Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLEANANERCorp: Identifying and Correcting Incorrect Labels in the ANERcorp Dataset
Paper and Code
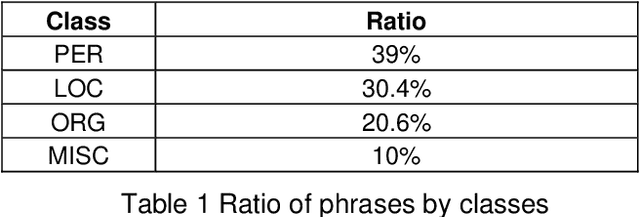
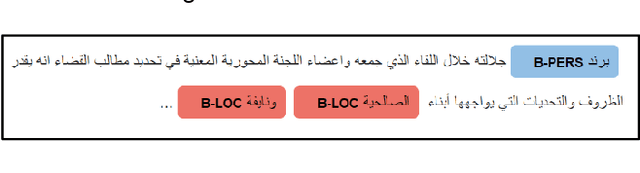
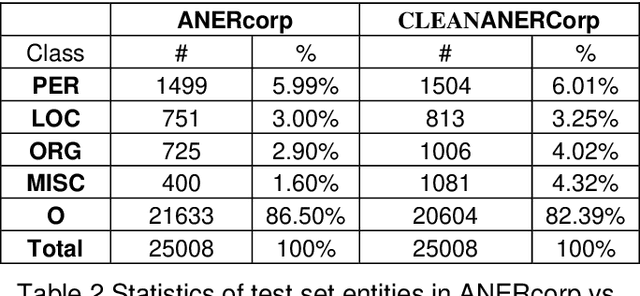
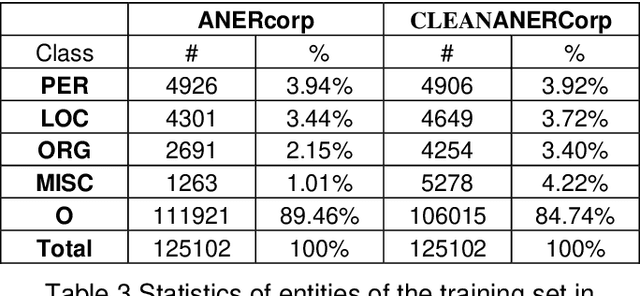
Label errors are a common issue in machine learning datasets, particularly for tasks such as Named Entity Recognition. Such label errors might hurt model training, affect evaluation results, and lead to an inaccurate assessment of model performance. In this study, we dived deep into one of the widely adopted Arabic NER benchmark datasets (ANERcorp) and found a significant number of annotation errors, missing labels, and inconsistencies. Therefore, in this study, we conducted empirical research to understand these errors, correct them and propose a cleaner version of the dataset named CLEANANERCorp. CLEANANERCorp will serve the research community as a more accurate and consistent benchmark.
* ELRA and ICCL 2024 * Proceedings of the 6th Workshop on Open-Source Arabic Corpora and
Processing Tools (OSACT) with Shared Tasks on Arabic LLMs Hallucination and
Dialect to MSA Machine Translation @ LREC-COLING 2024
View paper on