 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePearl: A Multimodal Culturally-Aware Arabic Instruction Dataset
May 28, 2025Mainstream large vision-language models (LVLMs) inherently encode cultural biases, highlighting the need for diverse multimodal datasets. To address this gap, we introduce Pearl, a large-scale Arabic multimodal dataset and benchmark explicitly designed for cultural understanding. Constructed through advanced agentic workflows and extensive human-in-the-loop annotations by 45 annotators from across the Arab world, Pearl comprises over K multimodal examples spanning ten culturally significant domains covering all Arab countries. We further provide two robust evaluation benchmarks Pearl and Pearl-Lite along with a specialized subset Pearl-X explicitly developed to assess nuanced cultural variations. Comprehensive evaluations on state-of-the-art open and proprietary LVLMs demonstrate that reasoning-centric instruction alignment substantially improves models' cultural grounding compared to conventional scaling methods. Pearl establishes a foundational resource for advancing culturally-informed multimodal modeling research. All datasets and benchmarks are publicly available.
Enhancing Health Mention Classification Performance: A Study on Advancements in Parameter Efficient Tuning
Apr 30, 2025Health Mention Classification (HMC) plays a critical role in leveraging social media posts for real-time tracking and public health monitoring. Nevertheless, the process of HMC presents significant challenges due to its intricate nature, primarily stemming from the contextual aspects of health mentions, such as figurative language and descriptive terminology, rather than explicitly reflecting a personal ailment. To address this problem, we argue that clearer mentions can be achieved through conventional fine-tuning with enhanced parameters of biomedical natural language methods (NLP). In this study, we explore different techniques such as the utilisation of part-of-speech (POS) tagger information, improving on PEFT techniques, and different combinations thereof. Extensive experiments are conducted on three widely used datasets: RHDM, PHM, and Illness. The results incorporated POS tagger information, and leveraging PEFT techniques significantly improves performance in terms of F1-score compared to state-of-the-art methods across all three datasets by utilising smaller models and efficient training. Furthermore, the findings highlight the effectiveness of incorporating POS tagger information and leveraging PEFT techniques for HMC. In conclusion, the proposed methodology presents a potentially effective approach to accurately classifying health mentions in social media posts while optimising the model size and training efficiency.
Gazelle: An Instruction Dataset for Arabic Writing Assistance
Oct 23, 2024



Writing has long been considered a hallmark of human intelligence and remains a pinnacle task for artificial intelligence (AI) due to the intricate cognitive processes involved. Recently, rapid advancements in generative AI, particularly through the development of Large Language Models (LLMs), have significantly transformed the landscape of writing assistance. However, underrepresented languages like Arabic encounter significant challenges in the development of advanced AI writing tools, largely due to the limited availability of data. This scarcity constrains the training of effective models, impeding the creation of sophisticated writing assistance technologies. To address these issues, we present Gazelle, a comprehensive dataset for Arabic writing assistance. In addition, we offer an evaluation framework designed to enhance Arabic writing assistance tools. Our human evaluation of leading LLMs, including GPT-4, GPT-4o, Cohere Command R+, and Gemini 1.5 Pro, highlights their respective strengths and limitations in addressing the challenges of Arabic writing. Our findings underscore the need for continuous model training and dataset enrichment to manage the complexities of Arabic language processing, paving the way for more effective AI-powered Arabic writing tools.
PubTrend: General Overview of Artificial Intelligence for Colorectal cancer diagnosis from 2010-2022
Jul 06, 2024


Colorectal cancer (CRC) is among the most prevalent cancers in the world. Due to numerous scholarly papers and broad enquiries about specific use cases for artificial intelligence (AI) in colorectal cancer, researchers find it challenging to explore relevant papers on the current knowledge, comprehensive knowledge, and past methodologies in the literature review. This review extracts recent AI technology advances for diagnosing colorectal cancer from January 2010 to March 2022. PubTrends was used to identify and automate the intellectual structure and comparable papers on the use of AI in colorectal cancer diagnosis using the most cited papers, keywords, and similar papers. Papers with quantitative results were represented with a tabular summary, and other paper contributions were in a sentence summary. Twenty-four (24) out of the forty-nine (49) top-cited papers were quantitative results, with one (1) outlier about lung cancer comprehensive screening. The most frequently used words were: "polyps," "detected", "image," and "colonoscopy." In addition, 83 per cent of the terms frequently used shortly before 2022 were image, polyps, detected, colonoscopy, and learning. In addition, 16 per cent are preparation, variant, classification, sample, and surgery. The review showcases 49 of the 50 most cited papers, their notable contributions, objectives, specific AI methods, results, conclusions, and further recommendations. These papers highlight the limitations of colonoscopy for therapeutic use. The review concluded that despite the enormous benefits of using artificial intelligence, from improving diagnosis, the medical AI programmer still needs to be actively involved in the diagnosis team for effective results in CRC diagnosis.
Improved Breast Cancer Diagnosis through Transfer Learning on Hematoxylin and Eosin Stained Histology Images
Sep 15, 2023

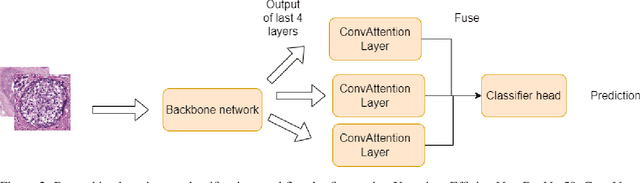

Breast cancer is one of the leading causes of death for women worldwide. Early screening is essential for early identification, but the chance of survival declines as the cancer progresses into advanced stages. For this study, the most recent BRACS dataset of histological (H\&E) stained images was used to classify breast cancer tumours, which contains both the whole-slide images (WSI) and region-of-interest (ROI) images, however, for our study we have considered ROI images. We have experimented using different pre-trained deep learning models, such as Xception, EfficientNet, ResNet50, and InceptionResNet, pre-trained on the ImageNet weights. We pre-processed the BRACS ROI along with image augmentation, upsampling, and dataset split strategies. For the default dataset split, the best results were obtained by ResNet50 achieving 66\% f1-score. For the custom dataset split, the best results were obtained by performing upsampling and image augmentation which results in 96.2\% f1-score. Our second approach also reduced the number of false positive and false negative classifications to less than 3\% for each class. We believe that our study significantly impacts the early diagnosis and identification of breast cancer tumors and their subtypes, especially atypical and malignant tumors, thus improving patient outcomes and reducing patient mortality rates. Overall, this study has primarily focused on identifying seven (7) breast cancer tumor subtypes, and we believe that the experimental models can be fine-tuned further to generalize over previous breast cancer histology datasets as well.
Relating CNNs with brain: Challenges and findings
Aug 22, 2021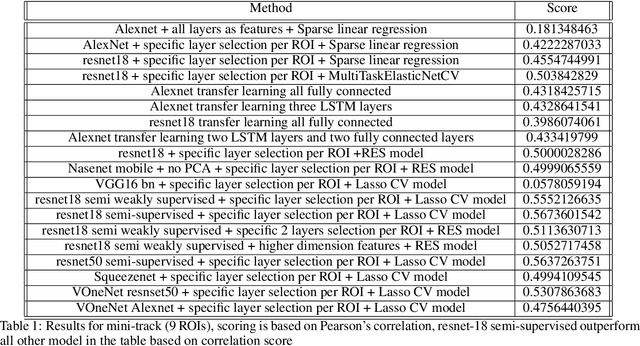

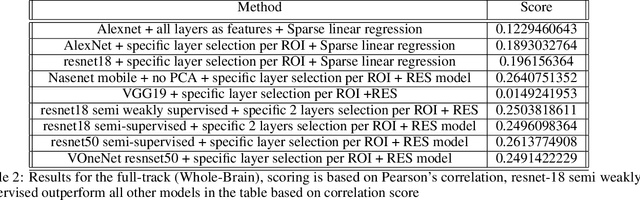

Conventional neural network models (CNN), loosely inspired by the primate visual system, have been shown to predict neural responses in the visual cortex. However, the relationship between CNNs and the visual system is incomplete due to many reasons. On one hand state of the art CNN architecture is very complex, yet can be fooled by imperceptibly small, explicitly crafted perturbations which makes it hard difficult to map layers of the network with the visual system and to understand what they are doing. On the other hand, we don't know the exact mapping between feature space of the CNNs and the space domain of the visual cortex, which makes it hard to accurately predict neural responses. In this paper we review the challenges and the methods that have been used to predict neural responses in the visual cortex and whole brain as part of The Algonauts Project 2021 Challenge: "How the Human Brain Makes Sense of a World in Motion".
Human Activity Recognition using Wearable Sensors: Review, Challenges, Evaluation Benchmark
Jan 06, 2021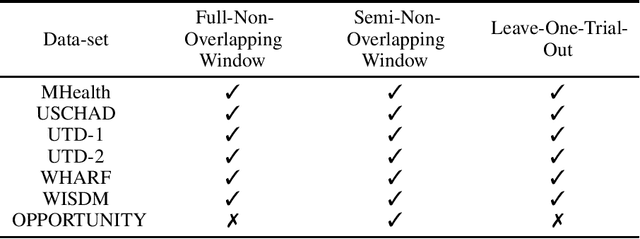
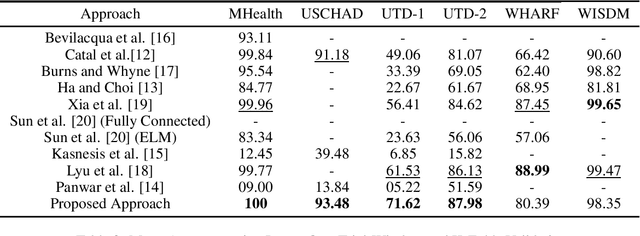
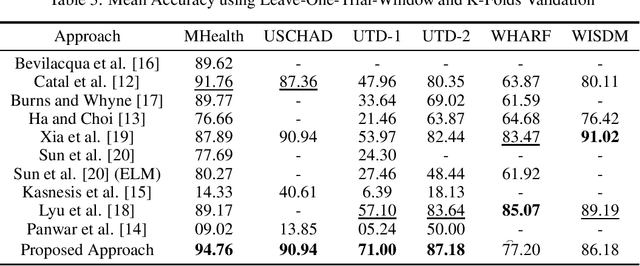
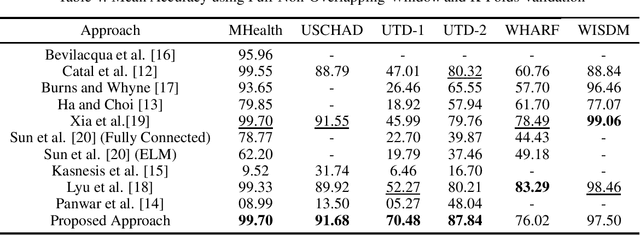
Recognizing human activity plays a significant role in the advancements of human-interaction applications in healthcare, personal fitness, and smart devices. Many papers presented various techniques for human activity representation that resulted in distinguishable progress. In this study, we conduct an extensive literature review on recent, top-performing techniques in human activity recognition based on wearable sensors. Due to the lack of standardized evaluation and to assess and ensure a fair comparison between the state-of-the-art techniques, we applied a standardized evaluation benchmark on the state-of-the-art techniques using six publicly available data-sets: MHealth, USCHAD, UTD-MHAD, WISDM, WHARF, and OPPORTUNITY. Also, we propose an experimental, improved approach that is a hybrid of enhanced handcrafted features and a neural network architecture which outperformed top-performing techniques with the same standardized evaluation benchmark applied concerning MHealth, USCHAD, UTD-MHAD data-sets.