 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArab Voices: Mapping Standard and Dialectal Arabic Speech Technology
Jan 19, 2026Dialectal Arabic (DA) speech data vary widely in domain coverage, dialect labeling practices, and recording conditions, complicating cross-dataset comparison and model evaluation. To characterize this landscape, we conduct a computational analysis of linguistic ``dialectness'' alongside objective proxies of audio quality on the training splits of widely used DA corpora. We find substantial heterogeneity both in acoustic conditions and in the strength and consistency of dialectal signals across datasets, underscoring the need for standardized characterization beyond coarse labels. To reduce fragmentation and support reproducible evaluation, we introduce Arab Voices, a standardized framework for DA ASR. Arab Voices provides unified access to 31 datasets spanning 14 dialects, with harmonized metadata and evaluation utilities. We further benchmark a range of recent ASR systems, establishing strong baselines for modern DA ASR.
Pearl: A Multimodal Culturally-Aware Arabic Instruction Dataset
May 28, 2025Mainstream large vision-language models (LVLMs) inherently encode cultural biases, highlighting the need for diverse multimodal datasets. To address this gap, we introduce Pearl, a large-scale Arabic multimodal dataset and benchmark explicitly designed for cultural understanding. Constructed through advanced agentic workflows and extensive human-in-the-loop annotations by 45 annotators from across the Arab world, Pearl comprises over K multimodal examples spanning ten culturally significant domains covering all Arab countries. We further provide two robust evaluation benchmarks Pearl and Pearl-Lite along with a specialized subset Pearl-X explicitly developed to assess nuanced cultural variations. Comprehensive evaluations on state-of-the-art open and proprietary LVLMs demonstrate that reasoning-centric instruction alignment substantially improves models' cultural grounding compared to conventional scaling methods. Pearl establishes a foundational resource for advancing culturally-informed multimodal modeling research. All datasets and benchmarks are publicly available.
Voice of a Continent: Mapping Africa's Speech Technology Frontier
May 24, 2025Africa's rich linguistic diversity remains significantly underrepresented in speech technologies, creating barriers to digital inclusion. To alleviate this challenge, we systematically map the continent's speech space of datasets and technologies, leading to a new comprehensive benchmark SimbaBench for downstream African speech tasks. Using SimbaBench, we introduce the Simba family of models, achieving state-of-the-art performance across multiple African languages and speech tasks. Our benchmark analysis reveals critical patterns in resource availability, while our model evaluation demonstrates how dataset quality, domain diversity, and language family relationships influence performance across languages. Our work highlights the need for expanded speech technology resources that better reflect Africa's linguistic diversity and provides a solid foundation for future research and development efforts toward more inclusive speech technologies.
Violet: A Vision-Language Model for Arabic Image Captioning with Gemini Decoder
Nov 15, 2023
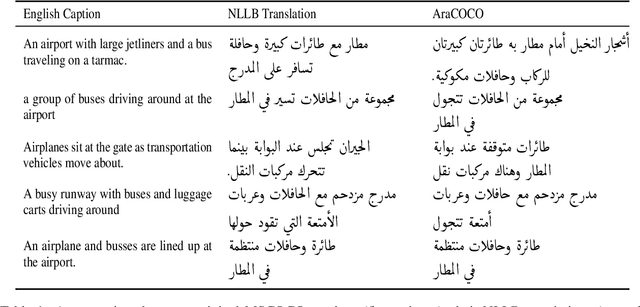


Although image captioning has a vast array of applications, it has not reached its full potential in languages other than English. Arabic, for instance, although the native language of more than 400 million people, remains largely underrepresented in this area. This is due to the lack of labeled data and powerful Arabic generative models. We alleviate this issue by presenting a novel vision-language model dedicated to Arabic, dubbed \textit{Violet}. Our model is based on a vision encoder and a Gemini text decoder that maintains generation fluency while allowing fusion between the vision and language components. To train our model, we introduce a new method for automatically acquiring data from available English datasets. We also manually prepare a new dataset for evaluation. \textit{Violet} performs sizeably better than our baselines on all of our evaluation datasets. For example, it reaches a CIDEr score of $61.2$ on our manually annotated dataset and achieves an improvement of $13$ points on Flickr8k.
Zero-Shot Slot and Intent Detection in Low-Resource Languages
Apr 26, 2023Intent detection and slot filling are critical tasks in spoken and natural language understanding for task-oriented dialog systems. In this work we describe our participation in the slot and intent detection for low-resource language varieties (SID4LR; Aepli et al. (2023)). We investigate the slot and intent detection (SID) tasks using a wide range of models and settings. Given the recent success of multitask-prompted finetuning of large language models, we also test the generalization capability of the recent encoder-decoder model mT0 (Muennighoff et al., 2022) on new tasks (i.e., SID) in languages they have never intentionally seen. We show that our best model outperforms the baseline by a large margin (up to +30 F1 points) in both SID tasks
JASMINE: Arabic GPT Models for Few-Shot Learning
Dec 21, 2022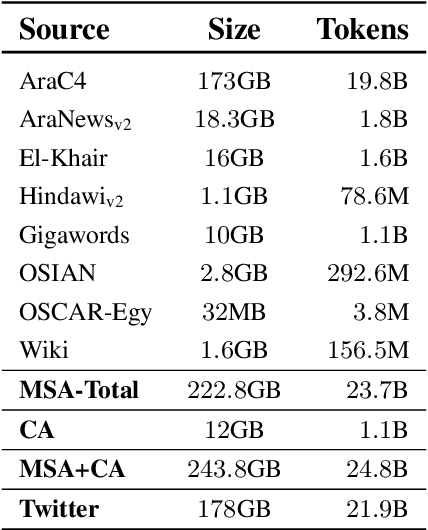
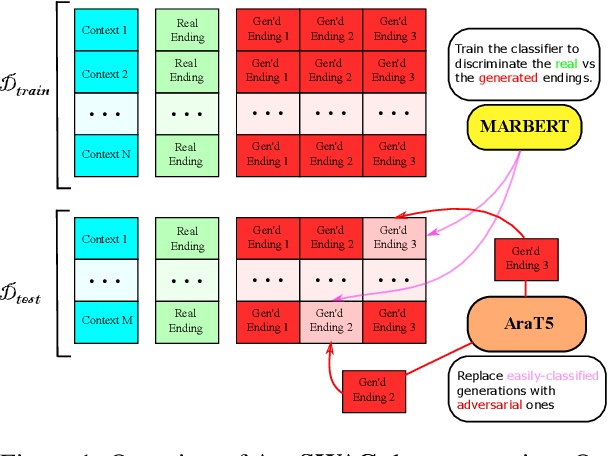
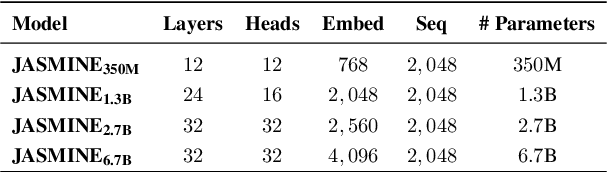
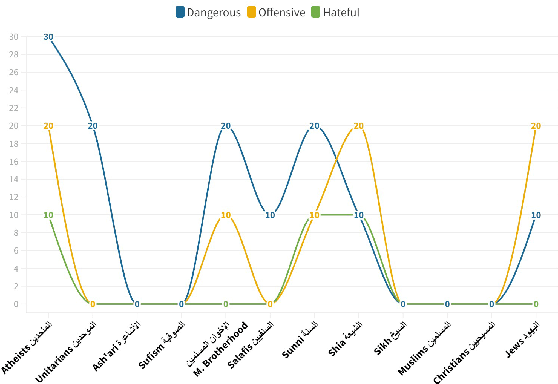
Task agnostic generative pretraining (GPT) has recently proved promising for zero- and few-shot learning, gradually diverting attention from the expensive supervised learning paradigm. Although the community is accumulating knowledge as to capabilities of English-language autoregressive models such as GPT-3 adopting this generative approach, scholarship about these models remains acutely Anglocentric. Consequently, the community currently has serious gaps in its understanding of this class of models, their potential, and their societal impacts in diverse settings, linguistic traditions, and cultures. To alleviate this issue for Arabic, a collection of diverse languages and language varieties with more than $400$ million population, we introduce JASMINE, a suite of powerful Arabic autoregressive Transformer language models ranging in size between 300 million-13 billion parameters. We pretrain our new models with large amounts of diverse data (400GB of text) from different Arabic varieties and domains. We evaluate JASMINE extensively in both intrinsic and extrinsic settings, using a comprehensive benchmark for zero- and few-shot learning across a wide range of NLP tasks. We also carefully develop and release a novel benchmark for both automated and human evaluation of Arabic autoregressive models focused at investigating potential social biases, harms, and toxicity in these models. We aim to responsibly release our models with interested researchers, along with code for experimenting with them
SERENGETI: Massively Multilingual Language Models for Africa
Dec 21, 2022Multilingual language models (MLMs) acquire valuable, generalizable linguistic information during pretraining and have advanced the state of the art on task-specific finetuning. So far, only ~ 28 out of ~2,000 African languages are covered in existing language models. We ameliorate this limitation by developing SERENGETI, a set of massively multilingual language model that covers 517 African languages and language varieties. We evaluate our novel models on eight natural language understanding tasks across 20 datasets, comparing to four MLMs that each cover any number of African languages. SERENGETI outperforms other models on 11 datasets across the eights tasks and achieves 82.27 average F-1. We also perform error analysis on our models' performance and show the influence of mutual intelligibility when the models are applied under zero-shot settings. We will publicly release our models for research.