 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLQM: Linguistically Motivated Multidimensional Quality Metrics for Machine Translation
Apr 20, 2026Existing MT evaluation frameworks, including automatic metrics and human evaluation schemes such as Multidimensional Quality Metrics (MQM), are largely language-agnostic. However, they often fail to capture dialect- and culture-specific errors in diglossic languages (e.g., Arabic), where translation failures stem from mismatches in language variety, content coverage, and pragmatic appropriateness rather than surface form alone.We introduce LQM: Linguistically Motivated Multidimensional Quality Metrics for MT. LQM is a hierarchical error taxonomy for diagnosing MT errors through six linguistically grounded levels: sociolinguistics, pragmatics, semantics, morphosyntax, orthography, and graphetics (Figure 1). We construct a bidirectional parallel corpus of 3,850 sentences (550 per variety) spanning seven Arabic dialects (Egyptian, Emirati, Jordanian, Mauritanian, Moroccan, Palestinian, and Yemeni), derived from conversational, culturally rich content. We evaluate six LLMs in a zero-shot setting and conduct expert span-level human annotation using LQM, producing 6,113 labeled error spans across 3,495 unique erroneous sentences, along with severity-weighted quality scores. We complement this analysis with an automatic metric (spBLEU). Though validated here on Arabic, LQM is a language-agnostic framework designed to be easily applied to or adapted for other languages. LQM annotated errors data, prompts, and annotation guidelines are publicly available at https://github.com/UBC-NLP/LQM_MT.
Alexandria: A Multi-Domain Dialectal Arabic Machine Translation Dataset for Culturally Inclusive and Linguistically Diverse LLMs
Jan 19, 2026Arabic is a highly diglossic language where most daily communication occurs in regional dialects rather than Modern Standard Arabic. Despite this, machine translation (MT) systems often generalize poorly to dialectal input, limiting their utility for millions of speakers. We introduce \textbf{Alexandria}, a large-scale, community-driven, human-translated dataset designed to bridge this gap. Alexandria covers 13 Arab countries and 11 high-impact domains, including health, education, and agriculture. Unlike previous resources, Alexandria provides unprecedented granularity by associating contributions with city-of-origin metadata, capturing authentic local varieties beyond coarse regional labels. The dataset consists of multi-turn conversational scenarios annotated with speaker-addressee gender configurations, enabling the study of gender-conditioned variation in dialectal use. Comprising 107K total samples, Alexandria serves as both a training resource and a rigorous benchmark for evaluating MT and Large Language Models (LLMs). Our automatic and human evaluation of Arabic-aware LLMs benchmarks current capabilities in translating across diverse Arabic dialects and sub-dialects, while exposing significant persistent challenges.
Pearl: A Multimodal Culturally-Aware Arabic Instruction Dataset
May 28, 2025Mainstream large vision-language models (LVLMs) inherently encode cultural biases, highlighting the need for diverse multimodal datasets. To address this gap, we introduce Pearl, a large-scale Arabic multimodal dataset and benchmark explicitly designed for cultural understanding. Constructed through advanced agentic workflows and extensive human-in-the-loop annotations by 45 annotators from across the Arab world, Pearl comprises over K multimodal examples spanning ten culturally significant domains covering all Arab countries. We further provide two robust evaluation benchmarks Pearl and Pearl-Lite along with a specialized subset Pearl-X explicitly developed to assess nuanced cultural variations. Comprehensive evaluations on state-of-the-art open and proprietary LVLMs demonstrate that reasoning-centric instruction alignment substantially improves models' cultural grounding compared to conventional scaling methods. Pearl establishes a foundational resource for advancing culturally-informed multimodal modeling research. All datasets and benchmarks are publicly available.
NileChat: Towards Linguistically Diverse and Culturally Aware LLMs for Local Communities
May 23, 2025Enhancing the linguistic capabilities of Large Language Models (LLMs) to include low-resource languages is a critical research area. Current research directions predominantly rely on synthetic data generated by translating English corpora, which, while demonstrating promising linguistic understanding and translation abilities, often results in models aligned with source language culture. These models frequently fail to represent the cultural heritage and values of local communities. This work proposes a methodology to create both synthetic and retrieval-based pre-training data tailored to a specific community, considering its (i) language, (ii) cultural heritage, and (iii) cultural values. We demonstrate our methodology using Egyptian and Moroccan dialects as testbeds, chosen for their linguistic and cultural richness and current underrepresentation in LLMs. As a proof-of-concept, we develop NileChat, a 3B parameter LLM adapted for Egyptian and Moroccan communities, incorporating their language, cultural heritage, and values. Our results on various understanding, translation, and cultural and values alignment benchmarks show that NileChat outperforms existing Arabic-aware LLMs of similar size and performs on par with larger models. We share our methods, data, and models with the community to promote the inclusion and coverage of more diverse communities in LLM development.
Swan and ArabicMTEB: Dialect-Aware, Arabic-Centric, Cross-Lingual, and Cross-Cultural Embedding Models and Benchmarks
Nov 02, 2024



We introduce Swan, a family of embedding models centred around the Arabic language, addressing both small-scale and large-scale use cases. Swan includes two variants: Swan-Small, based on ARBERTv2, and Swan-Large, built on ArMistral, a pretrained Arabic large language model. To evaluate these models, we propose ArabicMTEB, a comprehensive benchmark suite that assesses cross-lingual, multi-dialectal, multi-domain, and multi-cultural Arabic text embedding performance, covering eight diverse tasks and spanning 94 datasets. Swan-Large achieves state-of-the-art results, outperforming Multilingual-E5-large in most Arabic tasks, while the Swan-Small consistently surpasses Multilingual-E5 base. Our extensive evaluations demonstrate that Swan models are both dialectally and culturally aware, excelling across various Arabic domains while offering significant monetary efficiency. This work significantly advances the field of Arabic language modelling and provides valuable resources for future research and applications in Arabic natural language processing. Our models and benchmark will be made publicly accessible for research.
Effective Self-Mining of In-Context Examples for Unsupervised Machine Translation with LLMs
Oct 14, 2024Large Language Models (LLMs) have demonstrated impressive performance on a wide range of natural language processing (NLP) tasks, primarily through in-context learning (ICL). In ICL, the LLM is provided with examples that represent a given task such that it learns to generate answers for test inputs. However, access to these in-context examples is not guaranteed especially for low-resource or massively multilingual tasks. In this work, we propose an unsupervised approach to mine in-context examples for machine translation (MT), enabling unsupervised MT (UMT) across different languages. Our approach begins with word-level mining to acquire word translations that are then used to perform sentence-level mining. As the quality of mined parallel pairs may not be optimal due to noise or mistakes, we introduce a filtering criterion to select the optimal in-context examples from a pool of unsupervised parallel sentences. We evaluate our approach using two multilingual LLMs on 288 directions from the FLORES-200 dataset and analyze the impact of various linguistic features on performance. Our findings demonstrate the effectiveness of our unsupervised approach in mining in-context examples for MT, leading to better or comparable translation performance as translation with regular in-context samples (extracted from human-annotated data), while also outperforming the other state-of-the-art UMT methods by an average of $7$ BLEU points.
Casablanca: Data and Models for Multidialectal Arabic Speech Recognition
Oct 06, 2024



In spite of the recent progress in speech processing, the majority of world languages and dialects remain uncovered. This situation only furthers an already wide technological divide, thereby hindering technological and socioeconomic inclusion. This challenge is largely due to the absence of datasets that can empower diverse speech systems. In this paper, we seek to mitigate this obstacle for a number of Arabic dialects by presenting Casablanca, a large-scale community-driven effort to collect and transcribe a multi-dialectal Arabic dataset. The dataset covers eight dialects: Algerian, Egyptian, Emirati, Jordanian, Mauritanian, Moroccan, Palestinian, and Yemeni, and includes annotations for transcription, gender, dialect, and code-switching. We also develop a number of strong baselines exploiting Casablanca. The project page for Casablanca is accessible at: www.dlnlp.ai/speech/casablanca.
ProMap: Effective Bilingual Lexicon Induction via Language Model Prompting
Oct 28, 2023Bilingual Lexicon Induction (BLI), where words are translated between two languages, is an important NLP task. While noticeable progress on BLI in rich resource languages using static word embeddings has been achieved. The word translation performance can be further improved by incorporating information from contextualized word embeddings. In this paper, we introduce ProMap, a novel approach for BLI that leverages the power of prompting pretrained multilingual and multidialectal language models to address these challenges. To overcome the employment of subword tokens in these models, ProMap relies on an effective padded prompting of language models with a seed dictionary that achieves good performance when used independently. We also demonstrate the effectiveness of ProMap in re-ranking results from other BLI methods such as with aligned static word embeddings. When evaluated on both rich-resource and low-resource languages, ProMap consistently achieves state-of-the-art results. Furthermore, ProMap enables strong performance in few-shot scenarios (even with less than 10 training examples), making it a valuable tool for low-resource language translation. Overall, we believe our method offers both exciting and promising direction for BLI in general and low-resource languages in particular. ProMap code and data are available at \url{https://github.com/4mekki4/promap}.
CS-UM6P at SemEval-2022 Task 6: Transformer-based Models for Intended Sarcasm Detection in English and Arabic
Jun 16, 2022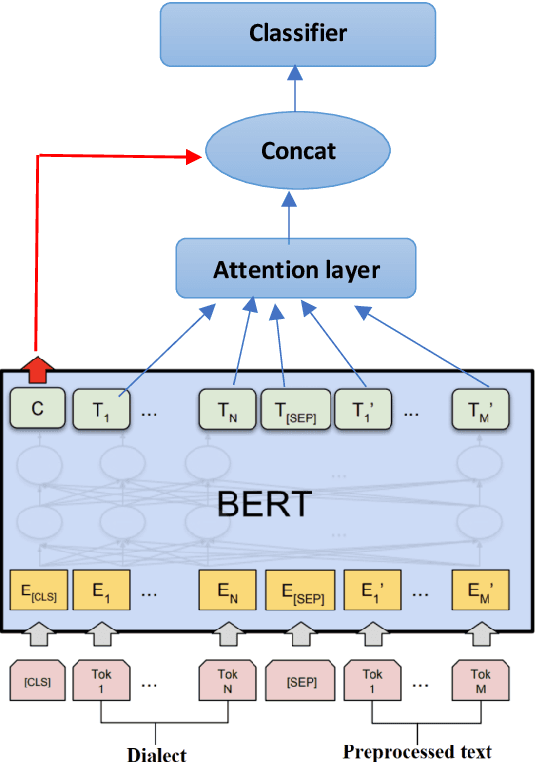
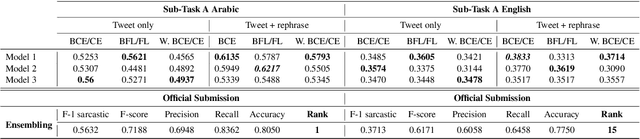

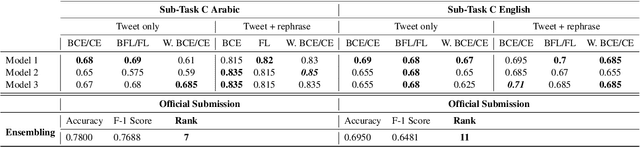
Sarcasm is a form of figurative language where the intended meaning of a sentence differs from its literal meaning. This poses a serious challenge to several Natural Language Processing (NLP) applications such as Sentiment Analysis, Opinion Mining, and Author Profiling. In this paper, we present our participating system to the intended sarcasm detection task in English and Arabic languages. Our system\footnote{The source code of our system is available at \url{https://github.com/AbdelkaderMH/iSarcasmEval}} consists of three deep learning-based models leveraging two existing pre-trained language models for Arabic and English. We have participated in all sub-tasks. Our official submissions achieve the best performance on sub-task A for Arabic language and rank second in sub-task B. For sub-task C, our system is ranked 7th and 11th on Arabic and English datasets, respectively.
Deep Multi-Task Models for Misogyny Identification and Categorization on Arabic Social Media
Jun 16, 2022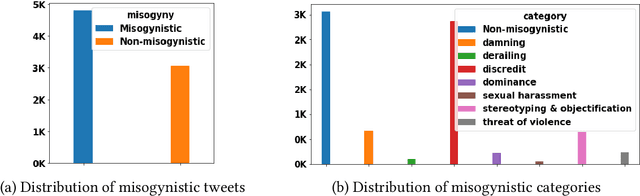
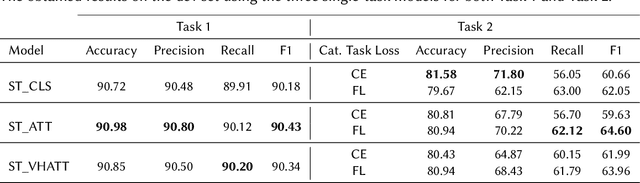
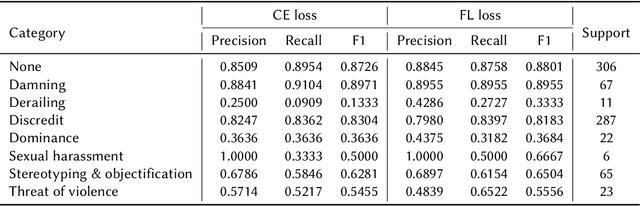
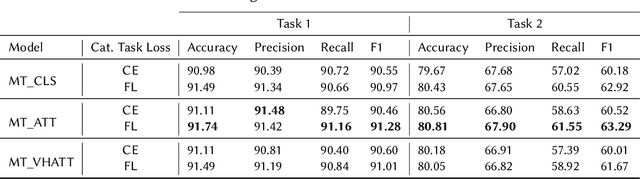
The prevalence of toxic content on social media platforms, such as hate speech, offensive language, and misogyny, presents serious challenges to our interconnected society. These challenging issues have attracted widespread attention in Natural Language Processing (NLP) community. In this paper, we present the submitted systems to the first Arabic Misogyny Identification shared task. We investigate three multi-task learning models as well as their single-task counterparts. In order to encode the input text, our models rely on the pre-trained MARBERT language model. The overall obtained results show that all our submitted models have achieved the best performances (top three ranked submissions) in both misogyny identification and categorization tasks.