 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom RAG to Agentic RAG for Faithful Islamic Question Answering
Jan 12, 2026LLMs are increasingly used for Islamic question answering, where ungrounded responses may carry serious religious consequences. Yet standard MCQ/MRC-style evaluations do not capture key real-world failure modes, notably free-form hallucinations and whether models appropriately abstain when evidence is lacking. To shed a light on this aspect we introduce ISLAMICFAITHQA, a 3,810-item bilingual (Arabic/English) generative benchmark with atomic single-gold answers, which enables direct measurement of hallucination and abstention. We additionally developed an end-to-end grounded Islamic modelling suite consisting of (i) 25K Arabic text-grounded SFT reasoning pairs, (ii) 5K bilingual preference samples for reward-guided alignment, and (iii) a verse-level Qur'an retrieval corpus of $\sim$6k atomic verses (ayat). Building on these resources, we develop an agentic Quran-grounding framework (agentic RAG) that uses structured tool calls for iterative evidence seeking and answer revision. Experiments across Arabic-centric and multilingual LLMs show that retrieval improves correctness and that agentic RAG yields the largest gains beyond standard RAG, achieving state-of-the-art performance and stronger Arabic-English robustness even with a small model (i.e., Qwen3 4B). We will make the experimental resources and datasets publicly available for the community.
Prototypicality Bias Reveals Blindspots in Multimodal Evaluation Metrics
Jan 08, 2026Automatic metrics are now central to evaluating text-to-image models, often substituting for human judgment in benchmarking and large-scale filtering. However, it remains unclear whether these metrics truly prioritize semantic correctness or instead favor visually and socially prototypical images learned from biased data distributions. We identify and study \emph{prototypicality bias} as a systematic failure mode in multimodal evaluation. We introduce a controlled contrastive benchmark \textsc{\textbf{ProtoBias}} (\textit{\textbf{Proto}typical \textbf{Bias}}), spanning Animals, Objects, and Demography images, where semantically correct but non-prototypical images are paired with subtly incorrect yet prototypical adversarial counterparts. This setup enables a directional evaluation of whether metrics follow textual semantics or default to prototypes. Our results show that widely used metrics, including CLIPScore, PickScore, and VQA-based scores, frequently misrank these pairs, while even LLM-as-Judge systems exhibit uneven robustness in socially grounded cases. Human evaluations consistently favour semantic correctness with larger decision margins. Motivated by these findings, we propose \textbf{\textsc{ProtoScore}}, a robust 7B-parameter metric that substantially reduces failure rates and suppresses misranking, while running at orders of magnitude faster than the inference time of GPT-5, approaching the robustness of much larger closed-source judges.
Leveraging Vision-Language Pre-training for Human Activity Recognition in Still Images
Jun 16, 2025



Recognising human activity in a single photo enables indexing, safety and assistive applications, yet lacks motion cues. Using 285 MSCOCO images labelled as walking, running, sitting, and standing, scratch CNNs scored 41% accuracy. Fine-tuning multimodal CLIP raised this to 76%, demonstrating that contrastive vision-language pre-training decisively improves still-image action recognition in real-world deployments.
Date Fragments: A Hidden Bottleneck of Tokenization for Temporal Reasoning
May 22, 2025


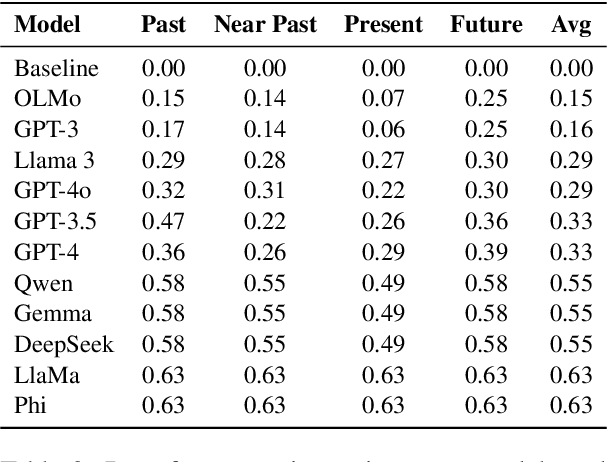
Modern BPE tokenizers often split calendar dates into meaningless fragments, e.g., 20250312 $\rightarrow$ 202, 503, 12, inflating token counts and obscuring the inherent structure needed for robust temporal reasoning. In this work, we (1) introduce a simple yet interpretable metric, termed date fragmentation ratio, that measures how faithfully a tokenizer preserves multi-digit date components; (2) release DateAugBench, a suite of 6500 examples spanning three temporal reasoning tasks: context-based date resolution, format-invariance puzzles, and date arithmetic across historical, contemporary, and future regimes; and (3) through layer-wise probing and causal attention-hop analyses, uncover an emergent date-abstraction mechanism whereby large language models stitch together the fragments of month, day, and year components for temporal reasoning. Our experiments show that excessive fragmentation correlates with accuracy drops of up to 10 points on uncommon dates like historical and futuristic dates. Further, we find that the larger the model, the faster the emergent date abstraction that heals date fragments is accomplished. Lastly, we observe a reasoning path that LLMs follow to assemble date fragments, typically differing from human interpretation (year $\rightarrow$ month $\rightarrow$ day).
DateLogicQA: Benchmarking Temporal Biases in Large Language Models
Dec 17, 2024



This paper introduces DateLogicQA, a benchmark with 190 questions covering diverse date formats, temporal contexts, and reasoning types. We propose the Semantic Integrity Metric to assess tokenization quality and analyse two biases: Representation-Level Bias, affecting embeddings, and Logical-Level Bias, influencing reasoning outputs. Our findings provide a comprehensive evaluation of LLMs' capabilities and limitations in temporal reasoning, highlighting key challenges in handling temporal data accurately. The GitHub repository for our work is available at https://github.com/gagan3012/EAIS-Temporal-Bias
Swan and ArabicMTEB: Dialect-Aware, Arabic-Centric, Cross-Lingual, and Cross-Cultural Embedding Models and Benchmarks
Nov 02, 2024We introduce Swan, a family of embedding models centred around the Arabic language, addressing both small-scale and large-scale use cases. Swan includes two variants: Swan-Small, based on ARBERTv2, and Swan-Large, built on ArMistral, a pretrained Arabic large language model. To evaluate these models, we propose ArabicMTEB, a comprehensive benchmark suite that assesses cross-lingual, multi-dialectal, multi-domain, and multi-cultural Arabic text embedding performance, covering eight diverse tasks and spanning 94 datasets. Swan-Large achieves state-of-the-art results, outperforming Multilingual-E5-large in most Arabic tasks, while the Swan-Small consistently surpasses Multilingual-E5 base. Our extensive evaluations demonstrate that Swan models are both dialectally and culturally aware, excelling across various Arabic domains while offering significant monetary efficiency. This work significantly advances the field of Arabic language modelling and provides valuable resources for future research and applications in Arabic natural language processing. Our models and benchmark will be made publicly accessible for research.
Dallah: A Dialect-Aware Multimodal Large Language Model for Arabic
Jul 26, 2024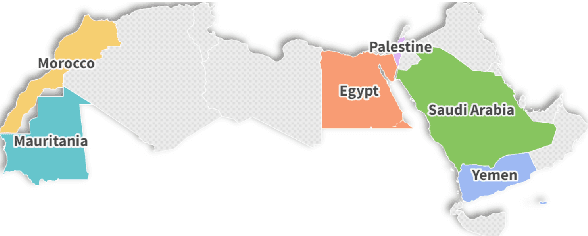
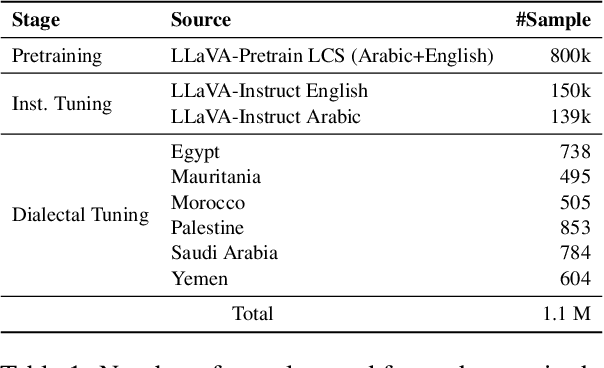
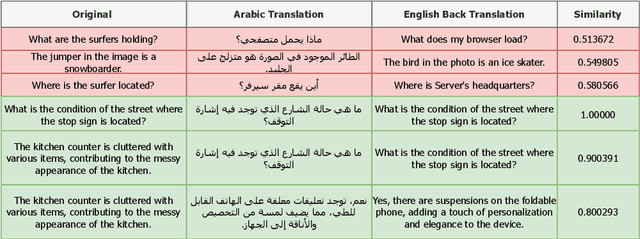
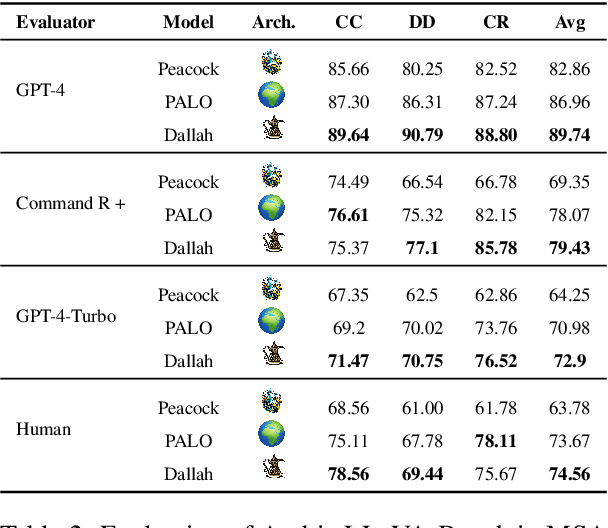
Recent advancements have significantly enhanced the capabilities of Multimodal Large Language Models (MLLMs) in generating and understanding image-to-text content. Despite these successes, progress is predominantly limited to English due to the scarcity of high quality multimodal resources in other languages. This limitation impedes the development of competitive models in languages such as Arabic. To alleviate this situation, we introduce an efficient Arabic multimodal assistant, dubbed Dallah, that utilizes an advanced language model based on LLaMA-2 to facilitate multimodal interactions. Dallah demonstrates state-of-the-art performance in Arabic MLLMs. Through fine-tuning six Arabic dialects, Dallah showcases its capability to handle complex dialectal interactions incorporating both textual and visual elements. The model excels in two benchmark tests: one evaluating its performance on Modern Standard Arabic (MSA) and another specifically designed to assess dialectal responses. Beyond its robust performance in multimodal interaction tasks, Dallah has the potential to pave the way for further development of dialect-aware Arabic MLLMs.
Qalam : A Multimodal LLM for Arabic Optical Character and Handwriting Recognition
Jul 18, 2024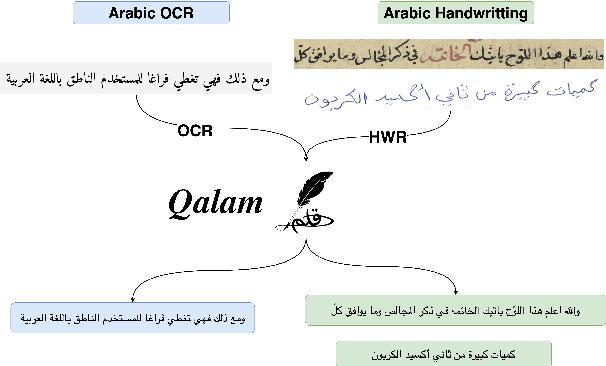
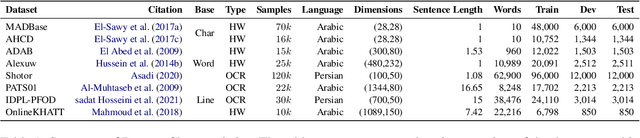
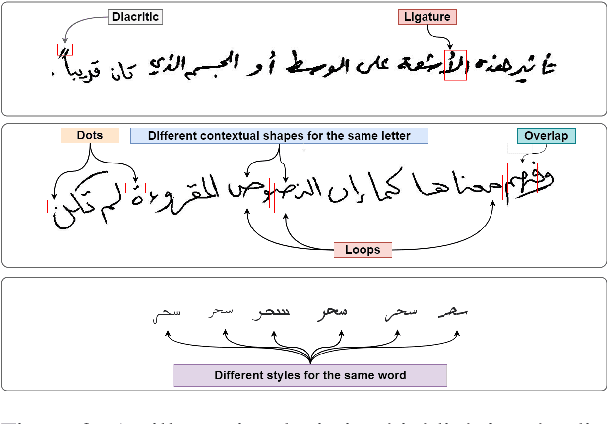
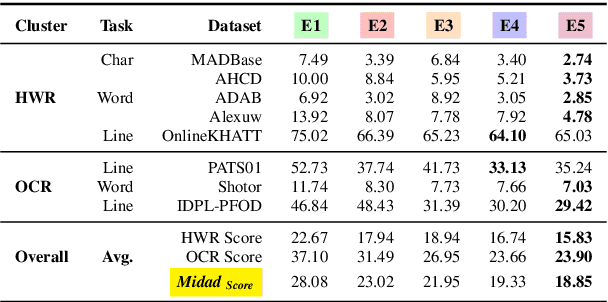
Arabic Optical Character Recognition (OCR) and Handwriting Recognition (HWR) pose unique challenges due to the cursive and context-sensitive nature of the Arabic script. This study introduces Qalam, a novel foundation model designed for Arabic OCR and HWR, built on a SwinV2 encoder and RoBERTa decoder architecture. Our model significantly outperforms existing methods, achieving a Word Error Rate (WER) of just 0.80% in HWR tasks and 1.18% in OCR tasks. We train Qalam on a diverse dataset, including over 4.5 million images from Arabic manuscripts and a synthetic dataset comprising 60k image-text pairs. Notably, Qalam demonstrates exceptional handling of Arabic diacritics, a critical feature in Arabic scripts. Furthermore, it shows a remarkable ability to process high-resolution inputs, addressing a common limitation in current OCR systems. These advancements underscore Qalam's potential as a leading solution for Arabic script recognition, offering a significant leap in accuracy and efficiency.
Peacock: A Family of Arabic Multimodal Large Language Models and Benchmarks
Mar 01, 2024



Multimodal large language models (MLLMs) have proven effective in a wide range of tasks requiring complex reasoning and linguistic comprehension. However, due to a lack of high-quality multimodal resources in languages other than English, success of MLLMs remains relatively limited to English-based settings. This poses significant challenges in developing comparable models for other languages, including even those with large speaker populations such as Arabic. To alleviate this challenge, we introduce a comprehensive family of Arabic MLLMs, dubbed \textit{Peacock}, with strong vision and language capabilities. Through comprehensive qualitative and quantitative analysis, we demonstrate the solid performance of our models on various visual reasoning tasks and further show their emerging dialectal potential. Additionally, we introduce ~\textit{Henna}, a new benchmark specifically designed for assessing MLLMs on aspects related to Arabic culture, setting the first stone for culturally-aware Arabic MLLMs.The GitHub repository for the \textit{Peacock} project is available at \url{https://github.com/UBC-NLP/peacock}.
FinTral: A Family of GPT-4 Level Multimodal Financial Large Language Models
Feb 16, 2024



We introduce FinTral, a suite of state-of-the-art multimodal large language models (LLMs) built upon the Mistral-7b model and tailored for financial analysis. FinTral integrates textual, numerical, tabular, and image data. We enhance FinTral with domain-specific pretraining, instruction fine-tuning, and RLAIF training by exploiting a large collection of textual and visual datasets we curate for this work. We also introduce an extensive benchmark featuring nine tasks and 25 datasets for evaluation, including hallucinations in the financial domain. Our FinTral model trained with direct preference optimization employing advanced Tools and Retrieval methods, dubbed FinTral-DPO-T&R, demonstrates an exceptional zero-shot performance. It outperforms ChatGPT-3.5 in all tasks and surpasses GPT-4 in five out of nine tasks, marking a significant advancement in AI-driven financial technology. We also demonstrate that FinTral has the potential to excel in real-time analysis and decision-making in diverse financial contexts.