 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlexandria: A Multi-Domain Dialectal Arabic Machine Translation Dataset for Culturally Inclusive and Linguistically Diverse LLMs
Jan 19, 2026Arabic is a highly diglossic language where most daily communication occurs in regional dialects rather than Modern Standard Arabic. Despite this, machine translation (MT) systems often generalize poorly to dialectal input, limiting their utility for millions of speakers. We introduce \textbf{Alexandria}, a large-scale, community-driven, human-translated dataset designed to bridge this gap. Alexandria covers 13 Arab countries and 11 high-impact domains, including health, education, and agriculture. Unlike previous resources, Alexandria provides unprecedented granularity by associating contributions with city-of-origin metadata, capturing authentic local varieties beyond coarse regional labels. The dataset consists of multi-turn conversational scenarios annotated with speaker-addressee gender configurations, enabling the study of gender-conditioned variation in dialectal use. Comprising 107K total samples, Alexandria serves as both a training resource and a rigorous benchmark for evaluating MT and Large Language Models (LLMs). Our automatic and human evaluation of Arabic-aware LLMs benchmarks current capabilities in translating across diverse Arabic dialects and sub-dialects, while exposing significant persistent challenges.
From RAG to Agentic RAG for Faithful Islamic Question Answering
Jan 12, 2026LLMs are increasingly used for Islamic question answering, where ungrounded responses may carry serious religious consequences. Yet standard MCQ/MRC-style evaluations do not capture key real-world failure modes, notably free-form hallucinations and whether models appropriately abstain when evidence is lacking. To shed a light on this aspect we introduce ISLAMICFAITHQA, a 3,810-item bilingual (Arabic/English) generative benchmark with atomic single-gold answers, which enables direct measurement of hallucination and abstention. We additionally developed an end-to-end grounded Islamic modelling suite consisting of (i) 25K Arabic text-grounded SFT reasoning pairs, (ii) 5K bilingual preference samples for reward-guided alignment, and (iii) a verse-level Qur'an retrieval corpus of $\sim$6k atomic verses (ayat). Building on these resources, we develop an agentic Quran-grounding framework (agentic RAG) that uses structured tool calls for iterative evidence seeking and answer revision. Experiments across Arabic-centric and multilingual LLMs show that retrieval improves correctness and that agentic RAG yields the largest gains beyond standard RAG, achieving state-of-the-art performance and stronger Arabic-English robustness even with a small model (i.e., Qwen3 4B). We will make the experimental resources and datasets publicly available for the community.
Konooz: Multi-domain Multi-dialect Corpus for Named Entity Recognition
Jun 14, 2025We introduce Konooz, a novel multi-dimensional corpus covering 16 Arabic dialects across 10 domains, resulting in 160 distinct corpora. The corpus comprises about 777k tokens, carefully collected and manually annotated with 21 entity types using both nested and flat annotation schemes - using the Wojood guidelines. While Konooz is useful for various NLP tasks like domain adaptation and transfer learning, this paper primarily focuses on benchmarking existing Arabic Named Entity Recognition (NER) models, especially cross-domain and cross-dialect model performance. Our benchmarking of four Arabic NER models using Konooz reveals a significant drop in performance of up to 38% when compared to the in-distribution data. Furthermore, we present an in-depth analysis of domain and dialect divergence and the impact of resource scarcity. We also measured the overlap between domains and dialects using the Maximum Mean Discrepancy (MMD) metric, and illustrated why certain NER models perform better on specific dialects and domains. Konooz is open-source and publicly available at https://sina.birzeit.edu/wojood/#download
Pearl: A Multimodal Culturally-Aware Arabic Instruction Dataset
May 28, 2025Mainstream large vision-language models (LVLMs) inherently encode cultural biases, highlighting the need for diverse multimodal datasets. To address this gap, we introduce Pearl, a large-scale Arabic multimodal dataset and benchmark explicitly designed for cultural understanding. Constructed through advanced agentic workflows and extensive human-in-the-loop annotations by 45 annotators from across the Arab world, Pearl comprises over K multimodal examples spanning ten culturally significant domains covering all Arab countries. We further provide two robust evaluation benchmarks Pearl and Pearl-Lite along with a specialized subset Pearl-X explicitly developed to assess nuanced cultural variations. Comprehensive evaluations on state-of-the-art open and proprietary LVLMs demonstrate that reasoning-centric instruction alignment substantially improves models' cultural grounding compared to conventional scaling methods. Pearl establishes a foundational resource for advancing culturally-informed multimodal modeling research. All datasets and benchmarks are publicly available.
SinaTools: Open Source Toolkit for Arabic Natural Language Processing
Nov 03, 2024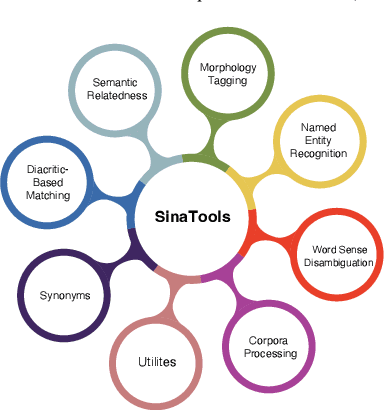
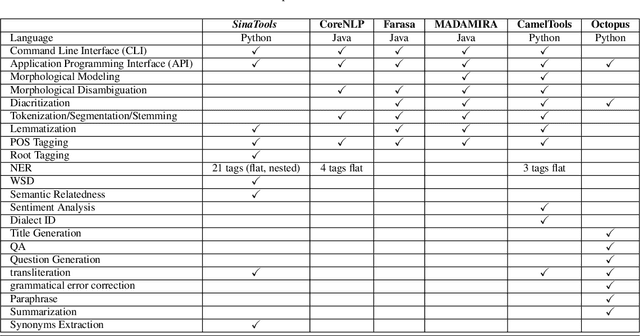
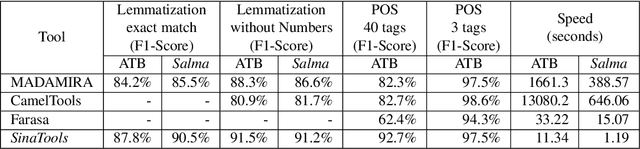
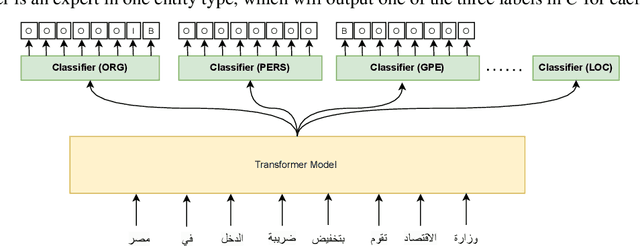
We introduce SinaTools, an open-source Python package for Arabic natural language processing and understanding. SinaTools is a unified package allowing people to integrate it into their system workflow, offering solutions for various tasks such as flat and nested Named Entity Recognition (NER), fully-flagged Word Sense Disambiguation (WSD), Semantic Relatedness, Synonymy Extractions and Evaluation, Lemmatization, Part-of-speech Tagging, Root Tagging, and additional helper utilities such as corpus processing, text stripping methods, and diacritic-aware word matching. This paper presents SinaTools and its benchmarking results, demonstrating that SinaTools outperforms all similar tools on the aforementioned tasks, such as Flat NER (87.33%), Nested NER (89.42%), WSD (82.63%), Semantic Relatedness (0.49 Spearman rank), Lemmatization (90.5%), POS tagging (97.5%), among others. SinaTools can be downloaded from (https://sina.birzeit.edu/sinatools).
Casablanca: Data and Models for Multidialectal Arabic Speech Recognition
Oct 06, 2024



In spite of the recent progress in speech processing, the majority of world languages and dialects remain uncovered. This situation only furthers an already wide technological divide, thereby hindering technological and socioeconomic inclusion. This challenge is largely due to the absence of datasets that can empower diverse speech systems. In this paper, we seek to mitigate this obstacle for a number of Arabic dialects by presenting Casablanca, a large-scale community-driven effort to collect and transcribe a multi-dialectal Arabic dataset. The dataset covers eight dialects: Algerian, Egyptian, Emirati, Jordanian, Mauritanian, Moroccan, Palestinian, and Yemeni, and includes annotations for transcription, gender, dialect, and code-switching. We also develop a number of strong baselines exploiting Casablanca. The project page for Casablanca is accessible at: www.dlnlp.ai/speech/casablanca.
Event-Arguments Extraction Corpus and Modeling using BERT for Arabic
Jul 30, 2024

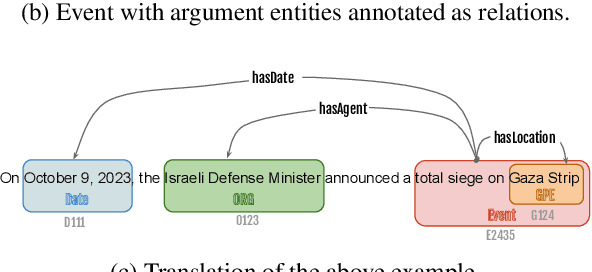

Event-argument extraction is a challenging task, particularly in Arabic due to sparse linguistic resources. To fill this gap, we introduce the \hadath corpus ($550$k tokens) as an extension of Wojood, enriched with event-argument annotations. We used three types of event arguments: $agent$, $location$, and $date$, which we annotated as relation types. Our inter-annotator agreement evaluation resulted in $82.23\%$ $Kappa$ score and $87.2\%$ $F_1$-score. Additionally, we propose a novel method for event relation extraction using BERT, in which we treat the task as text entailment. This method achieves an $F_1$-score of $94.01\%$. To further evaluate the generalization of our proposed method, we collected and annotated another out-of-domain corpus (about $80$k tokens) called \testNLI and used it as a second test set, on which our approach achieved promising results ($83.59\%$ $F_1$-score). Last but not least, we propose an end-to-end system for event-arguments extraction. This system is implemented as part of SinaTools, and both corpora are publicly available at {\small \url{https://sina.birzeit.edu/wojood}}
ArabicNLU 2024: The First Arabic Natural Language Understanding Shared Task
Jul 30, 2024

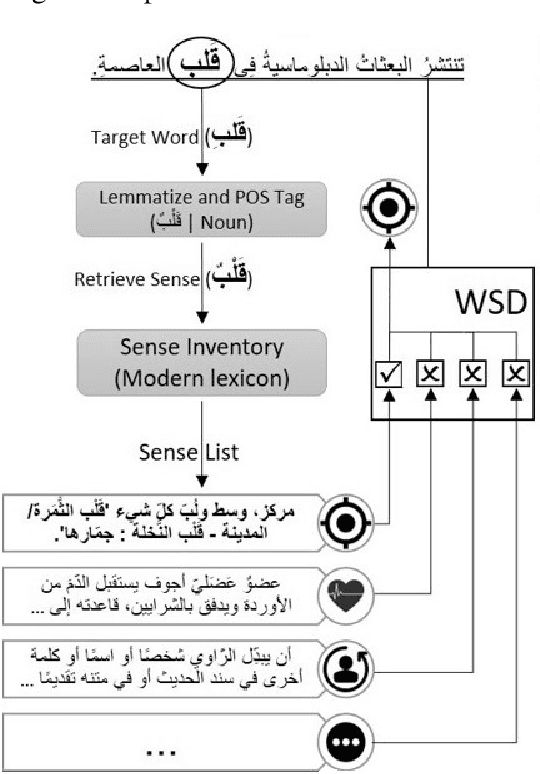
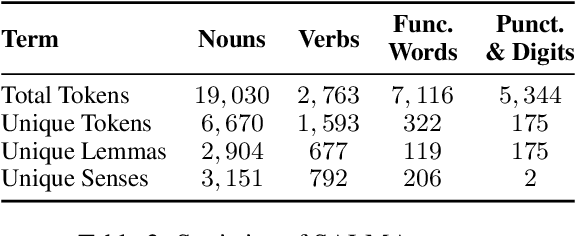
This paper presents an overview of the Arabic Natural Language Understanding (ArabicNLU 2024) shared task, focusing on two subtasks: Word Sense Disambiguation (WSD) and Location Mention Disambiguation (LMD). The task aimed to evaluate the ability of automated systems to resolve word ambiguity and identify locations mentioned in Arabic text. We provided participants with novel datasets, including a sense-annotated corpus for WSD, called SALMA with approximately 34k annotated tokens, and the IDRISI-DA dataset with 3,893 annotations and 763 unique location mentions. These are challenging tasks. Out of the 38 registered teams, only three teams participated in the final evaluation phase, with the highest accuracy being 77.8% for WSD and the highest MRR@1 being 95.0% for LMD. The shared task not only facilitated the evaluation and comparison of different techniques, but also provided valuable insights and resources for the continued advancement of Arabic NLU technologies.
The FIGNEWS Shared Task on News Media Narratives
Jul 25, 2024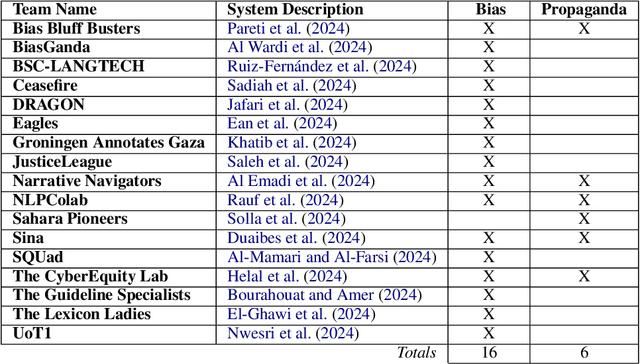
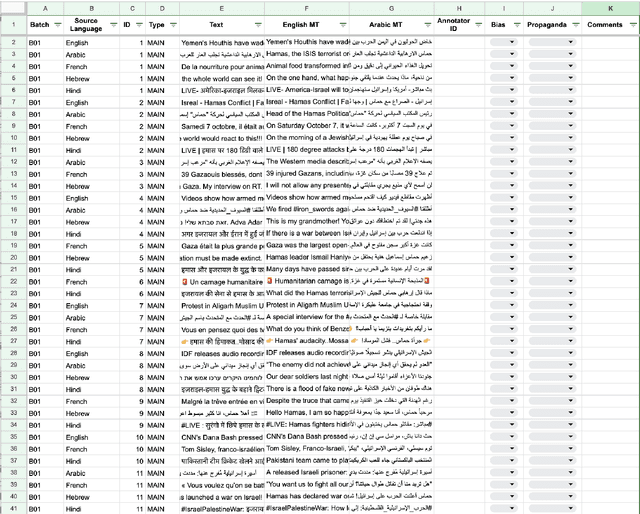
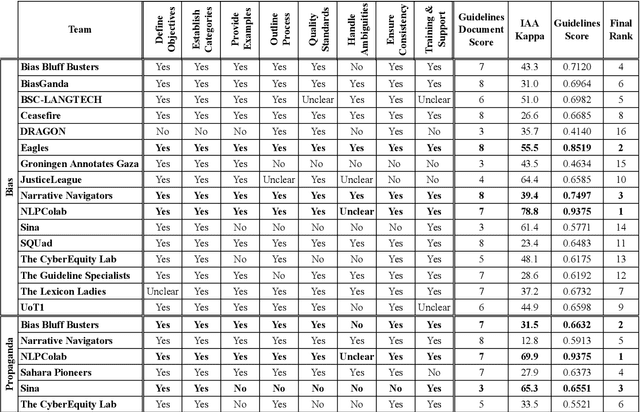
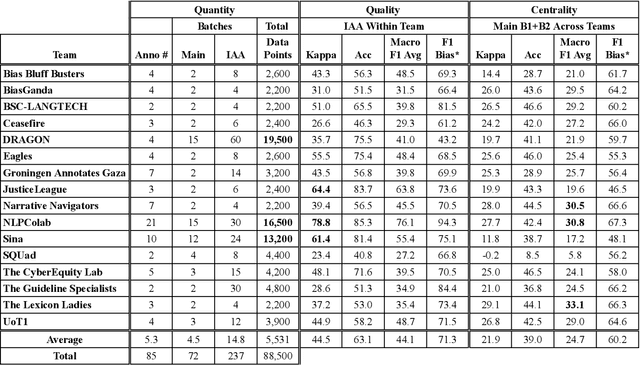
We present an overview of the FIGNEWS shared task, organized as part of the ArabicNLP 2024 conference co-located with ACL 2024. The shared task addresses bias and propaganda annotation in multilingual news posts. We focus on the early days of the Israel War on Gaza as a case study. The task aims to foster collaboration in developing annotation guidelines for subjective tasks by creating frameworks for analyzing diverse narratives highlighting potential bias and propaganda. In a spirit of fostering and encouraging diversity, we address the problem from a multilingual perspective, namely within five languages: English, French, Arabic, Hebrew, and Hindi. A total of 17 teams participated in two annotation subtasks: bias (16 teams) and propaganda (6 teams). The teams competed in four evaluation tracks: guidelines development, annotation quality, annotation quantity, and consistency. Collectively, the teams produced 129,800 data points. Key findings and implications for the field are discussed.
AraFinNLP 2024: The First Arabic Financial NLP Shared Task
Jul 13, 2024



The expanding financial markets of the Arab world require sophisticated Arabic NLP tools. To address this need within the banking domain, the Arabic Financial NLP (AraFinNLP) shared task proposes two subtasks: (i) Multi-dialect Intent Detection and (ii) Cross-dialect Translation and Intent Preservation. This shared task uses the updated ArBanking77 dataset, which includes about 39k parallel queries in MSA and four dialects. Each query is labeled with one or more of a common 77 intents in the banking domain. These resources aim to foster the development of robust financial Arabic NLP, particularly in the areas of machine translation and banking chat-bots. A total of 45 unique teams registered for this shared task, with 11 of them actively participated in the test phase. Specifically, 11 teams participated in Subtask 1, while only 1 team participated in Subtask 2. The winning team of Subtask 1 achieved F1 score of 0.8773, and the only team submitted in Subtask 2 achieved a 1.667 BLEU score.