 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Saudi Privacy Policy Dataset
Apr 05, 2023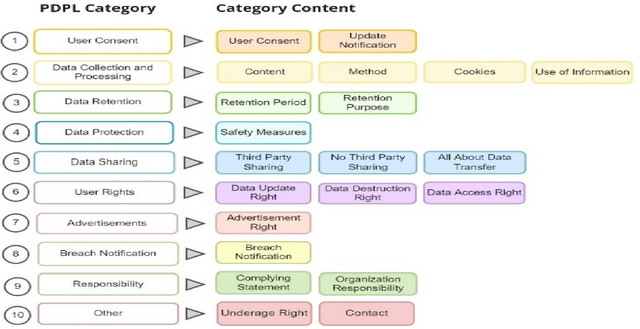

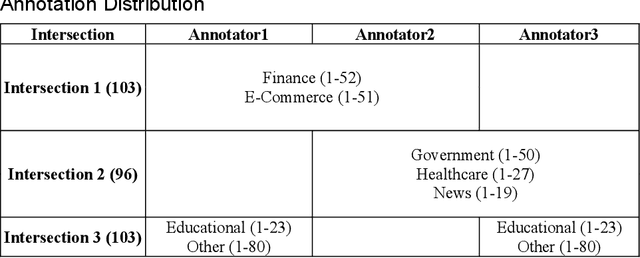

This paper introduces the Saudi Privacy Policy Dataset, a diverse compilation of Arabic privacy policies from various sectors in Saudi Arabia, annotated according to the 10 principles of the Personal Data Protection Law (PDPL); the PDPL was established to be compatible with General Data Protection Regulation (GDPR); one of the most comprehensive data regulations worldwide. Data were collected from multiple sources, including the Saudi Central Bank, the Saudi Arabia National United Platform, the Council of Health Insurance, and general websites using Google and Wikipedia. The final dataset includes 1,000 websites belonging to 7 sectors, 4,638 lines of text, 775,370 tokens, and a corpus size of 8,353 KB. The annotated dataset offers significant reuse potential for assessing privacy policy compliance, benchmarking privacy practices across industries, and developing automated tools for monitoring adherence to data protection regulations. By providing a comprehensive and annotated dataset of privacy policies, this paper aims to facilitate further research and development in the areas of privacy policy analysis, natural language processing, and machine learning applications related to privacy and data protection, while also serving as an essential resource for researchers, policymakers, and industry professionals interested in understanding and promoting compliance with privacy regulations in Saudi Arabia.
Natural Language Processing in Customer Service: A Systematic Review
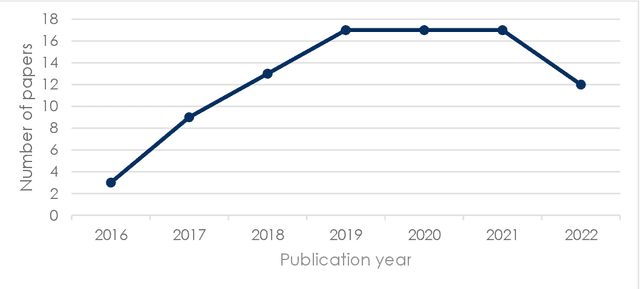
Dec 16, 2022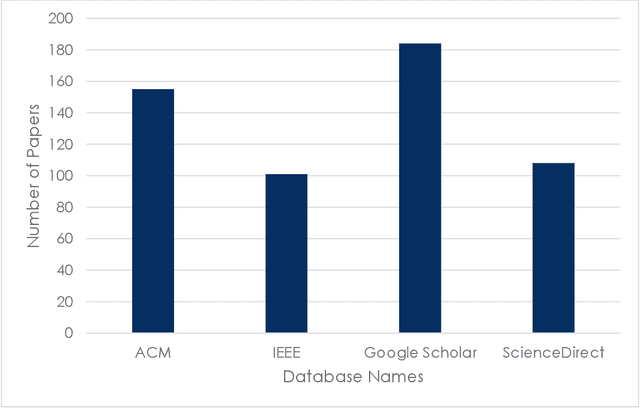
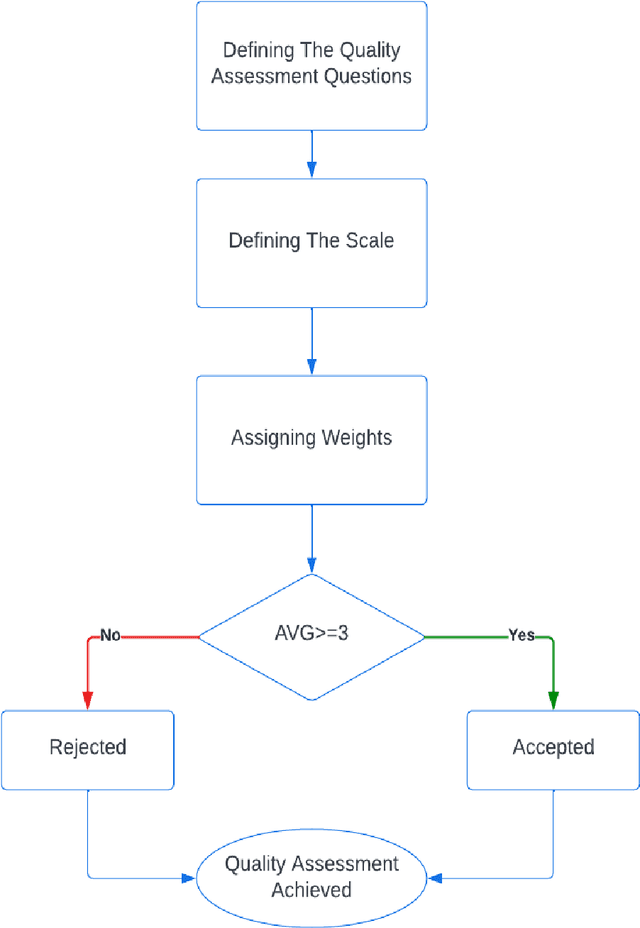
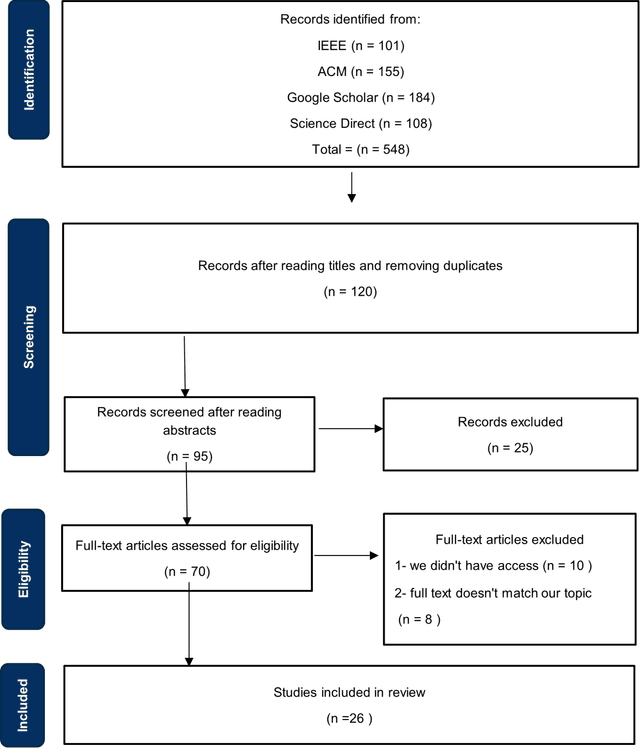
Artificial intelligence and natural language processing (NLP) are increasingly being used in customer service to interact with users and answer their questions. The goal of this systematic review is to examine existing research on the use of NLP technology in customer service, including the research domain, applications, datasets used, and evaluation methods. The review also looks at the future direction of the field and any significant limitations. The review covers the time period from 2015 to 2022 and includes papers from five major scientific databases. Chatbots and question-answering systems were found to be used in 10 main fields, with the most common use in general, social networking, and e-commerce areas. Twitter was the second most commonly used dataset, with most research also using their own original datasets. Accuracy, precision, recall, and F1 were the most common evaluation methods. Future work aims to improve the performance and understanding of user behavior and emotions, and address limitations such as the volume, diversity, and quality of datasets. This review includes research on different spoken languages and models and techniques.