 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAfroScope: A Framework for Studying the Linguistic Landscape of Africa
Jan 19, 2026Language Identification (LID) is the task of determining the language of a given text and is a fundamental preprocessing step that affects the reliability of downstream NLP applications. While recent work has expanded LID coverage for African languages, existing approaches remain limited in (i) the number of supported languages and (ii) their ability to make fine-grained distinctions among closely related varieties. We introduce AfroScope, a unified framework for African LID that includes AfroScope-Data, a dataset covering 713 African languages, and AfroScope-Models, a suite of strong LID models with broad language coverage. To better distinguish highly confusable languages, we propose a hierarchical classification approach that leverages Mirror-Serengeti, a specialized embedding model targeting 29 closely related or geographically proximate languages. This approach improves macro F1 by 4.55 on this confusable subset compared to our best base model. Finally, we analyze cross linguistic transfer and domain effects, offering guidance for building robust African LID systems. We position African LID as an enabling technology for large scale measurement of Africas linguistic landscape in digital text and release AfroScope-Data and AfroScope-Models publicly.
Voice of a Continent: Mapping Africa's Speech Technology Frontier
May 24, 2025Africa's rich linguistic diversity remains significantly underrepresented in speech technologies, creating barriers to digital inclusion. To alleviate this challenge, we systematically map the continent's speech space of datasets and technologies, leading to a new comprehensive benchmark SimbaBench for downstream African speech tasks. Using SimbaBench, we introduce the Simba family of models, achieving state-of-the-art performance across multiple African languages and speech tasks. Our benchmark analysis reveals critical patterns in resource availability, while our model evaluation demonstrates how dataset quality, domain diversity, and language family relationships influence performance across languages. Our work highlights the need for expanded speech technology resources that better reflect Africa's linguistic diversity and provides a solid foundation for future research and development efforts toward more inclusive speech technologies.
Gazelle: An Instruction Dataset for Arabic Writing Assistance
Oct 23, 2024



Writing has long been considered a hallmark of human intelligence and remains a pinnacle task for artificial intelligence (AI) due to the intricate cognitive processes involved. Recently, rapid advancements in generative AI, particularly through the development of Large Language Models (LLMs), have significantly transformed the landscape of writing assistance. However, underrepresented languages like Arabic encounter significant challenges in the development of advanced AI writing tools, largely due to the limited availability of data. This scarcity constrains the training of effective models, impeding the creation of sophisticated writing assistance technologies. To address these issues, we present Gazelle, a comprehensive dataset for Arabic writing assistance. In addition, we offer an evaluation framework designed to enhance Arabic writing assistance tools. Our human evaluation of leading LLMs, including GPT-4, GPT-4o, Cohere Command R+, and Gemini 1.5 Pro, highlights their respective strengths and limitations in addressing the challenges of Arabic writing. Our findings underscore the need for continuous model training and dataset enrichment to manage the complexities of Arabic language processing, paving the way for more effective AI-powered Arabic writing tools.
Beyond English: Evaluating LLMs for Arabic Grammatical Error Correction
Dec 13, 2023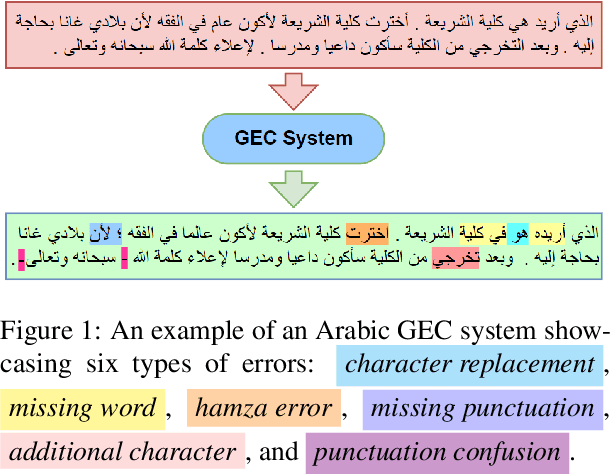
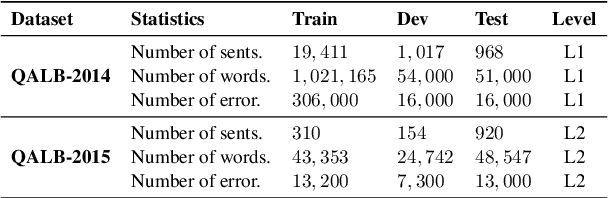
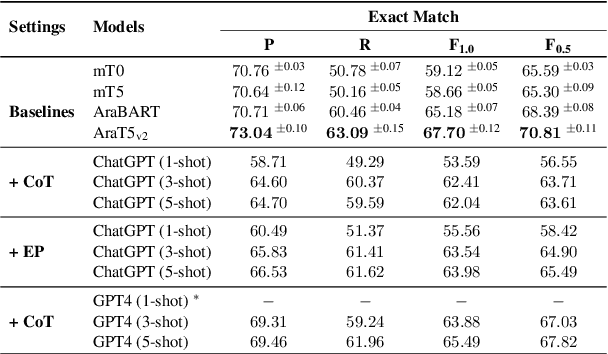

Large language models (LLMs) finetuned to follow human instruction have recently exhibited significant capabilities in various English NLP tasks. However, their performance in grammatical error correction (GEC), especially on languages other than English, remains significantly unexplored. In this work, we evaluate the abilities of instruction finetuned LLMs in Arabic GEC, a complex task due to Arabic's rich morphology. Our findings suggest that various prompting methods, coupled with (in-context) few-shot learning, demonstrate considerable effectiveness, with GPT-4 achieving up to $65.49$ F$_{1}$ score under expert prompting (approximately $5$ points higher than our established baseline). Despite these positive results, we find that instruction finetuned models, regardless of their size, are still outperformed by fully finetuned ones, even if they are significantly smaller in size. This disparity highlights substantial room for improvements for LLMs. Inspired by methods used in low-resource machine translation, we also develop a method exploiting synthetic data that significantly outperforms previous models on two standard Arabic benchmarks. Our best model achieves a new SOTA on Arabic GEC, with $73.29$ and $73.26$ F$_{1}$ on the 2014 and 2015 QALB datasets, respectively, compared to peer-reviewed published baselines.
ChatGPT for Arabic Grammatical Error Correction
Aug 08, 2023



Recently, large language models (LLMs) fine-tuned to follow human instruction have exhibited significant capabilities in various English NLP tasks. However, their performance in grammatical error correction (GEC) tasks, particularly in non-English languages, remains significantly unexplored. In this paper, we delve into abilities of instruction fine-tuned LLMs in Arabic GEC, a task made complex due to Arabic's rich morphology. Our findings suggest that various prompting methods, coupled with (in-context) few-shot learning, demonstrate considerable effectiveness, with GPT-4 achieving up to $65.49$ F\textsubscript{1} score under expert prompting (approximately $5$ points higher than our established baseline). This highlights the potential of LLMs in low-resource settings, offering a viable approach for generating useful synthetic data for model training. Despite these positive results, we find that instruction fine-tuned models, regardless of their size, significantly underperform compared to fully fine-tuned models of significantly smaller sizes. This disparity highlights a substantial room for improvements for LLMs. Inspired by methods from low-resource machine translation, we also develop a method exploiting synthetic data that significantly outperforms previous models on two standard Arabic benchmarks. Our work sets new SoTA for Arabic GEC, with $72.19\%$ and $73.26$ F$_{1}$ on the 2014 and 2015 QALB datasets, respectively.
Zero-Shot Slot and Intent Detection in Low-Resource Languages
Apr 26, 2023Intent detection and slot filling are critical tasks in spoken and natural language understanding for task-oriented dialog systems. In this work we describe our participation in the slot and intent detection for low-resource language varieties (SID4LR; Aepli et al. (2023)). We investigate the slot and intent detection (SID) tasks using a wide range of models and settings. Given the recent success of multitask-prompted finetuning of large language models, we also test the generalization capability of the recent encoder-decoder model mT0 (Muennighoff et al., 2022) on new tasks (i.e., SID) in languages they have never intentionally seen. We show that our best model outperforms the baseline by a large margin (up to +30 F1 points) in both SID tasks