 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProMap: Effective Bilingual Lexicon Induction via Language Model Prompting
Oct 28, 2023Bilingual Lexicon Induction (BLI), where words are translated between two languages, is an important NLP task. While noticeable progress on BLI in rich resource languages using static word embeddings has been achieved. The word translation performance can be further improved by incorporating information from contextualized word embeddings. In this paper, we introduce ProMap, a novel approach for BLI that leverages the power of prompting pretrained multilingual and multidialectal language models to address these challenges. To overcome the employment of subword tokens in these models, ProMap relies on an effective padded prompting of language models with a seed dictionary that achieves good performance when used independently. We also demonstrate the effectiveness of ProMap in re-ranking results from other BLI methods such as with aligned static word embeddings. When evaluated on both rich-resource and low-resource languages, ProMap consistently achieves state-of-the-art results. Furthermore, ProMap enables strong performance in few-shot scenarios (even with less than 10 training examples), making it a valuable tool for low-resource language translation. Overall, we believe our method offers both exciting and promising direction for BLI in general and low-resource languages in particular. ProMap code and data are available at \url{https://github.com/4mekki4/promap}.
UM6P-CS at SemEval-2022 Task 11: Enhancing Multilingual and Code-Mixed Complex Named Entity Recognition via Pseudo Labels using Multilingual Transformer
Apr 28, 2022
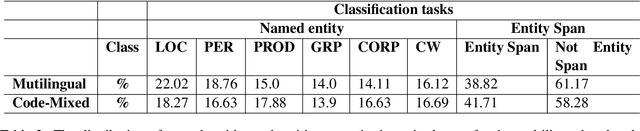

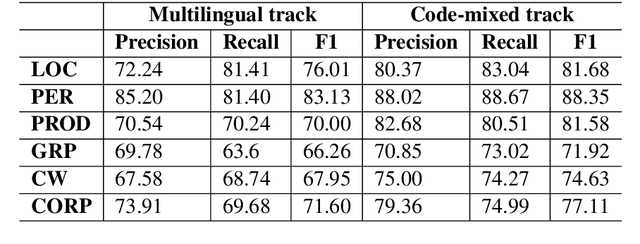
Building real-world complex Named Entity Recognition (NER) systems is a challenging task. This is due to the complexity and ambiguity of named entities that appear in various contexts such as short input sentences, emerging entities, and complex entities. Besides, real-world queries are mostly malformed, as they can be code-mixed or multilingual, among other scenarios. In this paper, we introduce our submitted system to the Multilingual Complex Named Entity Recognition (MultiCoNER) shared task. We approach the complex NER for multilingual and code-mixed queries, by relying on the contextualized representation provided by the multilingual Transformer XLM-RoBERTa. In addition to the CRF-based token classification layer, we incorporate a span classification loss to recognize named entities spans. Furthermore, we use a self-training mechanism to generate weakly-annotated data from a large unlabeled dataset. Our proposed system is ranked 6th and 8th in the multilingual and code-mixed MultiCoNER's tracks respectively.
BERT-based Multi-Task Model for Country and Province Level Modern Standard Arabic and Dialectal Arabic Identification
Jun 23, 2021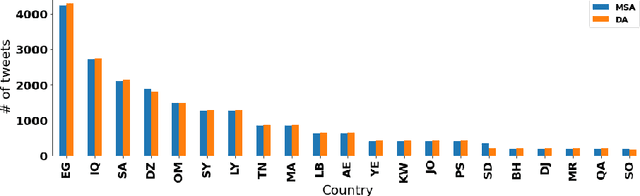

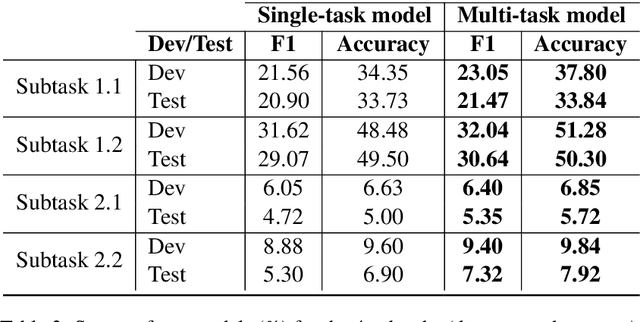
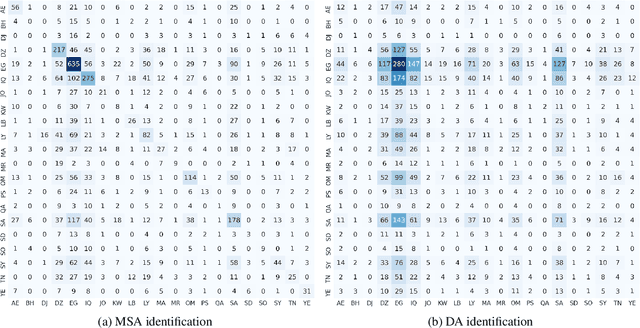
Dialect and standard language identification are crucial tasks for many Arabic natural language processing applications. In this paper, we present our deep learning-based system, submitted to the second NADI shared task for country-level and province-level identification of Modern Standard Arabic (MSA) and Dialectal Arabic (DA). The system is based on an end-to-end deep Multi-Task Learning (MTL) model to tackle both country-level and province-level MSA/DA identification. The latter MTL model consists of a shared Bidirectional Encoder Representation Transformers (BERT) encoder, two task-specific attention layers, and two classifiers. Our key idea is to leverage both the task-discriminative and the inter-task shared features for country and province MSA/DA identification. The obtained results show that our MTL model outperforms single-task models on most subtasks.
Deep Multi-Task Model for Sarcasm Detection and Sentiment Analysis in Arabic Language
Jun 23, 2021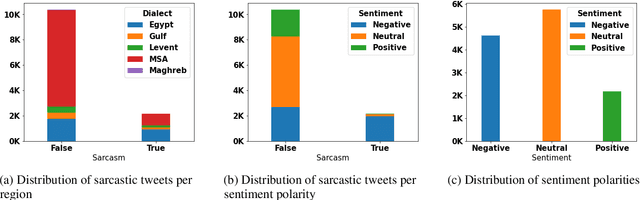



The prominence of figurative language devices, such as sarcasm and irony, poses serious challenges for Arabic Sentiment Analysis (SA). While previous research works tackle SA and sarcasm detection separately, this paper introduces an end-to-end deep Multi-Task Learning (MTL) model, allowing knowledge interaction between the two tasks. Our MTL model's architecture consists of a Bidirectional Encoder Representation from Transformers (BERT) model, a multi-task attention interaction module, and two task classifiers. The overall obtained results show that our proposed model outperforms its single-task counterparts on both SA and sarcasm detection sub-tasks.