 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUM6P-CS at SemEval-2022 Task 11: Enhancing Multilingual and Code-Mixed Complex Named Entity Recognition via Pseudo Labels using Multilingual Transformer
Apr 28, 2022
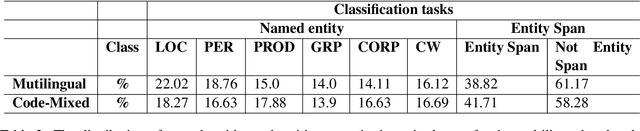

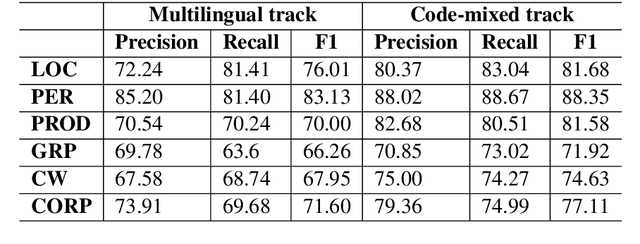
Building real-world complex Named Entity Recognition (NER) systems is a challenging task. This is due to the complexity and ambiguity of named entities that appear in various contexts such as short input sentences, emerging entities, and complex entities. Besides, real-world queries are mostly malformed, as they can be code-mixed or multilingual, among other scenarios. In this paper, we introduce our submitted system to the Multilingual Complex Named Entity Recognition (MultiCoNER) shared task. We approach the complex NER for multilingual and code-mixed queries, by relying on the contextualized representation provided by the multilingual Transformer XLM-RoBERTa. In addition to the CRF-based token classification layer, we incorporate a span classification loss to recognize named entities spans. Furthermore, we use a self-training mechanism to generate weakly-annotated data from a large unlabeled dataset. Our proposed system is ranked 6th and 8th in the multilingual and code-mixed MultiCoNER's tracks respectively.