atomic Confidence Estimation
Nov 12, 2025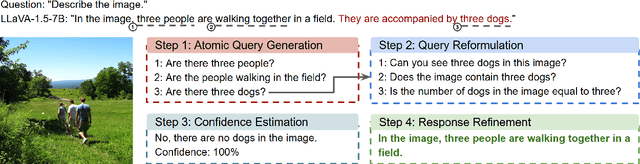

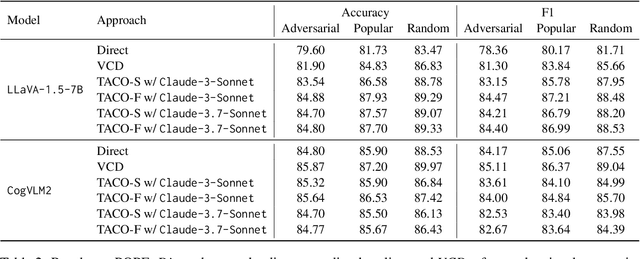
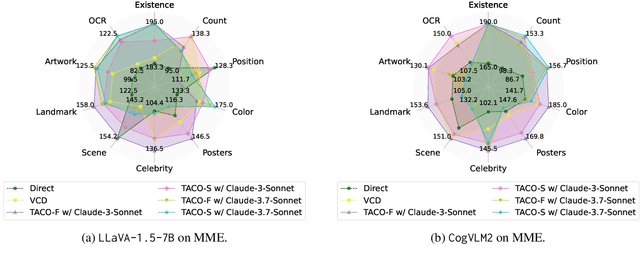
Multimodal Large Language Models (MLLMs) often suffer from hallucinations, particularly errors in object existence, attributes, or relations, which undermine their reliability. We introduce TACO (Verified Atomic Confidence Estimation), a simple framework that mitigates hallucinations through self-verification and confidence calibration without relying on external vision experts. TACO decomposes responses into atomic queries, paraphrases them to reduce sensitivity to wording, and estimates confidence using self-consistency (black-box) or self-confidence (gray-box) aggregation, before refining answers with a language model. Experiments on five benchmarks (POPE, MME, HallusionBench, AMBER, and MM-Hal Bench) with two MLLMs (\texttt{LLaVA-1.5-7B} and \texttt{CogVLM2}) show that TACO consistently outperforms direct prompting and Visual Contrastive Decoding, reduces systematic biases, and improves confidence calibration, demonstrating its effectiveness in enhancing the faithfulness of MLLMs.
Semantic Compression for Word and Sentence Embeddings using Discrete Wavelet Transform
Jul 31, 2025Wavelet transforms, a powerful mathematical tool, have been widely used in different domains, including Signal and Image processing, to unravel intricate patterns, enhance data representation, and extract meaningful features from data. Tangible results from their application suggest that Wavelet transforms can be applied to NLP capturing a variety of linguistic and semantic properties. In this paper, we empirically leverage the application of Discrete Wavelet Transforms (DWT) to word and sentence embeddings. We aim to showcase the capabilities of DWT in analyzing embedding representations at different levels of resolution and compressing them while maintaining their overall quality. We assess the effectiveness of DWT embeddings on semantic similarity tasks to show how DWT can be used to consolidate important semantic information in an embedding vector. We show the efficacy of the proposed paradigm using different embedding models, including large language models, on downstream tasks. Our results show that DWT can reduce the dimensionality of embeddings by 50-93% with almost no change in performance for semantic similarity tasks, while achieving superior accuracy in most downstream tasks. Our findings pave the way for applying DWT to improve NLP applications.
Synthetic Socratic Debates: Examining Persona Effects on Moral Decision and Persuasion Dynamics
Jun 14, 2025As large language models (LLMs) are increasingly used in morally sensitive domains, it is crucial to understand how persona traits affect their moral reasoning and persuasive behavior. We present the first large-scale study of multi-dimensional persona effects in AI-AI debates over real-world moral dilemmas. Using a 6-dimensional persona space (age, gender, country, class, ideology, and personality), we simulate structured debates between AI agents over 131 relationship-based cases. Our results show that personas affect initial moral stances and debate outcomes, with political ideology and personality traits exerting the strongest influence. Persuasive success varies across traits, with liberal and open personalities reaching higher consensus and win rates. While logit-based confidence grows during debates, emotional and credibility-based appeals diminish, indicating more tempered argumentation over time. These trends mirror findings from psychology and cultural studies, reinforcing the need for persona-aware evaluation frameworks for AI moral reasoning.
Biases Propagate in Encoder-based Vision-Language Models: A Systematic Analysis From Intrinsic Measures to Zero-shot Retrieval Outcomes
Jun 06, 2025To build fair AI systems we need to understand how social-group biases intrinsic to foundational encoder-based vision-language models (VLMs) manifest in biases in downstream tasks. In this study, we demonstrate that intrinsic biases in VLM representations systematically ``carry over'' or propagate into zero-shot retrieval tasks, revealing how deeply rooted biases shape a model's outputs. We introduce a controlled framework to measure this propagation by correlating (a) intrinsic measures of bias in the representational space with (b) extrinsic measures of bias in zero-shot text-to-image (TTI) and image-to-text (ITT) retrieval. Results show substantial correlations between intrinsic and extrinsic bias, with an average $\rho$ = 0.83 $\pm$ 0.10. This pattern is consistent across 114 analyses, both retrieval directions, six social groups, and three distinct VLMs. Notably, we find that larger/better-performing models exhibit greater bias propagation, a finding that raises concerns given the trend towards increasingly complex AI models. Our framework introduces baseline evaluation tasks to measure the propagation of group and valence signals. Investigations reveal that underrepresented groups experience less robust propagation, further skewing their model-related outcomes.
SAEs $\textit{Can}$ Improve Unlearning: Dynamic Sparse Autoencoder Guardrails for Precision Unlearning in LLMs
Apr 11, 2025



Machine unlearning is a promising approach to improve LLM safety by removing unwanted knowledge from the model. However, prevailing gradient-based unlearning methods suffer from issues such as high computational costs, hyperparameter instability, poor sequential unlearning capability, vulnerability to relearning attacks, low data efficiency, and lack of interpretability. While Sparse Autoencoders are well-suited to improve these aspects by enabling targeted activation-based unlearning, prior approaches underperform gradient-based methods. This work demonstrates that, contrary to these earlier findings, SAEs can significantly improve unlearning when employed dynamically. We introduce $\textbf{Dynamic DAE Guardrails}$ (DSG), a novel method for precision unlearning that leverages principled feature selection and a dynamic classifier. Our experiments show DSG substantially outperforms leading unlearning methods, achieving superior forget-utility trade-offs. DSG addresses key drawbacks of gradient-based approaches for unlearning -- offering enhanced computational efficiency and stability, robust performance in sequential unlearning, stronger resistance to relearning attacks, better data efficiency including zero-shot settings, and more interpretable unlearning.
CoRAG: Collaborative Retrieval-Augmented Generation
Apr 02, 2025



Retrieval-Augmented Generation (RAG) models excel in knowledge-intensive tasks, especially under few-shot learning constraints. We introduce CoRAG, a framework extending RAG to collaborative settings, where clients jointly train a shared model using a collaborative passage store. To evaluate CoRAG, we introduce CRAB, a benchmark for collaborative homogeneous open-domain question answering. Our experiments demonstrate that CoRAG consistently outperforms both parametric collaborative learning methods and locally trained RAG models in low-resource scenarios. Further analysis reveals the critical importance of relevant passages within the shared store, the surprising benefits of incorporating irrelevant passages, and the potential for hard negatives to negatively impact performance. This introduces a novel consideration in collaborative RAG: the trade-off between leveraging a collectively enriched knowledge base and the potential risk of incorporating detrimental passages from other clients. Our findings underscore the viability of CoRAG, while also highlighting key design challenges and promising avenues for future research.