 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHalluSearch at SemEval-2025 Task 3: A Search-Enhanced RAG Pipeline for Hallucination Detection
Apr 14, 2025

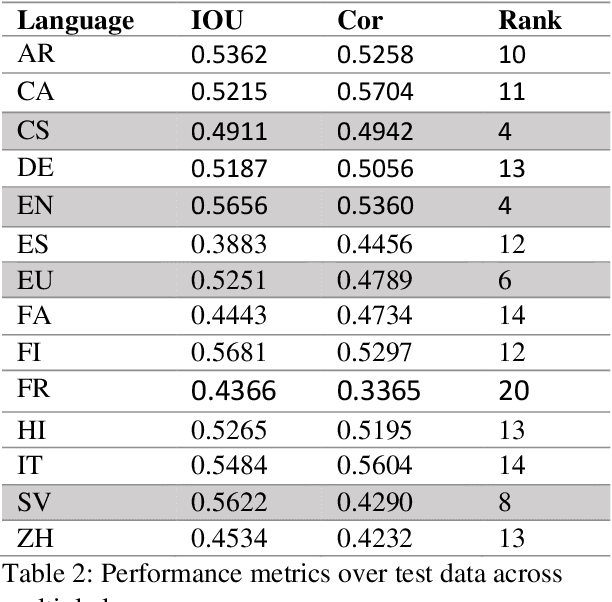
In this paper, we present HalluSearch, a multilingual pipeline designed to detect fabricated text spans in Large Language Model (LLM) outputs. Developed as part of Mu-SHROOM, the Multilingual Shared-task on Hallucinations and Related Observable Overgeneration Mistakes, HalluSearch couples retrieval-augmented verification with fine-grained factual splitting to identify and localize hallucinations in fourteen different languages. Empirical evaluations show that HalluSearch performs competitively, placing fourth in both English (within the top ten percent) and Czech. While the system's retrieval-based strategy generally proves robust, it faces challenges in languages with limited online coverage, underscoring the need for further research to ensure consistent hallucination detection across diverse linguistic contexts.
Exploring Retrieval Augmented Generation in Arabic
Aug 14, 2024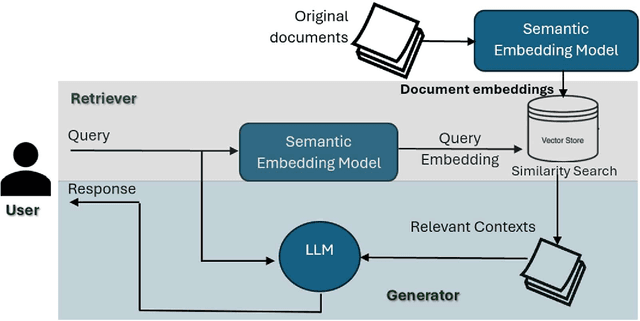



Recently, Retrieval Augmented Generation (RAG) has emerged as a powerful technique in natural language processing, combining the strengths of retrieval-based and generation-based models to enhance text generation tasks. However, the application of RAG in Arabic, a language with unique characteristics and resource constraints, remains underexplored. This paper presents a comprehensive case study on the implementation and evaluation of RAG for Arabic text. The work focuses on exploring various semantic embedding models in the retrieval stage and several LLMs in the generation stage, in order to investigate what works and what doesn't in the context of Arabic. The work also touches upon the issue of variations between document dialect and query dialect in the retrieval stage. Results show that existing semantic embedding models and LLMs can be effectively employed to build Arabic RAG pipelines.
The FIGNEWS Shared Task on News Media Narratives
Jul 25, 2024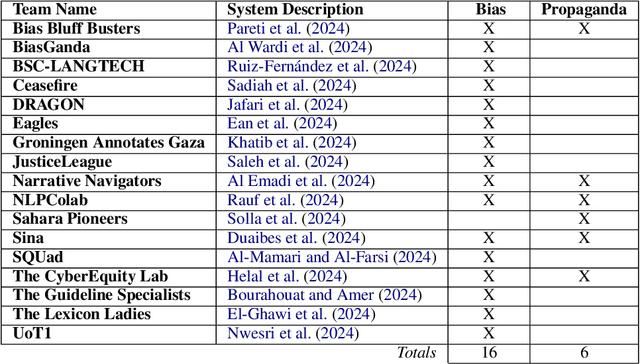
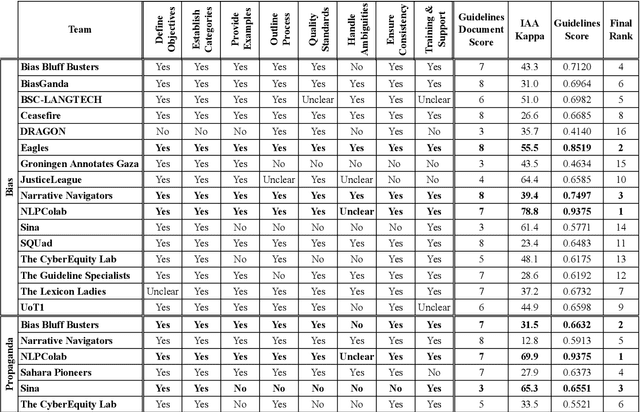
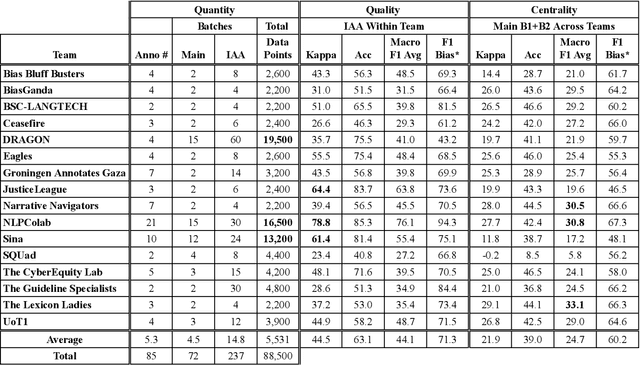
We present an overview of the FIGNEWS shared task, organized as part of the ArabicNLP 2024 conference co-located with ACL 2024. The shared task addresses bias and propaganda annotation in multilingual news posts. We focus on the early days of the Israel War on Gaza as a case study. The task aims to foster collaboration in developing annotation guidelines for subjective tasks by creating frameworks for analyzing diverse narratives highlighting potential bias and propaganda. In a spirit of fostering and encouraging diversity, we address the problem from a multilingual perspective, namely within five languages: English, French, Arabic, Hebrew, and Hindi. A total of 17 teams participated in two annotation subtasks: bias (16 teams) and propaganda (6 teams). The teams competed in four evaluation tracks: guidelines development, annotation quality, annotation quantity, and consistency. Collectively, the teams produced 129,800 data points. Key findings and implications for the field are discussed.
A Panoramic Survey of Natural Language Processing in the Arab World
Nov 26, 2020The term natural language refers to any system of symbolic communication (spoken, signed or written) without intentional human planning and design. This distinguishes natural languages such as Arabic and Japanese from artificially constructed languages such as Esperanto or Python. Natural language processing (NLP) is the sub-field of artificial intelligence (AI) focused on modeling natural languages to build applications such as speech recognition and synthesis, machine translation, optical character recognition (OCR), sentiment analysis (SA), question answering, dialogue systems, etc. NLP is a highly interdisciplinary field with connections to computer science, linguistics, cognitive science, psychology, mathematics and others. Some of the earliest AI applications were in NLP (e.g., machine translation); and the last decade (2010-2020) in particular has witnessed an incredible increase in quality, matched with a rise in public awareness, use, and expectations of what may have seemed like science fiction in the past. NLP researchers pride themselves on developing language independent models and tools that can be applied to all human languages, e.g. machine translation systems can be built for a variety of languages using the same basic mechanisms and models. However, the reality is that some languages do get more attention (e.g., English and Chinese) than others (e.g., Hindi and Swahili). Arabic, the primary language of the Arab world and the religious language of millions of non-Arab Muslims is somewhere in the middle of this continuum. Though Arabic NLP has many challenges, it has seen many successes and developments. Next we discuss Arabic's main challenges as a necessary background, and we present a brief history of Arabic NLP. We then survey a number of its research areas, and close with a critical discussion of the future of Arabic NLP.
A Simple and Effective Approach for Fine Tuning Pre-trained Word Embeddings for Improved Text Classification
Aug 07, 2019



This work presents a new and simple approach for fine-tuning pretrained word embeddings for text classification tasks. In this approach, the class in which a term appears, acts as an additional contextual variable during the fine tuning process, and contributes to the final word vector for that term. As a result, words that are used distinctively within a particular class, will bear vectors that are closer to each other in the embedding space and will be more discriminative towards that class. To validate this novel approach, it was applied to three Arabic and two English datasets that have been previously used for text classification tasks such as sentiment analysis and emotion detection. In the vast majority of cases, the results obtained using the proposed approach, improved considerably.
NileTMRG at SemEval-2017 Task 4: Arabic Sentiment Analysis
Oct 23, 2017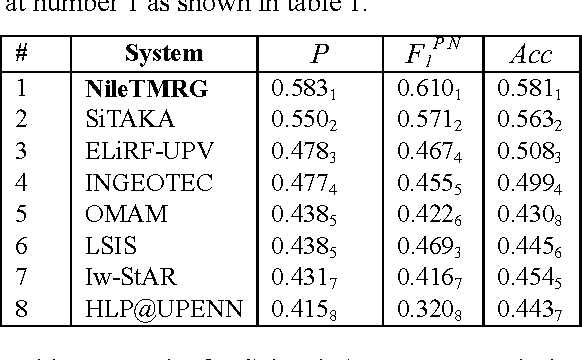
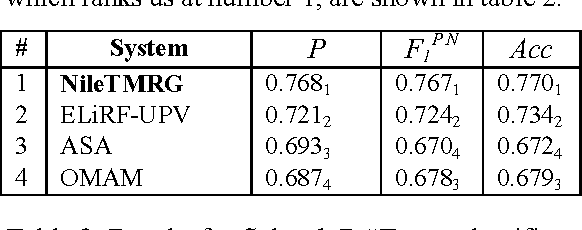

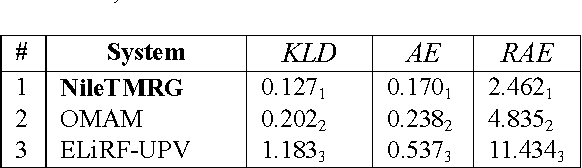
This paper describes two systems that were used by the authors for addressing Arabic Sentiment Analysis as part of SemEval-2017, task 4. The authors participated in three Arabic related subtasks which are: Subtask A (Message Polarity Classification), Sub-task B (Topic-Based Message Polarity classification) and Subtask D (Tweet quantification) using the team name of NileTMRG. For subtask A, we made use of our previously developed sentiment analyzer which we augmented with a scored lexicon. For subtasks B and D, we used an ensemble of three different classifiers. The first classifier was a convolutional neural network for which we trained (word2vec) word embeddings. The second classifier consisted of a MultiLayer Perceptron, while the third classifier was a Logistic regression model that takes the same input as the second classifier. Voting between the three classifiers was used to determine the final outcome. The output from task B, was quantified to produce the results for task D. In all three Arabic related tasks in which NileTMRG participated, the team ranked at number one.
Combining Lexical Features and a Supervised Learning Approach for Arabic Sentiment Analysis
Oct 23, 2017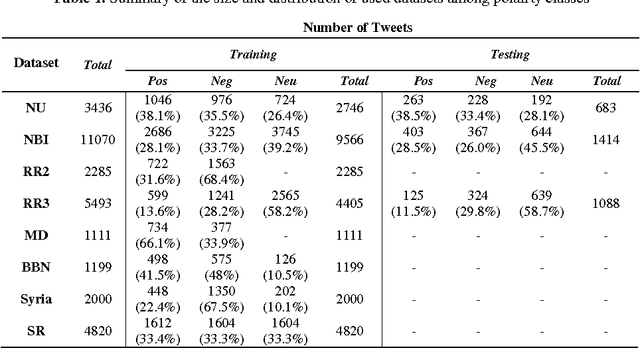
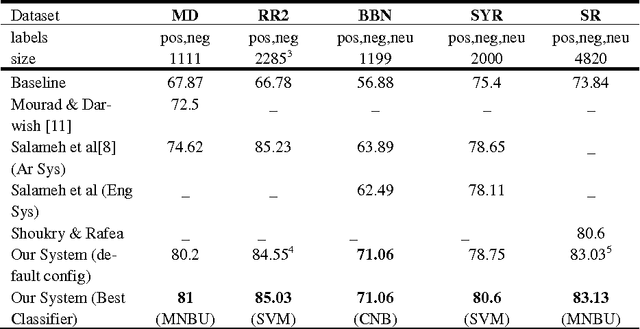
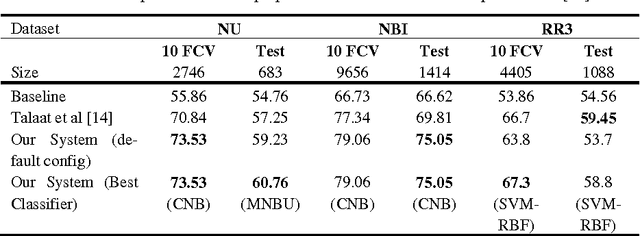
The importance of building sentiment analysis tools for Arabic social media has been recognized during the past couple of years, especially with the rapid increase in the number of Arabic social media users. One of the main difficulties in tackling this problem is that text within social media is mostly colloquial, with many dialects being used within social media platforms. In this paper, we present a set of features that were integrated with a machine learning based sentiment analysis model and applied on Egyptian, Saudi, Levantine, and MSA Arabic social media datasets. Many of the proposed features were derived through the use of an Arabic Sentiment Lexicon. The model also presents emoticon based features, as well as input text related features such as the number of segments within the text, the length of the text, whether the text ends with a question mark or not, etc. We show that the presented features have resulted in an increased accuracy across six of the seven datasets we've experimented with and which are all benchmarked. Since the developed model out-performs all existing Arabic sentiment analysis systems that have publicly available datasets, we can state that this model presents state-of-the-art in Arabic sentiment analysis.