 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArabDiscrim: A Decade-Long Arabic Facebook Corpus on Racism and Discrimination
May 21, 2026We present ArabDiscrim, a decade-long lexical resource and corpus of 293K public Arabic Facebook posts (2014--2024) discussing racism and discrimination. Unlike existing Twitter-centric datasets, ArabDiscrim integrates platform-native engagement signals, including reactions, shares, comments, and page metadata, enabling joint analysis of language and audience response. The resource includes 200 curated terms (100 racism-related and 100 discrimination-related) with morphological regex families (13+ inflections per lemma), and 20 discrimination axes capturing identity-based grounds for unequal treatment. It also provides explicit attribution patterns. Released under a restricted research-use license for ethical compliance with platform terms, ArabDiscrim supports weak supervision, axis-aware sampling, and platform ecology research. By bridging lexical depth and ecological validity, it establishes a foundation for fairness-oriented, platform-aware Arabic NLP.
JobArabi: An Arabic Corpus and Analysis of Job Announcements from Social Media
May 20, 2026This paper introduces JobArabi, a large-scale corpus of Arabic job announcements collected from social media between January 2024 and October 2025. The dataset contains 20,528 public posts from X and captures more than two years of employment-related discourse across Arabic-speaking online communities. The corpus was compiled using a linguistically informed query framework covering 21 Arabic keyword families that reflect gendered, plural, formal, and dialectal expressions of recruitment language. The resulting dataset includes posts from institutional, commercial, and individual accounts and provides metadata such as timestamps, engagement indicators, and geolocation when available, enabling temporal and regional analysis of employment discourse. Quantitative analysis reveals several sociolinguistic patterns in online recruitment, including the persistence of gendered hiring language, regional variation in occupational demand, and the emotional framing of recruitment messages. These findings highlight the potential of Arabic social media as a resource for studying labor market communication and linguistic change. The JobArabi corpus, together with documentation and collection scripts, will be released to support research in Arabic NLP, computational social science, and digital labor studies.
LAILA: A Large Trait-Based Dataset for Arabic Automated Essay Scoring
Dec 30, 2025Automated Essay Scoring (AES) has gained increasing attention in recent years, yet research on Arabic AES remains limited due to the lack of publicly available datasets. To address this, we introduce LAILA, the largest publicly available Arabic AES dataset to date, comprising 7,859 essays annotated with holistic and trait-specific scores on seven dimensions: relevance, organization, vocabulary, style, development, mechanics, and grammar. We detail the dataset design, collection, and annotations, and provide benchmark results using state-of-the-art Arabic and English models in prompt-specific and cross-prompt settings. LAILA fills a critical need in Arabic AES research, supporting the development of robust scoring systems.
Towards Global AI Inclusivity: A Large-Scale Multilingual Terminology Dataset
Dec 24, 2024The field of machine translation has achieved significant advancements, yet domain-specific terminology translation, particularly in AI, remains challenging. We introduced GIST, a large-scale multilingual AI terminology dataset containing 5K terms extracted from top AI conference papers spanning 2000 to 2023. The terms were translated into Arabic, Chinese, French, Japanese, and Russian using a hybrid framework that combines LLMs for extraction with human expertise for translation. The dataset's quality was benchmarked against existing resources, demonstrating superior translation accuracy through crowdsourced evaluation. GIST was integrated into translation workflows using post-translation refinement methods that required no retraining, where LLM prompting consistently improved BLEU and COMET scores. A web demonstration on the ACL Anthology platform highlights its practical application, showcasing improved accessibility for non-English speakers. This work aims to address critical gaps in AI terminology resources and fosters global inclusivity and collaboration in AI research.
The FIGNEWS Shared Task on News Media Narratives
Jul 25, 2024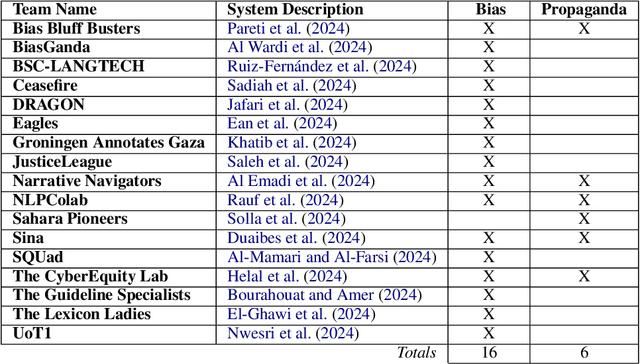
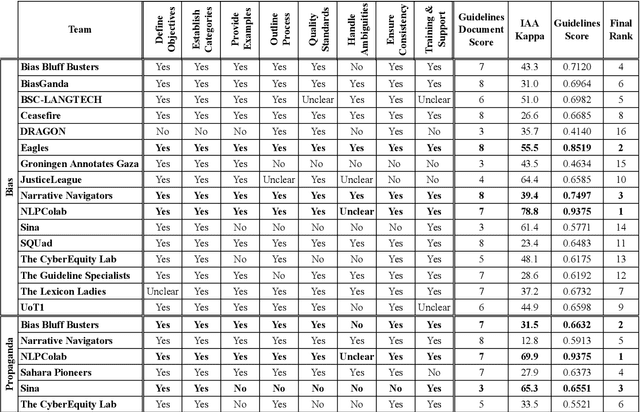
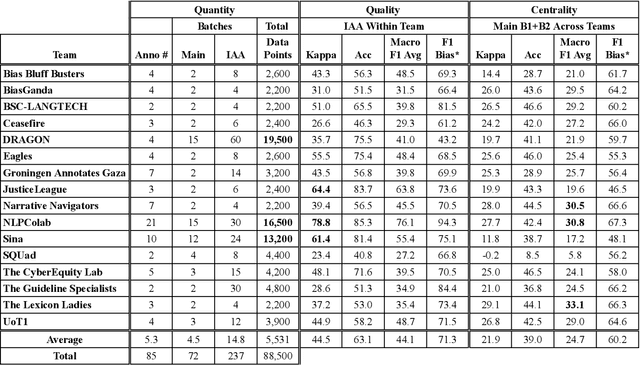
We present an overview of the FIGNEWS shared task, organized as part of the ArabicNLP 2024 conference co-located with ACL 2024. The shared task addresses bias and propaganda annotation in multilingual news posts. We focus on the early days of the Israel War on Gaza as a case study. The task aims to foster collaboration in developing annotation guidelines for subjective tasks by creating frameworks for analyzing diverse narratives highlighting potential bias and propaganda. In a spirit of fostering and encouraging diversity, we address the problem from a multilingual perspective, namely within five languages: English, French, Arabic, Hebrew, and Hindi. A total of 17 teams participated in two annotation subtasks: bias (16 teams) and propaganda (6 teams). The teams competed in four evaluation tracks: guidelines development, annotation quality, annotation quantity, and consistency. Collectively, the teams produced 129,800 data points. Key findings and implications for the field are discussed.
AraFinNLP 2024: The First Arabic Financial NLP Shared Task
Jul 13, 2024



The expanding financial markets of the Arab world require sophisticated Arabic NLP tools. To address this need within the banking domain, the Arabic Financial NLP (AraFinNLP) shared task proposes two subtasks: (i) Multi-dialect Intent Detection and (ii) Cross-dialect Translation and Intent Preservation. This shared task uses the updated ArBanking77 dataset, which includes about 39k parallel queries in MSA and four dialects. Each query is labeled with one or more of a common 77 intents in the banking domain. These resources aim to foster the development of robust financial Arabic NLP, particularly in the areas of machine translation and banking chat-bots. A total of 45 unique teams registered for this shared task, with 11 of them actively participated in the test phase. Specifically, 11 teams participated in Subtask 1, while only 1 team participated in Subtask 2. The winning team of Subtask 1 achieved F1 score of 0.8773, and the only team submitted in Subtask 2 achieved a 1.667 BLEU score.
NADI 2024: The Fifth Nuanced Arabic Dialect Identification Shared Task
Jul 06, 2024We describe the findings of the fifth Nuanced Arabic Dialect Identification Shared Task (NADI 2024). NADI's objective is to help advance SoTA Arabic NLP by providing guidance, datasets, modeling opportunities, and standardized evaluation conditions that allow researchers to collaboratively compete on pre-specified tasks. NADI 2024 targeted both dialect identification cast as a multi-label task (Subtask~1), identification of the Arabic level of dialectness (Subtask~2), and dialect-to-MSA machine translation (Subtask~3). A total of 51 unique teams registered for the shared task, of whom 12 teams have participated (with 76 valid submissions during the test phase). Among these, three teams participated in Subtask~1, three in Subtask~2, and eight in Subtask~3. The winning teams achieved 50.57 F\textsubscript{1} on Subtask~1, 0.1403 RMSE for Subtask~2, and 20.44 BLEU in Subtask~3, respectively. Results show that Arabic dialect processing tasks such as dialect identification and machine translation remain challenging. We describe the methods employed by the participating teams and briefly offer an outlook for NADI.
Exploiting Dialect Identification in Automatic Dialectal Text Normalization
Jul 03, 2024



Dialectal Arabic is the primary spoken language used by native Arabic speakers in daily communication. The rise of social media platforms has notably expanded its use as a written language. However, Arabic dialects do not have standard orthographies. This, combined with the inherent noise in user-generated content on social media, presents a major challenge to NLP applications dealing with Dialectal Arabic. In this paper, we explore and report on the task of CODAfication, which aims to normalize Dialectal Arabic into the Conventional Orthography for Dialectal Arabic (CODA). We work with a unique parallel corpus of multiple Arabic dialects focusing on five major city dialects. We benchmark newly developed pretrained sequence-to-sequence models on the task of CODAfication. We further show that using dialect identification information improves the performance across all dialects. We make our code, data, and pretrained models publicly available.
Chinese Offensive Language Detection:Current Status and Future Directions
Mar 29, 2024


Despite the considerable efforts being made to monitor and regulate user-generated content on social media platforms, the pervasiveness of offensive language, such as hate speech or cyberbullying, in the digital space remains a significant challenge. Given the importance of maintaining a civilized and respectful online environment, there is an urgent and growing need for automatic systems capable of detecting offensive speech in real time. However, developing effective systems for processing languages such as Chinese presents a significant challenge, owing to the language's complex and nuanced nature, which makes it difficult to process automatically. This paper provides a comprehensive overview of offensive language detection in Chinese, examining current benchmarks and approaches and highlighting specific models and tools for addressing the unique challenges of detecting offensive language in this complex language. The primary objective of this survey is to explore the existing techniques and identify potential avenues for further research that can address the cultural and linguistic complexities of Chinese.
Cross-Lingual Transfer from Related Languages: Treating Low-Resource Maltese as Multilingual Code-Switching
Feb 03, 2024Although multilingual language models exhibit impressive cross-lingual transfer capabilities on unseen languages, the performance on downstream tasks is impacted when there is a script disparity with the languages used in the multilingual model's pre-training data. Using transliteration offers a straightforward yet effective means to align the script of a resource-rich language with a target language, thereby enhancing cross-lingual transfer capabilities. However, for mixed languages, this approach is suboptimal, since only a subset of the language benefits from the cross-lingual transfer while the remainder is impeded. In this work, we focus on Maltese, a Semitic language, with substantial influences from Arabic, Italian, and English, and notably written in Latin script. We present a novel dataset annotated with word-level etymology. We use this dataset to train a classifier that enables us to make informed decisions regarding the appropriate processing of each token in the Maltese language. We contrast indiscriminate transliteration or translation to mixing processing pipelines that only transliterate words of Arabic origin, thereby resulting in text with a mixture of scripts. We fine-tune the processed data on four downstream tasks and show that conditional transliteration based on word etymology yields the best results, surpassing fine-tuning with raw Maltese or Maltese processed with non-selective pipelines.