 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDallah: A Dialect-Aware Multimodal Large Language Model for Arabic
Paper and Code
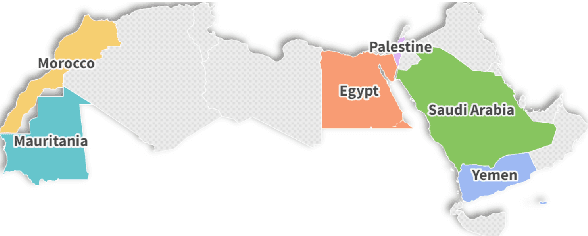
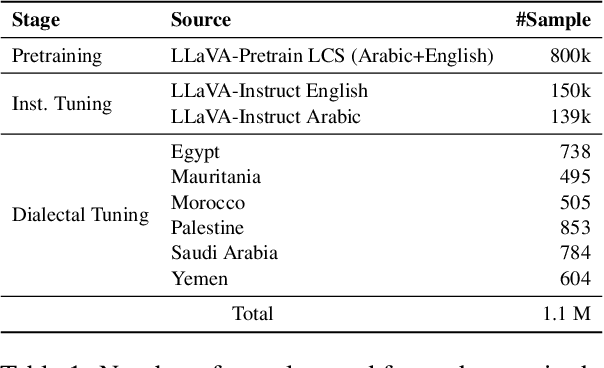
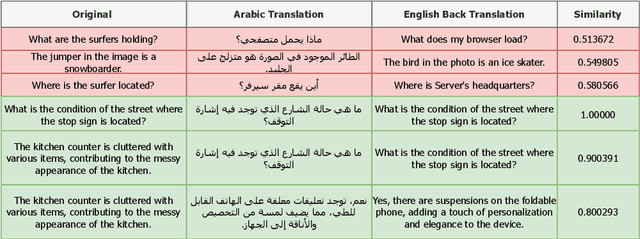
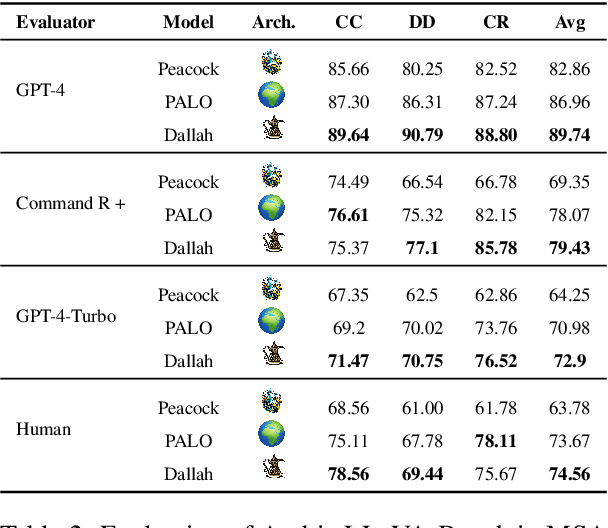
Recent advancements have significantly enhanced the capabilities of Multimodal Large Language Models (MLLMs) in generating and understanding image-to-text content. Despite these successes, progress is predominantly limited to English due to the scarcity of high quality multimodal resources in other languages. This limitation impedes the development of competitive models in languages such as Arabic. To alleviate this situation, we introduce an efficient Arabic multimodal assistant, dubbed Dallah, that utilizes an advanced language model based on LLaMA-2 to facilitate multimodal interactions. Dallah demonstrates state-of-the-art performance in Arabic MLLMs. Through fine-tuning six Arabic dialects, Dallah showcases its capability to handle complex dialectal interactions incorporating both textual and visual elements. The model excels in two benchmark tests: one evaluating its performance on Modern Standard Arabic (MSA) and another specifically designed to assess dialectal responses. Beyond its robust performance in multimodal interaction tasks, Dallah has the potential to pave the way for further development of dialect-aware Arabic MLLMs.