 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKonooz: Multi-domain Multi-dialect Corpus for Named Entity Recognition
Jun 14, 2025We introduce Konooz, a novel multi-dimensional corpus covering 16 Arabic dialects across 10 domains, resulting in 160 distinct corpora. The corpus comprises about 777k tokens, carefully collected and manually annotated with 21 entity types using both nested and flat annotation schemes - using the Wojood guidelines. While Konooz is useful for various NLP tasks like domain adaptation and transfer learning, this paper primarily focuses on benchmarking existing Arabic Named Entity Recognition (NER) models, especially cross-domain and cross-dialect model performance. Our benchmarking of four Arabic NER models using Konooz reveals a significant drop in performance of up to 38% when compared to the in-distribution data. Furthermore, we present an in-depth analysis of domain and dialect divergence and the impact of resource scarcity. We also measured the overlap between domains and dialects using the Maximum Mean Discrepancy (MMD) metric, and illustrated why certain NER models perform better on specific dialects and domains. Konooz is open-source and publicly available at https://sina.birzeit.edu/wojood/#download
WojoodNER 2024: The Second Arabic Named Entity Recognition Shared Task
Jul 13, 2024We present WojoodNER-2024, the second Arabic Named Entity Recognition (NER) Shared Task. In WojoodNER-2024, we focus on fine-grained Arabic NER. We provided participants with a new Arabic fine-grained NER dataset called wojoodfine, annotated with subtypes of entities. WojoodNER-2024 encompassed three subtasks: (i) Closed-Track Flat Fine-Grained NER, (ii) Closed-Track Nested Fine-Grained NER, and (iii) an Open-Track NER for the Israeli War on Gaza. A total of 43 unique teams registered for this shared task. Five teams participated in the Flat Fine-Grained Subtask, among which two teams tackled the Nested Fine-Grained Subtask and one team participated in the Open-Track NER Subtask. The winning teams achieved F-1 scores of 91% and 92% in the Flat Fine-Grained and Nested Fine-Grained Subtasks, respectively. The sole team in the Open-Track Subtask achieved an F-1 score of 73.7%.
WojoodNER 2023: The First Arabic Named Entity Recognition Shared Task
Oct 24, 2023



We present WojoodNER-2023, the first Arabic Named Entity Recognition (NER) Shared Task. The primary focus of WojoodNER-2023 is on Arabic NER, offering novel NER datasets (i.e., Wojood) and the definition of subtasks designed to facilitate meaningful comparisons between different NER approaches. WojoodNER-2023 encompassed two Subtasks: FlatNER and NestedNER. A total of 45 unique teams registered for this shared task, with 11 of them actively participating in the test phase. Specifically, 11 teams participated in FlatNER, while $8$ teams tackled NestedNER. The winning teams achieved F1 scores of 91.96 and 93.73 in FlatNER and NestedNER, respectively.
Offensive Hebrew Corpus and Detection using BERT
Sep 06, 2023
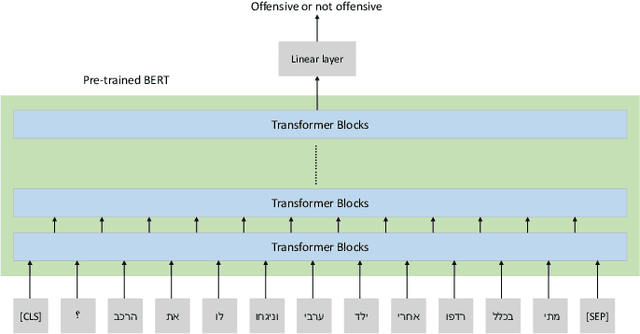

Offensive language detection has been well studied in many languages, but it is lagging behind in low-resource languages, such as Hebrew. In this paper, we present a new offensive language corpus in Hebrew. A total of 15,881 tweets were retrieved from Twitter. Each was labeled with one or more of five classes (abusive, hate, violence, pornographic, or none offensive) by Arabic-Hebrew bilingual speakers. The annotation process was challenging as each annotator is expected to be familiar with the Israeli culture, politics, and practices to understand the context of each tweet. We fine-tuned two Hebrew BERT models, HeBERT and AlephBERT, using our proposed dataset and another published dataset. We observed that our data boosts HeBERT performance by 2% when combined with D_OLaH. Fine-tuning AlephBERT on our data and testing on D_OLaH yields 69% accuracy, while fine-tuning on D_OLaH and testing on our data yields 57% accuracy, which may be an indication to the generalizability our data offers. Our dataset and fine-tuned models are available on GitHub and Huggingface.