 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlexandria: A Multi-Domain Dialectal Arabic Machine Translation Dataset for Culturally Inclusive and Linguistically Diverse LLMs
Jan 19, 2026Arabic is a highly diglossic language where most daily communication occurs in regional dialects rather than Modern Standard Arabic. Despite this, machine translation (MT) systems often generalize poorly to dialectal input, limiting their utility for millions of speakers. We introduce \textbf{Alexandria}, a large-scale, community-driven, human-translated dataset designed to bridge this gap. Alexandria covers 13 Arab countries and 11 high-impact domains, including health, education, and agriculture. Unlike previous resources, Alexandria provides unprecedented granularity by associating contributions with city-of-origin metadata, capturing authentic local varieties beyond coarse regional labels. The dataset consists of multi-turn conversational scenarios annotated with speaker-addressee gender configurations, enabling the study of gender-conditioned variation in dialectal use. Comprising 107K total samples, Alexandria serves as both a training resource and a rigorous benchmark for evaluating MT and Large Language Models (LLMs). Our automatic and human evaluation of Arabic-aware LLMs benchmarks current capabilities in translating across diverse Arabic dialects and sub-dialects, while exposing significant persistent challenges.
Pearl: A Multimodal Culturally-Aware Arabic Instruction Dataset
May 28, 2025Mainstream large vision-language models (LVLMs) inherently encode cultural biases, highlighting the need for diverse multimodal datasets. To address this gap, we introduce Pearl, a large-scale Arabic multimodal dataset and benchmark explicitly designed for cultural understanding. Constructed through advanced agentic workflows and extensive human-in-the-loop annotations by 45 annotators from across the Arab world, Pearl comprises over K multimodal examples spanning ten culturally significant domains covering all Arab countries. We further provide two robust evaluation benchmarks Pearl and Pearl-Lite along with a specialized subset Pearl-X explicitly developed to assess nuanced cultural variations. Comprehensive evaluations on state-of-the-art open and proprietary LVLMs demonstrate that reasoning-centric instruction alignment substantially improves models' cultural grounding compared to conventional scaling methods. Pearl establishes a foundational resource for advancing culturally-informed multimodal modeling research. All datasets and benchmarks are publicly available.
Swan and ArabicMTEB: Dialect-Aware, Arabic-Centric, Cross-Lingual, and Cross-Cultural Embedding Models and Benchmarks
Nov 02, 2024



We introduce Swan, a family of embedding models centred around the Arabic language, addressing both small-scale and large-scale use cases. Swan includes two variants: Swan-Small, based on ARBERTv2, and Swan-Large, built on ArMistral, a pretrained Arabic large language model. To evaluate these models, we propose ArabicMTEB, a comprehensive benchmark suite that assesses cross-lingual, multi-dialectal, multi-domain, and multi-cultural Arabic text embedding performance, covering eight diverse tasks and spanning 94 datasets. Swan-Large achieves state-of-the-art results, outperforming Multilingual-E5-large in most Arabic tasks, while the Swan-Small consistently surpasses Multilingual-E5 base. Our extensive evaluations demonstrate that Swan models are both dialectally and culturally aware, excelling across various Arabic domains while offering significant monetary efficiency. This work significantly advances the field of Arabic language modelling and provides valuable resources for future research and applications in Arabic natural language processing. Our models and benchmark will be made publicly accessible for research.
Gazelle: An Instruction Dataset for Arabic Writing Assistance
Oct 23, 2024



Writing has long been considered a hallmark of human intelligence and remains a pinnacle task for artificial intelligence (AI) due to the intricate cognitive processes involved. Recently, rapid advancements in generative AI, particularly through the development of Large Language Models (LLMs), have significantly transformed the landscape of writing assistance. However, underrepresented languages like Arabic encounter significant challenges in the development of advanced AI writing tools, largely due to the limited availability of data. This scarcity constrains the training of effective models, impeding the creation of sophisticated writing assistance technologies. To address these issues, we present Gazelle, a comprehensive dataset for Arabic writing assistance. In addition, we offer an evaluation framework designed to enhance Arabic writing assistance tools. Our human evaluation of leading LLMs, including GPT-4, GPT-4o, Cohere Command R+, and Gemini 1.5 Pro, highlights their respective strengths and limitations in addressing the challenges of Arabic writing. Our findings underscore the need for continuous model training and dataset enrichment to manage the complexities of Arabic language processing, paving the way for more effective AI-powered Arabic writing tools.
Casablanca: Data and Models for Multidialectal Arabic Speech Recognition
Oct 06, 2024



In spite of the recent progress in speech processing, the majority of world languages and dialects remain uncovered. This situation only furthers an already wide technological divide, thereby hindering technological and socioeconomic inclusion. This challenge is largely due to the absence of datasets that can empower diverse speech systems. In this paper, we seek to mitigate this obstacle for a number of Arabic dialects by presenting Casablanca, a large-scale community-driven effort to collect and transcribe a multi-dialectal Arabic dataset. The dataset covers eight dialects: Algerian, Egyptian, Emirati, Jordanian, Mauritanian, Moroccan, Palestinian, and Yemeni, and includes annotations for transcription, gender, dialect, and code-switching. We also develop a number of strong baselines exploiting Casablanca. The project page for Casablanca is accessible at: www.dlnlp.ai/speech/casablanca.
Dallah: A Dialect-Aware Multimodal Large Language Model for Arabic
Jul 26, 2024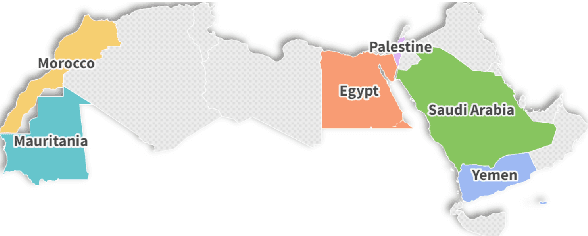
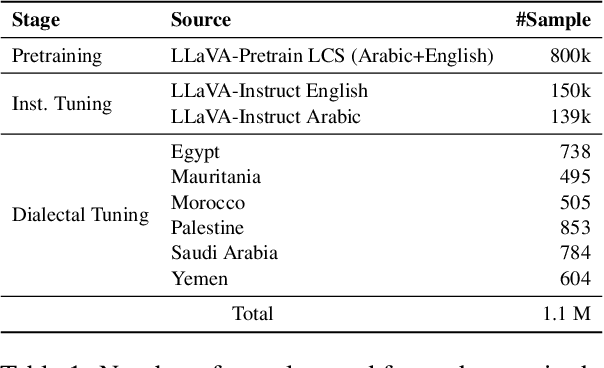
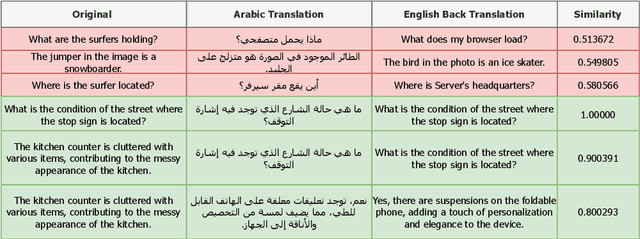
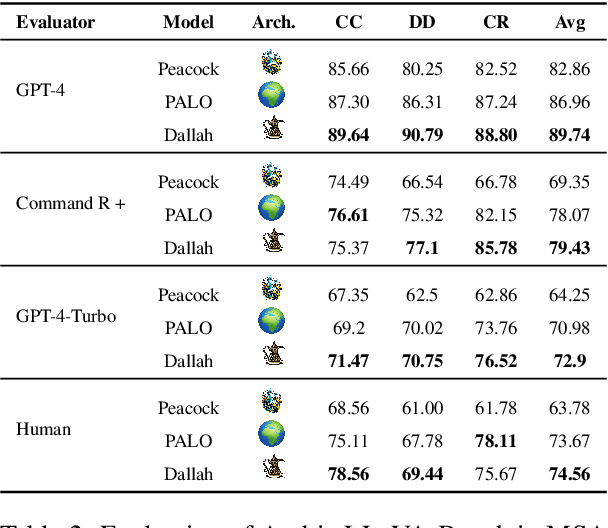
Recent advancements have significantly enhanced the capabilities of Multimodal Large Language Models (MLLMs) in generating and understanding image-to-text content. Despite these successes, progress is predominantly limited to English due to the scarcity of high quality multimodal resources in other languages. This limitation impedes the development of competitive models in languages such as Arabic. To alleviate this situation, we introduce an efficient Arabic multimodal assistant, dubbed Dallah, that utilizes an advanced language model based on LLaMA-2 to facilitate multimodal interactions. Dallah demonstrates state-of-the-art performance in Arabic MLLMs. Through fine-tuning six Arabic dialects, Dallah showcases its capability to handle complex dialectal interactions incorporating both textual and visual elements. The model excels in two benchmark tests: one evaluating its performance on Modern Standard Arabic (MSA) and another specifically designed to assess dialectal responses. Beyond its robust performance in multimodal interaction tasks, Dallah has the potential to pave the way for further development of dialect-aware Arabic MLLMs.
Qalam : A Multimodal LLM for Arabic Optical Character and Handwriting Recognition
Jul 18, 2024
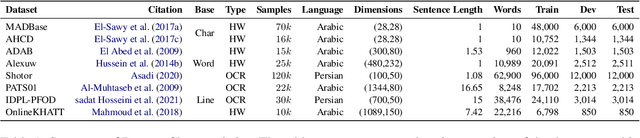
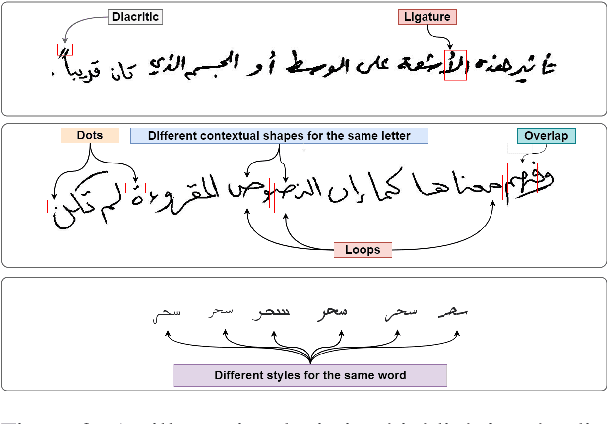
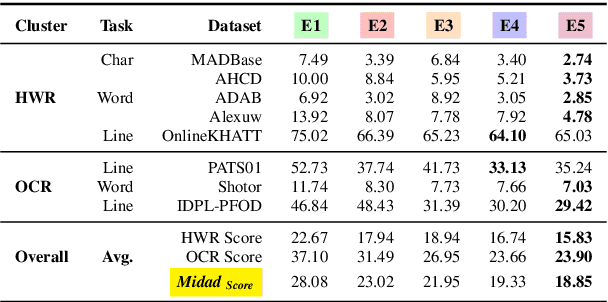
Arabic Optical Character Recognition (OCR) and Handwriting Recognition (HWR) pose unique challenges due to the cursive and context-sensitive nature of the Arabic script. This study introduces Qalam, a novel foundation model designed for Arabic OCR and HWR, built on a SwinV2 encoder and RoBERTa decoder architecture. Our model significantly outperforms existing methods, achieving a Word Error Rate (WER) of just 0.80% in HWR tasks and 1.18% in OCR tasks. We train Qalam on a diverse dataset, including over 4.5 million images from Arabic manuscripts and a synthetic dataset comprising 60k image-text pairs. Notably, Qalam demonstrates exceptional handling of Arabic diacritics, a critical feature in Arabic scripts. Furthermore, it shows a remarkable ability to process high-resolution inputs, addressing a common limitation in current OCR systems. These advancements underscore Qalam's potential as a leading solution for Arabic script recognition, offering a significant leap in accuracy and efficiency.
Arabic Automatic Story Generation with Large Language Models
Jul 10, 2024


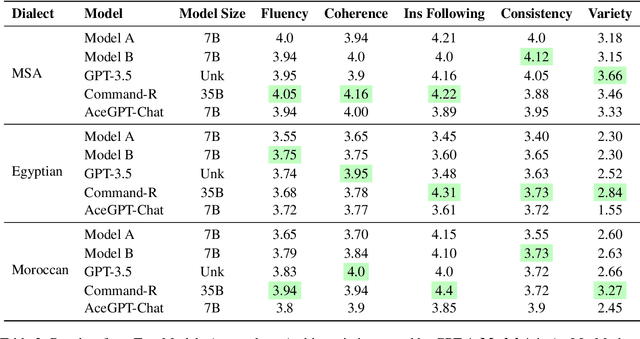
Large language models (LLMs) have recently emerged as a powerful tool for a wide range of language generation tasks. Nevertheless, this progress has been slower in Arabic. In this work, we focus on the task of generating stories from LLMs. For our training, we use stories acquired through machine translation (MT) as well as GPT-4. For the MT data, we develop a careful pipeline that ensures we acquire high-quality stories. For our GPT-41 data, we introduce crafted prompts that allow us to generate data well-suited to the Arabic context in both Modern Standard Arabic (MSA) and two Arabic dialects (Egyptian and Moroccan). For example, we generate stories tailored to various Arab countries on a wide host of topics. Our manual evaluation shows that our model fine-tuned on these training datasets can generate coherent stories that adhere to our instructions. We also conduct an extensive automatic and human evaluation comparing our models against state-of-the-art proprietary and open-source models. Our datasets and models will be made publicly available at https: //github.com/UBC-NLP/arastories.
Peacock: A Family of Arabic Multimodal Large Language Models and Benchmarks
Mar 01, 2024



Multimodal large language models (MLLMs) have proven effective in a wide range of tasks requiring complex reasoning and linguistic comprehension. However, due to a lack of high-quality multimodal resources in languages other than English, success of MLLMs remains relatively limited to English-based settings. This poses significant challenges in developing comparable models for other languages, including even those with large speaker populations such as Arabic. To alleviate this challenge, we introduce a comprehensive family of Arabic MLLMs, dubbed \textit{Peacock}, with strong vision and language capabilities. Through comprehensive qualitative and quantitative analysis, we demonstrate the solid performance of our models on various visual reasoning tasks and further show their emerging dialectal potential. Additionally, we introduce ~\textit{Henna}, a new benchmark specifically designed for assessing MLLMs on aspects related to Arabic culture, setting the first stone for culturally-aware Arabic MLLMs.The GitHub repository for the \textit{Peacock} project is available at \url{https://github.com/UBC-NLP/peacock}.
Violet: A Vision-Language Model for Arabic Image Captioning with Gemini Decoder
Nov 15, 2023
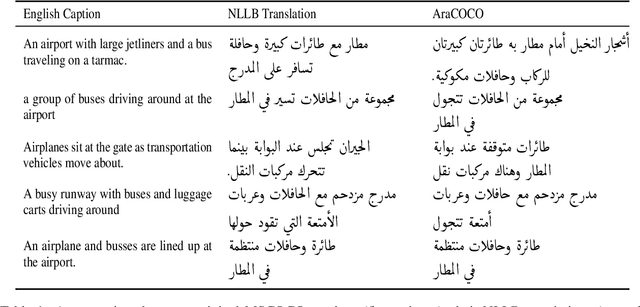


Although image captioning has a vast array of applications, it has not reached its full potential in languages other than English. Arabic, for instance, although the native language of more than 400 million people, remains largely underrepresented in this area. This is due to the lack of labeled data and powerful Arabic generative models. We alleviate this issue by presenting a novel vision-language model dedicated to Arabic, dubbed \textit{Violet}. Our model is based on a vision encoder and a Gemini text decoder that maintains generation fluency while allowing fusion between the vision and language components. To train our model, we introduce a new method for automatically acquiring data from available English datasets. We also manually prepare a new dataset for evaluation. \textit{Violet} performs sizeably better than our baselines on all of our evaluation datasets. For example, it reaches a CIDEr score of $61.2$ on our manually annotated dataset and achieves an improvement of $13$ points on Flickr8k.