 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Code-Centric to Concept-Centric: Teaching NLP with LLM-Assisted "Vibe Coding"
Feb 02, 2026The rapid advancement of Large Language Models (LLMs) presents both challenges and opportunities for Natural Language Processing (NLP) education. This paper introduces ``Vibe Coding,'' a pedagogical approach that leverages LLMs as coding assistants while maintaining focus on conceptual understanding and critical thinking. We describe the implementation of this approach in a senior-level undergraduate NLP course, where students completed seven labs using LLMs for code generation while being assessed primarily on conceptual understanding through critical reflection questions. Analysis of end-of-course feedback from 19 students reveals high satisfaction (mean scores 4.4-4.6/5.0) across engagement, conceptual learning, and assessment fairness. Students particularly valued the reduced cognitive load from debugging, enabling deeper focus on NLP concepts. However, challenges emerged around time constraints, LLM output verification, and the need for clearer task specifications. Our findings suggest that when properly structured with mandatory prompt logging and reflection-based assessment, LLM-assisted learning can shift focus from syntactic fluency to conceptual mastery, preparing students for an AI-augmented professional landscape.
CommonLID: Re-evaluating State-of-the-Art Language Identification Performance on Web Data
Jan 25, 2026Language identification (LID) is a fundamental step in curating multilingual corpora. However, LID models still perform poorly for many languages, especially on the noisy and heterogeneous web data often used to train multilingual language models. In this paper, we introduce CommonLID, a community-driven, human-annotated LID benchmark for the web domain, covering 109 languages. Many of the included languages have been previously under-served, making CommonLID a key resource for developing more representative high-quality text corpora. We show CommonLID's value by using it, alongside five other common evaluation sets, to test eight popular LID models. We analyse our results to situate our contribution and to provide an overview of the state of the art. In particular, we highlight that existing evaluations overestimate LID accuracy for many languages in the web domain. We make CommonLID and the code used to create it available under an open, permissive license.
The Prompting Brain: Neurocognitive Markers of Expertise in Guiding Large Language Models
Aug 20, 2025Prompt engineering has rapidly emerged as a critical skill for effective interaction with large language models (LLMs). However, the cognitive and neural underpinnings of this expertise remain largely unexplored. This paper presents findings from a cross-sectional pilot fMRI study investigating differences in brain functional connectivity and network activity between experts and intermediate prompt engineers. Our results reveal distinct neural signatures associated with higher prompt engineering literacy, including increased functional connectivity in brain regions such as the left middle temporal gyrus and the left frontal pole, as well as altered power-frequency dynamics in key cognitive networks. These findings offer initial insights into the neurobiological basis of prompt engineering proficiency. We discuss the implications of these neurocognitive markers in Natural Language Processing (NLP). Understanding the neural basis of human expertise in interacting with LLMs can inform the design of more intuitive human-AI interfaces, contribute to cognitive models of LLM interaction, and potentially guide the development of AI systems that better align with human cognitive workflows. This interdisciplinary approach aims to bridge the gap between human cognition and machine intelligence, fostering a deeper understanding of how humans learn and adapt to complex AI systems.
MultiProSE: A Multi-label Arabic Dataset for Propaganda, Sentiment, and Emotion Detection
Feb 12, 2025
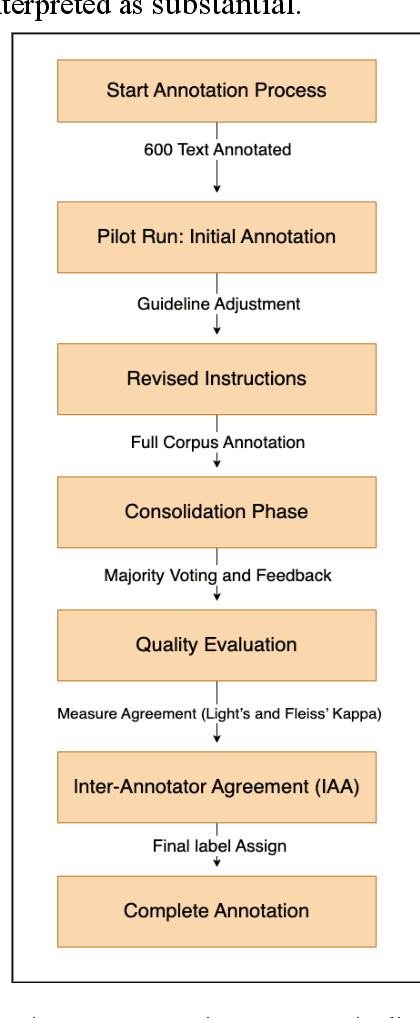
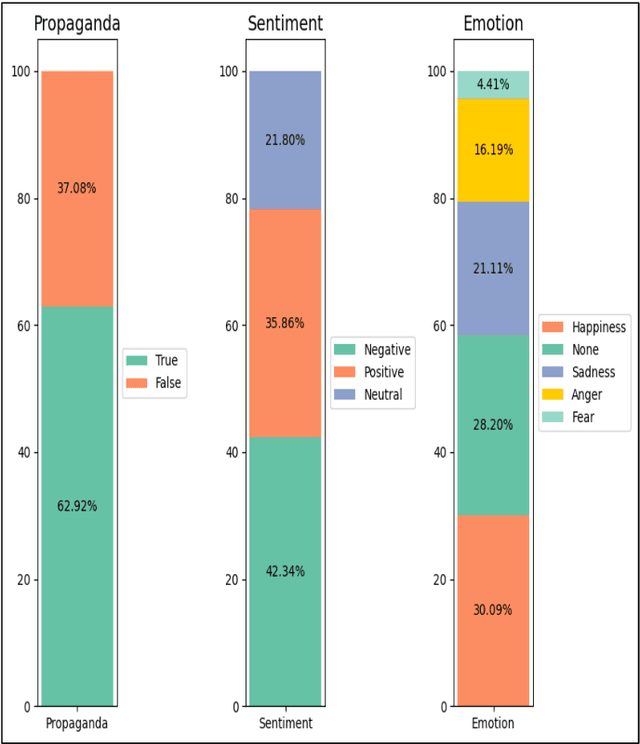
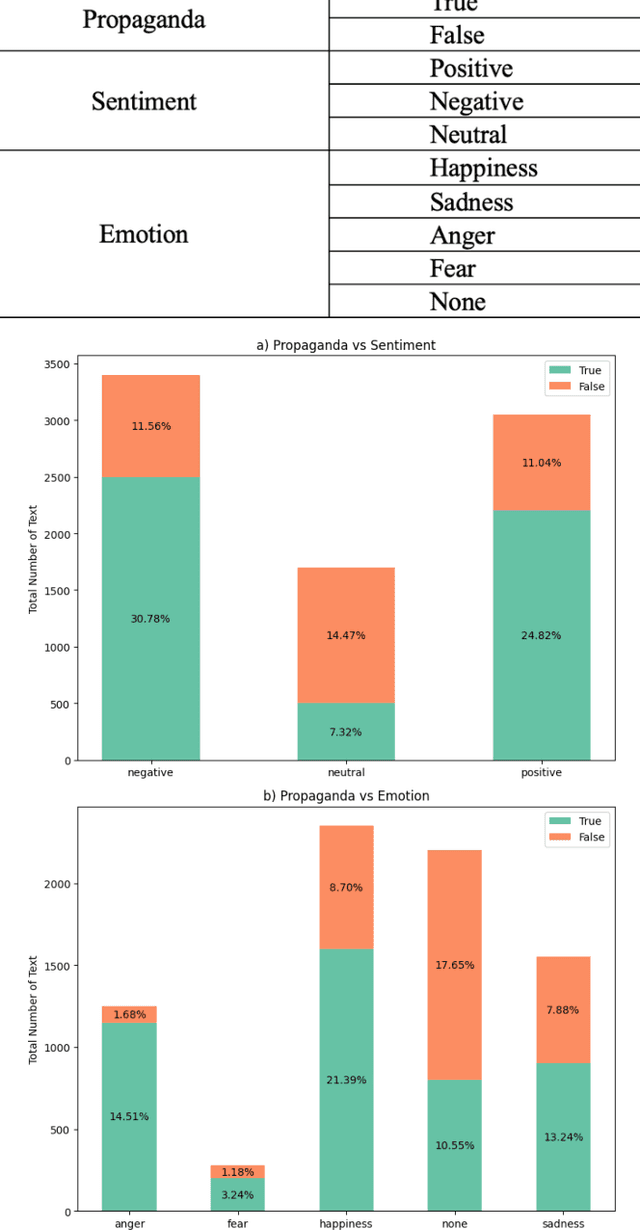
Propaganda is a form of persuasion that has been used throughout history with the intention goal of influencing people's opinions through rhetorical and psychological persuasion techniques for determined ends. Although Arabic ranked as the fourth most- used language on the internet, resources for propaganda detection in languages other than English, especially Arabic, remain extremely limited. To address this gap, the first Arabic dataset for Multi-label Propaganda, Sentiment, and Emotion (MultiProSE) has been introduced. MultiProSE is an open-source extension of the existing Arabic propaganda dataset, ArPro, with the addition of sentiment and emotion annotations for each text. This dataset comprises 8,000 annotated news articles, which is the largest propaganda dataset to date. For each task, several baselines have been developed using large language models (LLMs), such as GPT-4o-mini, and pre-trained language models (PLMs), including three BERT-based models. The dataset, annotation guidelines, and source code are all publicly released to facilitate future research and development in Arabic language models and contribute to a deeper understanding of how various opinion dimensions interact in news media1.
GLARE: Google Apps Arabic Reviews Dataset
Dec 16, 2024



This paper introduces GLARE an Arabic Apps Reviews dataset collected from Saudi Google PlayStore. It consists of 76M reviews, 69M of which are Arabic reviews of 9,980 Android Applications. We present the data collection methodology, along with a detailed Exploratory Data Analysis (EDA) and Feature Engineering on the gathered reviews. We also highlight possible use cases and benefits of the dataset.
A Survey of Large Language Models for Arabic Language and its Dialects
Oct 26, 2024


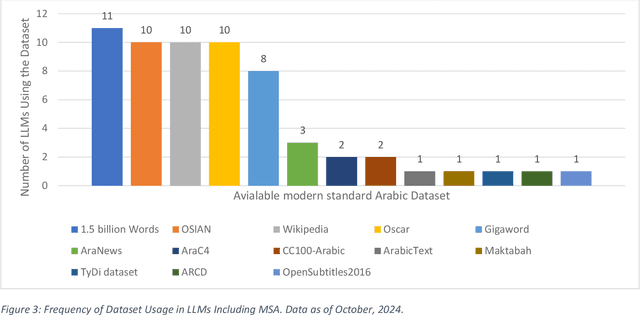
This survey offers a comprehensive overview of Large Language Models (LLMs) designed for Arabic language and its dialects. It covers key architectures, including encoder-only, decoder-only, and encoder-decoder models, along with the datasets used for pre-training, spanning Classical Arabic, Modern Standard Arabic, and Dialectal Arabic. The study also explores monolingual, bilingual, and multilingual LLMs, analyzing their architectures and performance across downstream tasks, such as sentiment analysis, named entity recognition, and question answering. Furthermore, it assesses the openness of Arabic LLMs based on factors, such as source code availability, training data, model weights, and documentation. The survey highlights the need for more diverse dialectal datasets and attributes the importance of openness for research reproducibility and transparency. It concludes by identifying key challenges and opportunities for future research and stressing the need for more inclusive and representative models.
CLEANANERCorp: Identifying and Correcting Incorrect Labels in the ANERcorp Dataset
Aug 22, 2024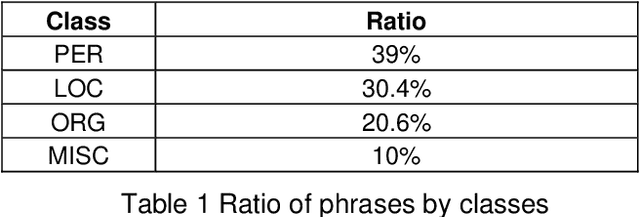
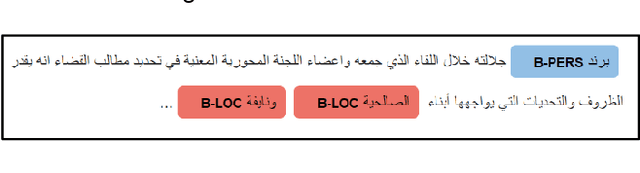
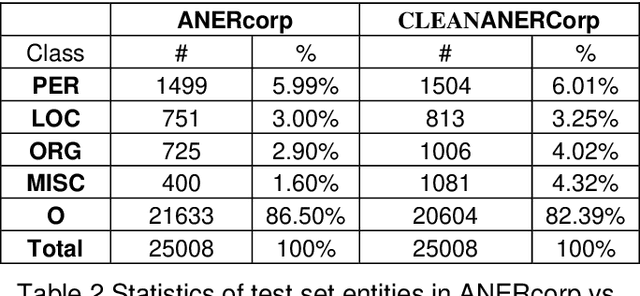
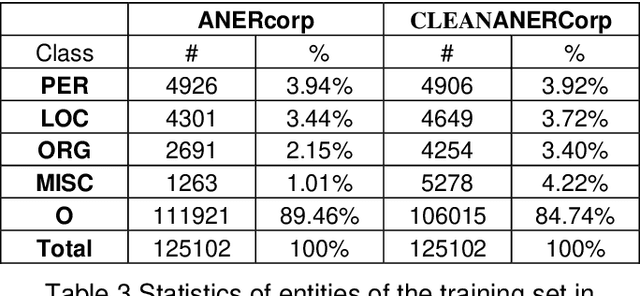
Label errors are a common issue in machine learning datasets, particularly for tasks such as Named Entity Recognition. Such label errors might hurt model training, affect evaluation results, and lead to an inaccurate assessment of model performance. In this study, we dived deep into one of the widely adopted Arabic NER benchmark datasets (ANERcorp) and found a significant number of annotation errors, missing labels, and inconsistencies. Therefore, in this study, we conducted empirical research to understand these errors, correct them and propose a cleaner version of the dataset named CLEANANERCorp. CLEANANERCorp will serve the research community as a more accurate and consistent benchmark.
* Proceedings of the 6th Workshop on Open-Source Arabic Corpora and Processing Tools (OSACT) with Shared Tasks on Arabic LLMs Hallucination and Dialect to MSA Machine Translation @ LREC-COLING 2024
The Qiyas Benchmark: Measuring ChatGPT Mathematical and Language Understanding in Arabic
Jun 28, 2024
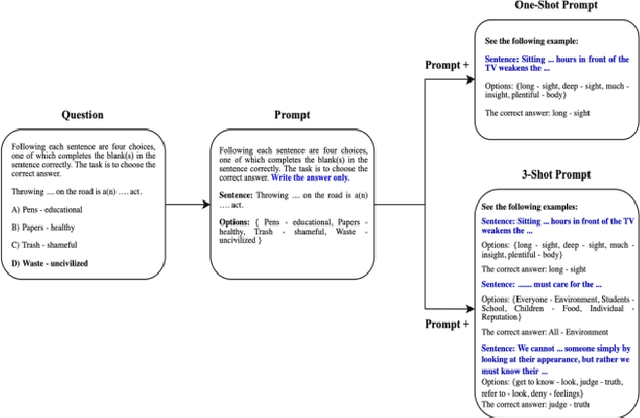
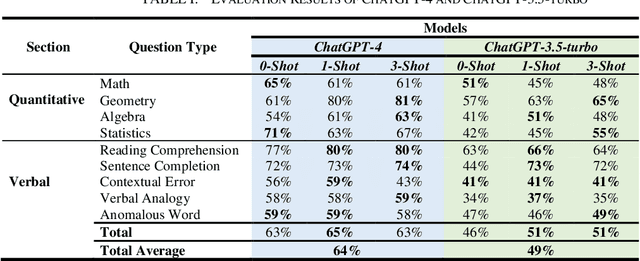

Despite the growing importance of Arabic as a global language, there is a notable lack of language models pre-trained exclusively on Arabic data. This shortage has led to limited benchmarks available for assessing language model performance in Arabic. To address this gap, we introduce two novel benchmarks designed to evaluate models' mathematical reasoning and language understanding abilities in Arabic. These benchmarks are derived from a General Aptitude Test (GAT) called Qiyas exam, a standardized test widely used for university admissions in Saudi Arabia. For validation purposes, we assess the performance of ChatGPT-3.5-trubo and ChatGPT-4 on our benchmarks. Our findings reveal that these benchmarks pose a significant challenge, with ChatGPT-4 achieving an overall average accuracy of 64%, while ChatGPT-3.5-trubo achieved an overall accuracy of 49% across the various question types in the Qiyas benchmark. We believe the release of these benchmarks will pave the way for enhancing the mathematical reasoning and language understanding capabilities of future models tailored for the low-resource Arabic language.
Towards Designing a ChatGPT Conversational Companion for Elderly People
Apr 18, 2023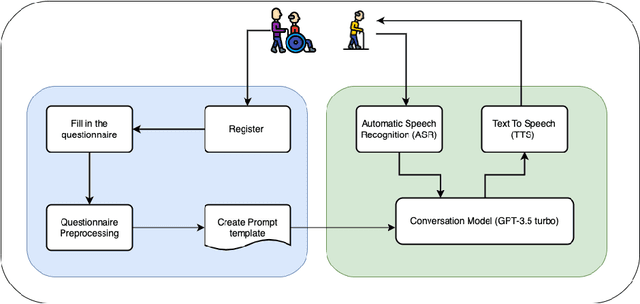



Loneliness and social isolation are serious and widespread problems among older people, affecting their physical and mental health, quality of life, and longevity. In this paper, we propose a ChatGPT-based conversational companion system for elderly people. The system is designed to provide companionship and help reduce feelings of loneliness and social isolation. The system was evaluated with a preliminary study. The results showed that the system was able to generate responses that were relevant to the created elderly personas. However, it is essential to acknowledge the limitations of ChatGPT, such as potential biases and misinformation, and to consider the ethical implications of using AI-based companionship for the elderly, including privacy concerns.
The Saudi Privacy Policy Dataset
Apr 05, 2023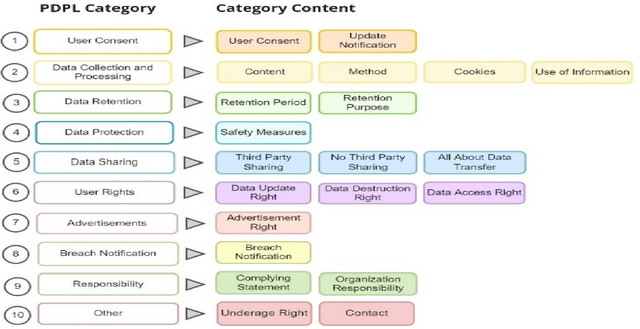

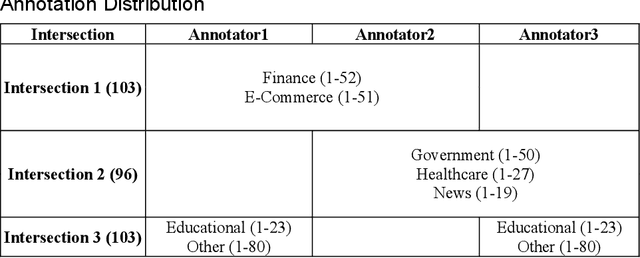

This paper introduces the Saudi Privacy Policy Dataset, a diverse compilation of Arabic privacy policies from various sectors in Saudi Arabia, annotated according to the 10 principles of the Personal Data Protection Law (PDPL); the PDPL was established to be compatible with General Data Protection Regulation (GDPR); one of the most comprehensive data regulations worldwide. Data were collected from multiple sources, including the Saudi Central Bank, the Saudi Arabia National United Platform, the Council of Health Insurance, and general websites using Google and Wikipedia. The final dataset includes 1,000 websites belonging to 7 sectors, 4,638 lines of text, 775,370 tokens, and a corpus size of 8,353 KB. The annotated dataset offers significant reuse potential for assessing privacy policy compliance, benchmarking privacy practices across industries, and developing automated tools for monitoring adherence to data protection regulations. By providing a comprehensive and annotated dataset of privacy policies, this paper aims to facilitate further research and development in the areas of privacy policy analysis, natural language processing, and machine learning applications related to privacy and data protection, while also serving as an essential resource for researchers, policymakers, and industry professionals interested in understanding and promoting compliance with privacy regulations in Saudi Arabia.