 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSwan and ArabicMTEB: Dialect-Aware, Arabic-Centric, Cross-Lingual, and Cross-Cultural Embedding Models and Benchmarks
Nov 02, 2024



We introduce Swan, a family of embedding models centred around the Arabic language, addressing both small-scale and large-scale use cases. Swan includes two variants: Swan-Small, based on ARBERTv2, and Swan-Large, built on ArMistral, a pretrained Arabic large language model. To evaluate these models, we propose ArabicMTEB, a comprehensive benchmark suite that assesses cross-lingual, multi-dialectal, multi-domain, and multi-cultural Arabic text embedding performance, covering eight diverse tasks and spanning 94 datasets. Swan-Large achieves state-of-the-art results, outperforming Multilingual-E5-large in most Arabic tasks, while the Swan-Small consistently surpasses Multilingual-E5 base. Our extensive evaluations demonstrate that Swan models are both dialectally and culturally aware, excelling across various Arabic domains while offering significant monetary efficiency. This work significantly advances the field of Arabic language modelling and provides valuable resources for future research and applications in Arabic natural language processing. Our models and benchmark will be made publicly accessible for research.
Casablanca: Data and Models for Multidialectal Arabic Speech Recognition
Oct 06, 2024



In spite of the recent progress in speech processing, the majority of world languages and dialects remain uncovered. This situation only furthers an already wide technological divide, thereby hindering technological and socioeconomic inclusion. This challenge is largely due to the absence of datasets that can empower diverse speech systems. In this paper, we seek to mitigate this obstacle for a number of Arabic dialects by presenting Casablanca, a large-scale community-driven effort to collect and transcribe a multi-dialectal Arabic dataset. The dataset covers eight dialects: Algerian, Egyptian, Emirati, Jordanian, Mauritanian, Moroccan, Palestinian, and Yemeni, and includes annotations for transcription, gender, dialect, and code-switching. We also develop a number of strong baselines exploiting Casablanca. The project page for Casablanca is accessible at: www.dlnlp.ai/speech/casablanca.
Qalam : A Multimodal LLM for Arabic Optical Character and Handwriting Recognition
Jul 18, 2024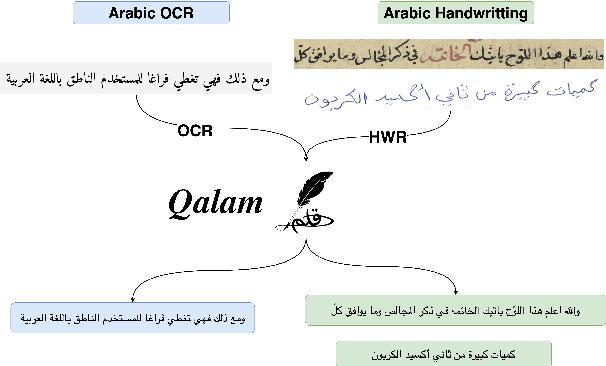
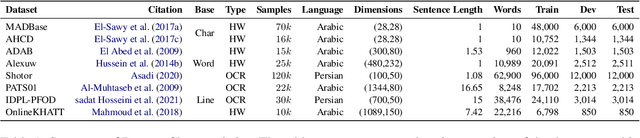
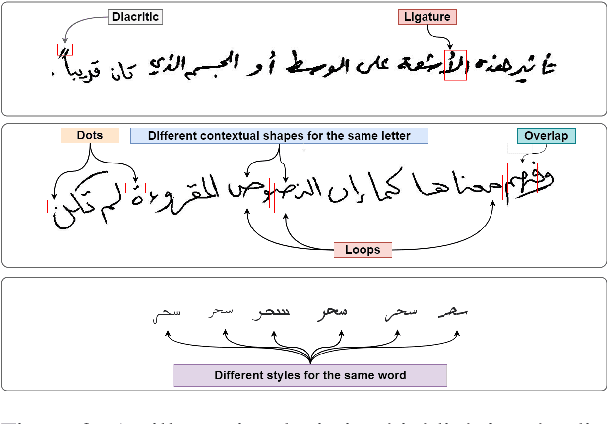
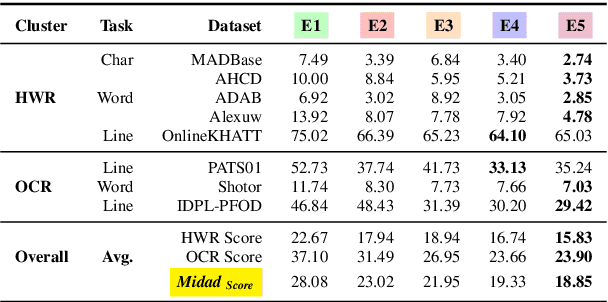
Arabic Optical Character Recognition (OCR) and Handwriting Recognition (HWR) pose unique challenges due to the cursive and context-sensitive nature of the Arabic script. This study introduces Qalam, a novel foundation model designed for Arabic OCR and HWR, built on a SwinV2 encoder and RoBERTa decoder architecture. Our model significantly outperforms existing methods, achieving a Word Error Rate (WER) of just 0.80% in HWR tasks and 1.18% in OCR tasks. We train Qalam on a diverse dataset, including over 4.5 million images from Arabic manuscripts and a synthetic dataset comprising 60k image-text pairs. Notably, Qalam demonstrates exceptional handling of Arabic diacritics, a critical feature in Arabic scripts. Furthermore, it shows a remarkable ability to process high-resolution inputs, addressing a common limitation in current OCR systems. These advancements underscore Qalam's potential as a leading solution for Arabic script recognition, offering a significant leap in accuracy and efficiency.
Peacock: A Family of Arabic Multimodal Large Language Models and Benchmarks
Mar 01, 2024



Multimodal large language models (MLLMs) have proven effective in a wide range of tasks requiring complex reasoning and linguistic comprehension. However, due to a lack of high-quality multimodal resources in languages other than English, success of MLLMs remains relatively limited to English-based settings. This poses significant challenges in developing comparable models for other languages, including even those with large speaker populations such as Arabic. To alleviate this challenge, we introduce a comprehensive family of Arabic MLLMs, dubbed \textit{Peacock}, with strong vision and language capabilities. Through comprehensive qualitative and quantitative analysis, we demonstrate the solid performance of our models on various visual reasoning tasks and further show their emerging dialectal potential. Additionally, we introduce ~\textit{Henna}, a new benchmark specifically designed for assessing MLLMs on aspects related to Arabic culture, setting the first stone for culturally-aware Arabic MLLMs.The GitHub repository for the \textit{Peacock} project is available at \url{https://github.com/UBC-NLP/peacock}.
FinTral: A Family of GPT-4 Level Multimodal Financial Large Language Models
Feb 16, 2024



We introduce FinTral, a suite of state-of-the-art multimodal large language models (LLMs) built upon the Mistral-7b model and tailored for financial analysis. FinTral integrates textual, numerical, tabular, and image data. We enhance FinTral with domain-specific pretraining, instruction fine-tuning, and RLAIF training by exploiting a large collection of textual and visual datasets we curate for this work. We also introduce an extensive benchmark featuring nine tasks and 25 datasets for evaluation, including hallucinations in the financial domain. Our FinTral model trained with direct preference optimization employing advanced Tools and Retrieval methods, dubbed FinTral-DPO-T&R, demonstrates an exceptional zero-shot performance. It outperforms ChatGPT-3.5 in all tasks and surpasses GPT-4 in five out of nine tasks, marking a significant advancement in AI-driven financial technology. We also demonstrate that FinTral has the potential to excel in real-time analysis and decision-making in diverse financial contexts.
Beyond English: Evaluating LLMs for Arabic Grammatical Error Correction
Dec 13, 2023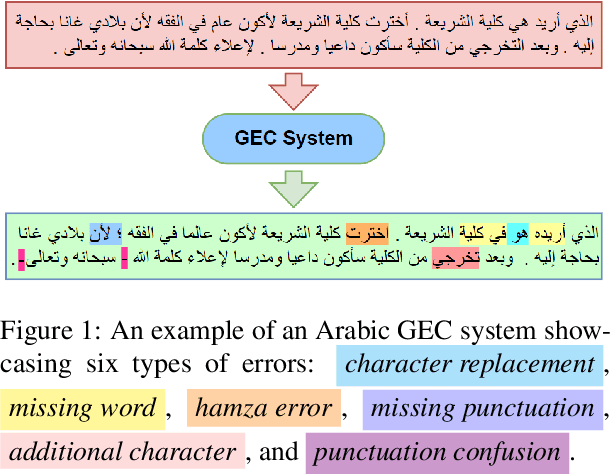
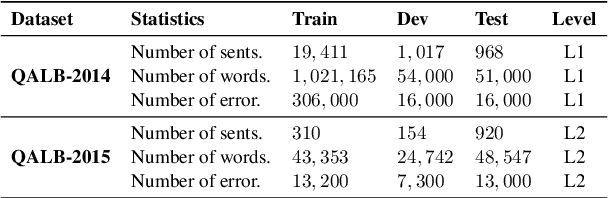
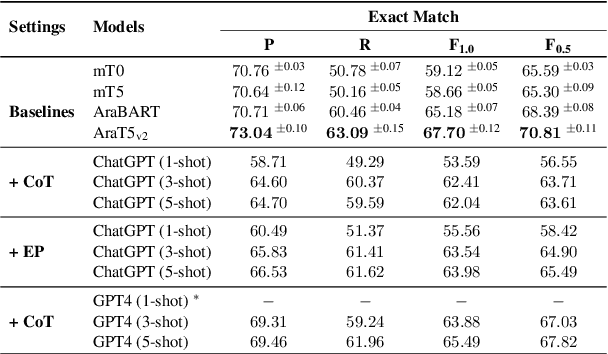

Large language models (LLMs) finetuned to follow human instruction have recently exhibited significant capabilities in various English NLP tasks. However, their performance in grammatical error correction (GEC), especially on languages other than English, remains significantly unexplored. In this work, we evaluate the abilities of instruction finetuned LLMs in Arabic GEC, a complex task due to Arabic's rich morphology. Our findings suggest that various prompting methods, coupled with (in-context) few-shot learning, demonstrate considerable effectiveness, with GPT-4 achieving up to $65.49$ F$_{1}$ score under expert prompting (approximately $5$ points higher than our established baseline). Despite these positive results, we find that instruction finetuned models, regardless of their size, are still outperformed by fully finetuned ones, even if they are significantly smaller in size. This disparity highlights substantial room for improvements for LLMs. Inspired by methods used in low-resource machine translation, we also develop a method exploiting synthetic data that significantly outperforms previous models on two standard Arabic benchmarks. Our best model achieves a new SOTA on Arabic GEC, with $73.29$ and $73.26$ F$_{1}$ on the 2014 and 2015 QALB datasets, respectively, compared to peer-reviewed published baselines.
Violet: A Vision-Language Model for Arabic Image Captioning with Gemini Decoder
Nov 15, 2023
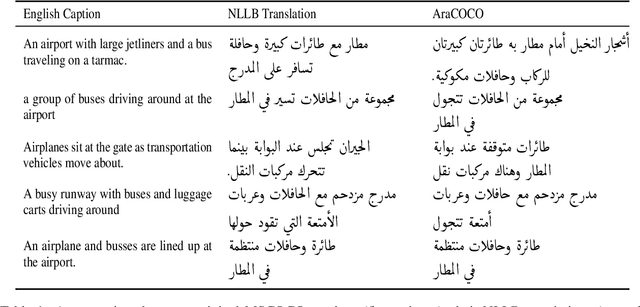


Although image captioning has a vast array of applications, it has not reached its full potential in languages other than English. Arabic, for instance, although the native language of more than 400 million people, remains largely underrepresented in this area. This is due to the lack of labeled data and powerful Arabic generative models. We alleviate this issue by presenting a novel vision-language model dedicated to Arabic, dubbed \textit{Violet}. Our model is based on a vision encoder and a Gemini text decoder that maintains generation fluency while allowing fusion between the vision and language components. To train our model, we introduce a new method for automatically acquiring data from available English datasets. We also manually prepare a new dataset for evaluation. \textit{Violet} performs sizeably better than our baselines on all of our evaluation datasets. For example, it reaches a CIDEr score of $61.2$ on our manually annotated dataset and achieves an improvement of $13$ points on Flickr8k.
NADI 2023: The Fourth Nuanced Arabic Dialect Identification Shared Task
Oct 24, 2023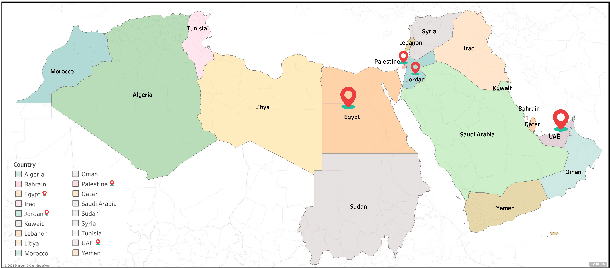
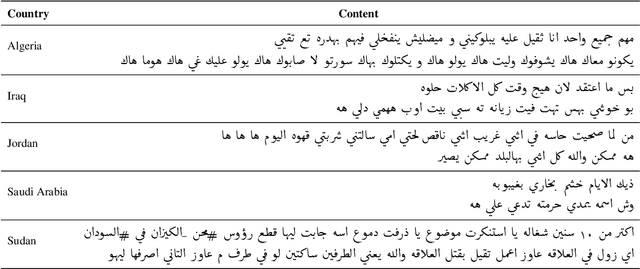

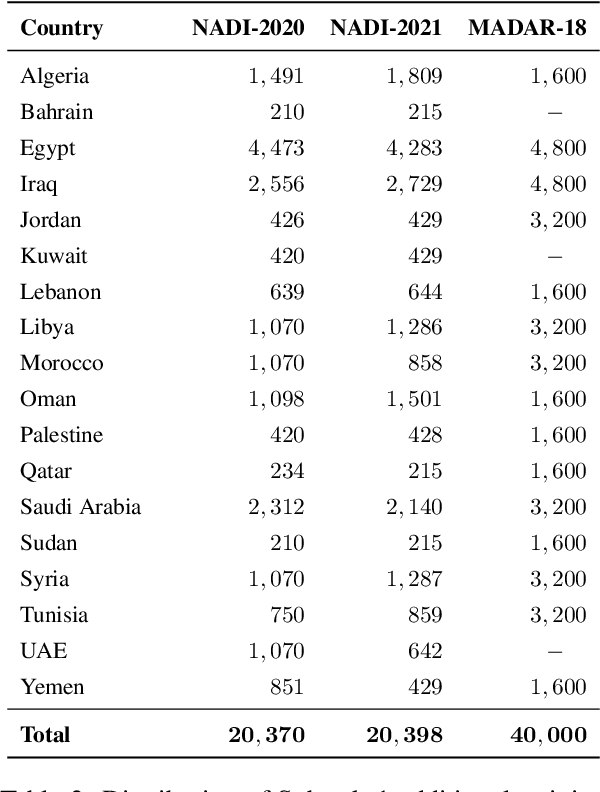
We describe the findings of the fourth Nuanced Arabic Dialect Identification Shared Task (NADI 2023). The objective of NADI is to help advance state-of-the-art Arabic NLP by creating opportunities for teams of researchers to collaboratively compete under standardized conditions. It does so with a focus on Arabic dialects, offering novel datasets and defining subtasks that allow for meaningful comparisons between different approaches. NADI 2023 targeted both dialect identification (Subtask 1) and dialect-to-MSA machine translation (Subtask 2 and Subtask 3). A total of 58 unique teams registered for the shared task, of whom 18 teams have participated (with 76 valid submissions during test phase). Among these, 16 teams participated in Subtask 1, 5 participated in Subtask 2, and 3 participated in Subtask 3. The winning teams achieved 87.27 F1 on Subtask 1, 14.76 Bleu in Subtask 2, and 21.10 Bleu in Subtask 3, respectively. Results show that all three subtasks remain challenging, thereby motivating future work in this area. We describe the methods employed by the participating teams and briefly offer an outlook for NADI.
Octopus: A Multitask Model and Toolkit for Arabic Natural Language Generation
Oct 24, 2023

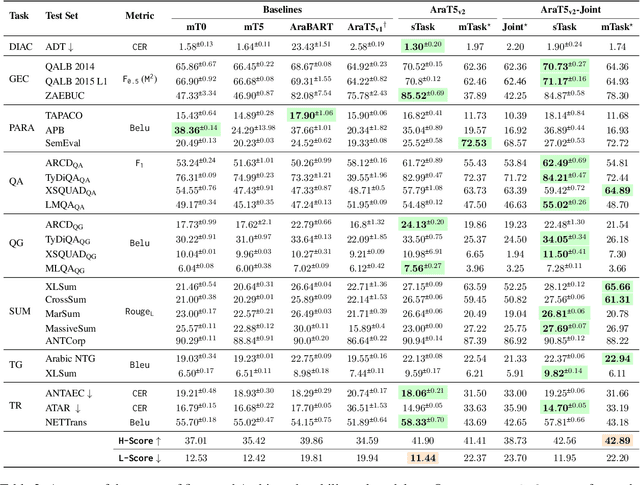
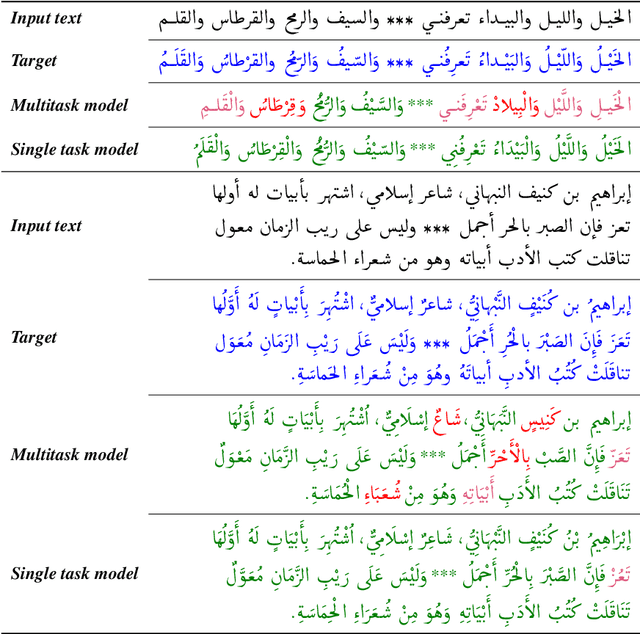
Understanding Arabic text and generating human-like responses is a challenging endeavor. While many researchers have proposed models and solutions for individual problems, there is an acute shortage of a comprehensive Arabic natural language generation toolkit that is capable of handling a wide range of tasks. In this work, we present a novel Arabic text-to-text Transformer model, namely AraT5v2. Our new model is methodically trained on extensive and diverse data, utilizing an extended sequence length of 2,048 tokens. We explore various pretraining strategies including unsupervised, supervised, and joint pertaining, under both single and multitask settings. Our models outperform competitive baselines with large margins. We take our work one step further by developing and publicly releasing Octopus, a Python-based package and command-line toolkit tailored for eight Arabic generation tasks all exploiting a single model. We release the models and the toolkit on our public repository.
TARJAMAT: Evaluation of Bard and ChatGPT on Machine Translation of Ten Arabic Varieties
Aug 06, 2023



Large language models (LLMs) finetuned to follow human instructions have recently emerged as a breakthrough in AI. Models such as Google Bard and OpenAI ChatGPT, for example, are surprisingly powerful tools for question answering, code debugging, and dialogue generation. Despite the purported multilingual proficiency of these models, their linguistic inclusivity remains insufficiently explored. Considering this constraint, we present a thorough assessment of Bard and ChatGPT (encompassing both GPT-3.5 and GPT-4) regarding their machine translation proficiencies across ten varieties of Arabic. Our evaluation covers diverse Arabic varieties such as Classical Arabic, Modern Standard Arabic, and several nuanced dialectal variants. Furthermore, we undertake a human-centric study to scrutinize the efficacy of the most recent model, Bard, in following human instructions during translation tasks. Our exhaustive analysis indicates that LLMs may encounter challenges with certain Arabic dialects, particularly those for which minimal public data exists, such as Algerian and Mauritanian dialects. However, they exhibit satisfactory performance with more prevalent dialects, albeit occasionally trailing behind established commercial systems like Google Translate. Additionally, our analysis reveals a circumscribed capability of Bard in aligning with human instructions in translation contexts. Collectively, our findings underscore that prevailing LLMs remain far from inclusive, with only limited ability to cater for the linguistic and cultural intricacies of diverse communities.