 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAfroScope: A Framework for Studying the Linguistic Landscape of Africa
Jan 19, 2026Language Identification (LID) is the task of determining the language of a given text and is a fundamental preprocessing step that affects the reliability of downstream NLP applications. While recent work has expanded LID coverage for African languages, existing approaches remain limited in (i) the number of supported languages and (ii) their ability to make fine-grained distinctions among closely related varieties. We introduce AfroScope, a unified framework for African LID that includes AfroScope-Data, a dataset covering 713 African languages, and AfroScope-Models, a suite of strong LID models with broad language coverage. To better distinguish highly confusable languages, we propose a hierarchical classification approach that leverages Mirror-Serengeti, a specialized embedding model targeting 29 closely related or geographically proximate languages. This approach improves macro F1 by 4.55 on this confusable subset compared to our best base model. Finally, we analyze cross linguistic transfer and domain effects, offering guidance for building robust African LID systems. We position African LID as an enabling technology for large scale measurement of Africas linguistic landscape in digital text and release AfroScope-Data and AfroScope-Models publicly.
Arab Voices: Mapping Standard and Dialectal Arabic Speech Technology
Jan 19, 2026Dialectal Arabic (DA) speech data vary widely in domain coverage, dialect labeling practices, and recording conditions, complicating cross-dataset comparison and model evaluation. To characterize this landscape, we conduct a computational analysis of linguistic ``dialectness'' alongside objective proxies of audio quality on the training splits of widely used DA corpora. We find substantial heterogeneity both in acoustic conditions and in the strength and consistency of dialectal signals across datasets, underscoring the need for standardized characterization beyond coarse labels. To reduce fragmentation and support reproducible evaluation, we introduce Arab Voices, a standardized framework for DA ASR. Arab Voices provides unified access to 31 datasets spanning 14 dialects, with harmonized metadata and evaluation utilities. We further benchmark a range of recent ASR systems, establishing strong baselines for modern DA ASR.
Voice of a Continent: Mapping Africa's Speech Technology Frontier
May 24, 2025Africa's rich linguistic diversity remains significantly underrepresented in speech technologies, creating barriers to digital inclusion. To alleviate this challenge, we systematically map the continent's speech space of datasets and technologies, leading to a new comprehensive benchmark SimbaBench for downstream African speech tasks. Using SimbaBench, we introduce the Simba family of models, achieving state-of-the-art performance across multiple African languages and speech tasks. Our benchmark analysis reveals critical patterns in resource availability, while our model evaluation demonstrates how dataset quality, domain diversity, and language family relationships influence performance across languages. Our work highlights the need for expanded speech technology resources that better reflect Africa's linguistic diversity and provides a solid foundation for future research and development efforts toward more inclusive speech technologies.
Where Are We? Evaluating LLM Performance on African Languages
Feb 26, 2025Africa's rich linguistic heritage remains underrepresented in NLP, largely due to historical policies that favor foreign languages and create significant data inequities. In this paper, we integrate theoretical insights on Africa's language landscape with an empirical evaluation using Sahara - a comprehensive benchmark curated from large-scale, publicly accessible datasets capturing the continent's linguistic diversity. By systematically assessing the performance of leading large language models (LLMs) on Sahara, we demonstrate how policy-induced data variations directly impact model effectiveness across African languages. Our findings reveal that while a few languages perform reasonably well, many Indigenous languages remain marginalized due to sparse data. Leveraging these insights, we offer actionable recommendations for policy reforms and inclusive data practices. Overall, our work underscores the urgent need for a dual approach - combining theoretical understanding with empirical evaluation - to foster linguistic diversity in AI for African communities.
WojoodNER 2024: The Second Arabic Named Entity Recognition Shared Task
Jul 13, 2024We present WojoodNER-2024, the second Arabic Named Entity Recognition (NER) Shared Task. In WojoodNER-2024, we focus on fine-grained Arabic NER. We provided participants with a new Arabic fine-grained NER dataset called wojoodfine, annotated with subtypes of entities. WojoodNER-2024 encompassed three subtasks: (i) Closed-Track Flat Fine-Grained NER, (ii) Closed-Track Nested Fine-Grained NER, and (iii) an Open-Track NER for the Israeli War on Gaza. A total of 43 unique teams registered for this shared task. Five teams participated in the Flat Fine-Grained Subtask, among which two teams tackled the Nested Fine-Grained Subtask and one team participated in the Open-Track NER Subtask. The winning teams achieved F-1 scores of 91% and 92% in the Flat Fine-Grained and Nested Fine-Grained Subtasks, respectively. The sole team in the Open-Track Subtask achieved an F-1 score of 73.7%.
NADI 2024: The Fifth Nuanced Arabic Dialect Identification Shared Task
Jul 06, 2024We describe the findings of the fifth Nuanced Arabic Dialect Identification Shared Task (NADI 2024). NADI's objective is to help advance SoTA Arabic NLP by providing guidance, datasets, modeling opportunities, and standardized evaluation conditions that allow researchers to collaboratively compete on pre-specified tasks. NADI 2024 targeted both dialect identification cast as a multi-label task (Subtask~1), identification of the Arabic level of dialectness (Subtask~2), and dialect-to-MSA machine translation (Subtask~3). A total of 51 unique teams registered for the shared task, of whom 12 teams have participated (with 76 valid submissions during the test phase). Among these, three teams participated in Subtask~1, three in Subtask~2, and eight in Subtask~3. The winning teams achieved 50.57 F\textsubscript{1} on Subtask~1, 0.1403 RMSE for Subtask~2, and 20.44 BLEU in Subtask~3, respectively. Results show that Arabic dialect processing tasks such as dialect identification and machine translation remain challenging. We describe the methods employed by the participating teams and briefly offer an outlook for NADI.
Toucan: Many-to-Many Translation for 150 African Language Pairs
Jul 05, 2024We address a notable gap in Natural Language Processing (NLP) by introducing a collection of resources designed to improve Machine Translation (MT) for low-resource languages, with a specific focus on African languages. First, We introduce two language models (LMs), Cheetah-1.2B and Cheetah-3.7B, with 1.2 billion and 3.7 billion parameters respectively. Next, we finetune the aforementioned models to create toucan, an Afrocentric machine translation model designed to support 156 African language pairs. To evaluate Toucan, we carefully develop an extensive machine translation benchmark, dubbed AfroLingu-MT, tailored for evaluating machine translation. Toucan significantly outperforms other models, showcasing its remarkable performance on MT for African languages. Finally, we train a new model, spBLEU-1K, to enhance translation evaluation metrics, covering 1K languages, including 614 African languages. This work aims to advance the field of NLP, fostering cross-cultural understanding and knowledge exchange, particularly in regions with limited language resources such as Africa. The GitHub repository for the Toucan project is available at https://github.com/UBC-NLP/Toucan.
Cheetah: Natural Language Generation for 517 African Languages
Jan 10, 2024Low-resource African languages pose unique challenges for natural language processing (NLP) tasks, including natural language generation (NLG). In this paper, we develop Cheetah, a massively multilingual NLG language model for African languages. Cheetah supports 517 African languages and language varieties, allowing us to address the scarcity of NLG resources and provide a solution to foster linguistic diversity. We demonstrate the effectiveness of Cheetah through comprehensive evaluations across six generation downstream tasks. In five of the six tasks, Cheetah significantly outperforms other models, showcasing its remarkable performance for generating coherent and contextually appropriate text in a wide range of African languages. We additionally conduct a detailed human evaluation to delve deeper into the linguistic capabilities of Cheetah. The introduction of Cheetah has far-reaching benefits for linguistic diversity. By leveraging pretrained models and adapting them to specific languages, our approach facilitates the development of practical NLG applications for African communities. The findings of this study contribute to advancing NLP research in low-resource settings, enabling greater accessibility and inclusion for African languages in a rapidly expanding digital landscape. We publicly release our models for research.
VoxArabica: A Robust Dialect-Aware Arabic Speech Recognition System
Oct 27, 2023



Arabic is a complex language with many varieties and dialects spoken by over 450 millions all around the world. Due to the linguistic diversity and variations, it is challenging to build a robust and generalized ASR system for Arabic. In this work, we address this gap by developing and demoing a system, dubbed VoxArabica, for dialect identification (DID) as well as automatic speech recognition (ASR) of Arabic. We train a wide range of models such as HuBERT (DID), Whisper, and XLS-R (ASR) in a supervised setting for Arabic DID and ASR tasks. Our DID models are trained to identify 17 different dialects in addition to MSA. We finetune our ASR models on MSA, Egyptian, Moroccan, and mixed data. Additionally, for the remaining dialects in ASR, we provide the option to choose various models such as Whisper and MMS in a zero-shot setting. We integrate these models into a single web interface with diverse features such as audio recording, file upload, model selection, and the option to raise flags for incorrect outputs. Overall, we believe VoxArabica will be useful for a wide range of audiences concerned with Arabic research. Our system is currently running at https://cdce-206-12-100-168.ngrok.io/.
NADI 2023: The Fourth Nuanced Arabic Dialect Identification Shared Task
Oct 24, 2023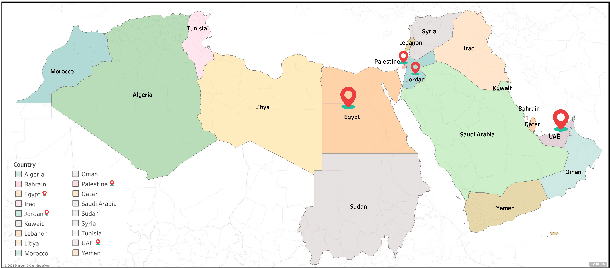
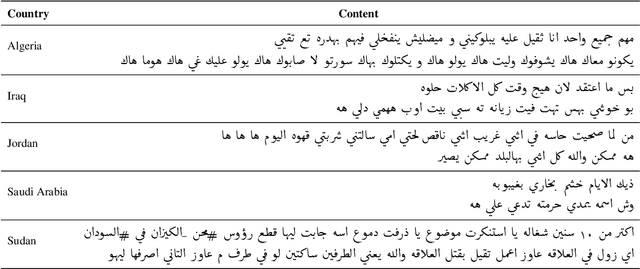

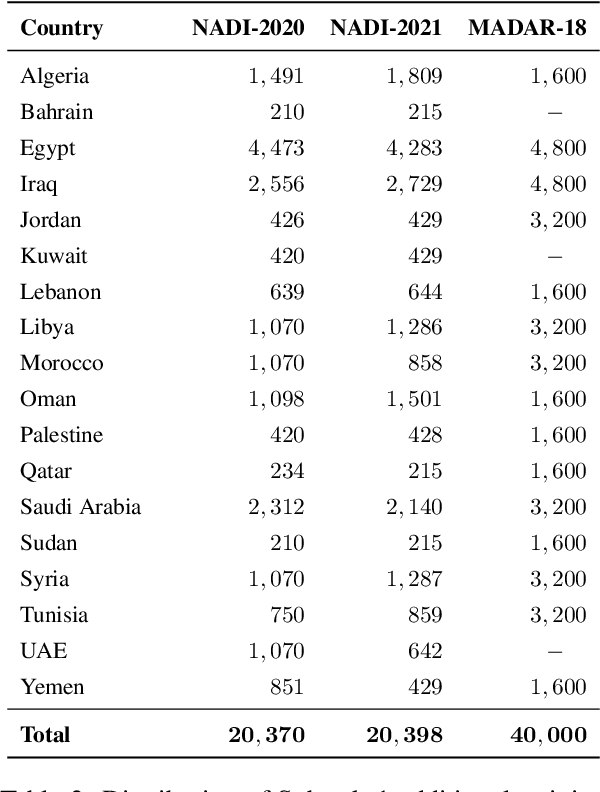
We describe the findings of the fourth Nuanced Arabic Dialect Identification Shared Task (NADI 2023). The objective of NADI is to help advance state-of-the-art Arabic NLP by creating opportunities for teams of researchers to collaboratively compete under standardized conditions. It does so with a focus on Arabic dialects, offering novel datasets and defining subtasks that allow for meaningful comparisons between different approaches. NADI 2023 targeted both dialect identification (Subtask 1) and dialect-to-MSA machine translation (Subtask 2 and Subtask 3). A total of 58 unique teams registered for the shared task, of whom 18 teams have participated (with 76 valid submissions during test phase). Among these, 16 teams participated in Subtask 1, 5 participated in Subtask 2, and 3 participated in Subtask 3. The winning teams achieved 87.27 F1 on Subtask 1, 14.76 Bleu in Subtask 2, and 21.10 Bleu in Subtask 3, respectively. Results show that all three subtasks remain challenging, thereby motivating future work in this area. We describe the methods employed by the participating teams and briefly offer an outlook for NADI.