 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlexandria: A Multi-Domain Dialectal Arabic Machine Translation Dataset for Culturally Inclusive and Linguistically Diverse LLMs
Jan 19, 2026Arabic is a highly diglossic language where most daily communication occurs in regional dialects rather than Modern Standard Arabic. Despite this, machine translation (MT) systems often generalize poorly to dialectal input, limiting their utility for millions of speakers. We introduce \textbf{Alexandria}, a large-scale, community-driven, human-translated dataset designed to bridge this gap. Alexandria covers 13 Arab countries and 11 high-impact domains, including health, education, and agriculture. Unlike previous resources, Alexandria provides unprecedented granularity by associating contributions with city-of-origin metadata, capturing authentic local varieties beyond coarse regional labels. The dataset consists of multi-turn conversational scenarios annotated with speaker-addressee gender configurations, enabling the study of gender-conditioned variation in dialectal use. Comprising 107K total samples, Alexandria serves as both a training resource and a rigorous benchmark for evaluating MT and Large Language Models (LLMs). Our automatic and human evaluation of Arabic-aware LLMs benchmarks current capabilities in translating across diverse Arabic dialects and sub-dialects, while exposing significant persistent challenges.
Pearl: A Multimodal Culturally-Aware Arabic Instruction Dataset
May 28, 2025Mainstream large vision-language models (LVLMs) inherently encode cultural biases, highlighting the need for diverse multimodal datasets. To address this gap, we introduce Pearl, a large-scale Arabic multimodal dataset and benchmark explicitly designed for cultural understanding. Constructed through advanced agentic workflows and extensive human-in-the-loop annotations by 45 annotators from across the Arab world, Pearl comprises over K multimodal examples spanning ten culturally significant domains covering all Arab countries. We further provide two robust evaluation benchmarks Pearl and Pearl-Lite along with a specialized subset Pearl-X explicitly developed to assess nuanced cultural variations. Comprehensive evaluations on state-of-the-art open and proprietary LVLMs demonstrate that reasoning-centric instruction alignment substantially improves models' cultural grounding compared to conventional scaling methods. Pearl establishes a foundational resource for advancing culturally-informed multimodal modeling research. All datasets and benchmarks are publicly available.
KoopAGRU: A Koopman-based Anomaly Detection in Time-Series using Gated Recurrent Units
Jan 29, 2025



Anomaly detection in real-world time-series data is a challenging task due to the complex and nonlinear temporal dynamics involved. This paper introduces KoopAGRU, a new deep learning model designed to tackle this problem by combining Fast Fourier Transform (FFT), Deep Dynamic Mode Decomposition (DeepDMD), and Koopman theory. FFT allows KoopAGRU to decompose temporal data into time-variant and time-invariant components providing precise modeling of complex patterns. To better control these two components, KoopAGRU utilizes Gate Recurrent Unit (GRU) encoders to learn Koopman observables, enhancing the detection capability across multiple temporal scales. KoopAGRU is trained in a single process and offers fast inference times. Extensive tests on various benchmark datasets show that KoopAGRU outperforms other leading methods, achieving a new average F1-score of 90.88\% on the well-known anomalies detection task of times series datasets, and proves to be efficient and reliable in detecting anomalies in real-world scenarios.
Dialect2SQL: A Novel Text-to-SQL Dataset for Arabic Dialects with a Focus on Moroccan Darija
Jan 20, 2025



The task of converting natural language questions (NLQs) into executable SQL queries, known as text-to-SQL, has gained significant interest in recent years, as it enables non-technical users to interact with relational databases. Many benchmarks, such as SPIDER and WikiSQL, have contributed to the development of new models and the evaluation of their performance. In addition, other datasets, like SEDE and BIRD, have introduced more challenges and complexities to better map real-world scenarios. However, these datasets primarily focus on high-resource languages such as English and Chinese. In this work, we introduce Dialect2SQL, the first large-scale, cross-domain text-to-SQL dataset in an Arabic dialect. It consists of 9,428 NLQ-SQL pairs across 69 databases in various domains. Along with SQL-related challenges such as long schemas, dirty values, and complex queries, our dataset also incorporates the complexities of the Moroccan dialect, which is known for its diverse source languages, numerous borrowed words, and unique expressions. This demonstrates that our dataset will be a valuable contribution to both the text-to-SQL community and the development of resources for low-resource languages.
Casablanca: Data and Models for Multidialectal Arabic Speech Recognition
Oct 06, 2024



In spite of the recent progress in speech processing, the majority of world languages and dialects remain uncovered. This situation only furthers an already wide technological divide, thereby hindering technological and socioeconomic inclusion. This challenge is largely due to the absence of datasets that can empower diverse speech systems. In this paper, we seek to mitigate this obstacle for a number of Arabic dialects by presenting Casablanca, a large-scale community-driven effort to collect and transcribe a multi-dialectal Arabic dataset. The dataset covers eight dialects: Algerian, Egyptian, Emirati, Jordanian, Mauritanian, Moroccan, Palestinian, and Yemeni, and includes annotations for transcription, gender, dialect, and code-switching. We also develop a number of strong baselines exploiting Casablanca. The project page for Casablanca is accessible at: www.dlnlp.ai/speech/casablanca.
DomURLs_BERT: Pre-trained BERT-based Model for Malicious Domains and URLs Detection and Classification
Sep 13, 2024Detecting and classifying suspicious or malicious domain names and URLs is fundamental task in cybersecurity. To leverage such indicators of compromise, cybersecurity vendors and practitioners often maintain and update blacklists of known malicious domains and URLs. However, blacklists frequently fail to identify emerging and obfuscated threats. Over the past few decades, there has been significant interest in developing machine learning models that automatically detect malicious domains and URLs, addressing the limitations of blacklists maintenance and updates. In this paper, we introduce DomURLs_BERT, a pre-trained BERT-based encoder adapted for detecting and classifying suspicious/malicious domains and URLs. DomURLs_BERT is pre-trained using the Masked Language Modeling (MLM) objective on a large multilingual corpus of URLs, domain names, and Domain Generation Algorithms (DGA) dataset. In order to assess the performance of DomURLs_BERT, we have conducted experiments on several binary and multi-class classification tasks involving domain names and URLs, covering phishing, malware, DGA, and DNS tunneling. The evaluations results show that the proposed encoder outperforms state-of-the-art character-based deep learning models and cybersecurity-focused BERT models across multiple tasks and datasets. The pre-training dataset, the pre-trained DomURLs_BERT encoder, and the experiments source code are publicly available.
AraFinNLP 2024: The First Arabic Financial NLP Shared Task
Jul 13, 2024



The expanding financial markets of the Arab world require sophisticated Arabic NLP tools. To address this need within the banking domain, the Arabic Financial NLP (AraFinNLP) shared task proposes two subtasks: (i) Multi-dialect Intent Detection and (ii) Cross-dialect Translation and Intent Preservation. This shared task uses the updated ArBanking77 dataset, which includes about 39k parallel queries in MSA and four dialects. Each query is labeled with one or more of a common 77 intents in the banking domain. These resources aim to foster the development of robust financial Arabic NLP, particularly in the areas of machine translation and banking chat-bots. A total of 45 unique teams registered for this shared task, with 11 of them actively participated in the test phase. Specifically, 11 teams participated in Subtask 1, while only 1 team participated in Subtask 2. The winning team of Subtask 1 achieved F1 score of 0.8773, and the only team submitted in Subtask 2 achieved a 1.667 BLEU score.
DarijaBanking: A New Resource for Overcoming Language Barriers in Banking Intent Detection for Moroccan Arabic Speakers
May 26, 2024



Navigating the complexities of language diversity is a central challenge in developing robust natural language processing systems, especially in specialized domains like banking. The Moroccan Dialect (Darija) serves as the common language that blends cultural complexities, historical impacts, and regional differences. The complexities of Darija present a special set of challenges for language models, as it differs from Modern Standard Arabic with strong influence from French, Spanish, and Tamazight, it requires a specific approach for effective communication. To tackle these challenges, this paper introduces \textbf{DarijaBanking}, a novel Darija dataset aimed at enhancing intent classification in the banking domain, addressing the critical need for automatic banking systems (e.g., chatbots) that communicate in the native language of Moroccan clients. DarijaBanking comprises over 1,800 parallel high-quality queries in Darija, Modern Standard Arabic (MSA), English, and French, organized into 24 intent classes. We experimented with various intent classification methods, including full fine-tuning of monolingual and multilingual models, zero-shot learning, retrieval-based approaches, and Large Language Model prompting. One of the main contributions of this work is BERTouch, our BERT-based language model for intent classification in Darija. BERTouch achieved F1-scores of 0.98 for Darija and 0.96 for MSA on DarijaBanking, outperforming the state-of-the-art alternatives including GPT-4 showcasing its effectiveness in the targeted application.
Arabic Text Diacritization In The Age Of Transfer Learning: Token Classification Is All You Need
Jan 09, 2024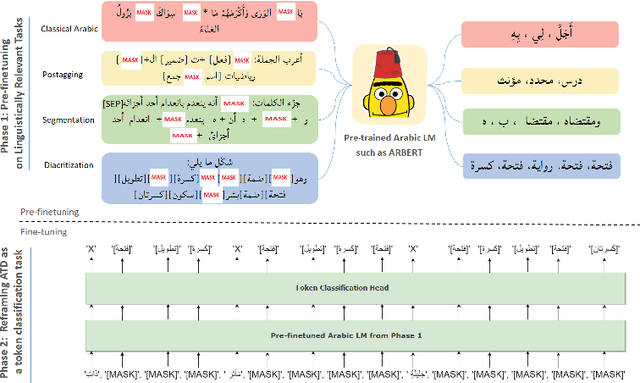


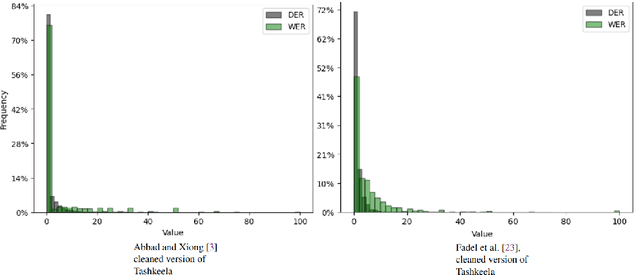
Automatic diacritization of Arabic text involves adding diacritical marks (diacritics) to the text. This task poses a significant challenge with noteworthy implications for computational processing and comprehension. In this paper, we introduce PTCAD (Pre-FineTuned Token Classification for Arabic Diacritization, a novel two-phase approach for the Arabic Text Diacritization task. PTCAD comprises a pre-finetuning phase and a finetuning phase, treating Arabic Text Diacritization as a token classification task for pre-trained models. The effectiveness of PTCAD is demonstrated through evaluations on two benchmark datasets derived from the Tashkeela dataset, where it achieves state-of-the-art results, including a 20\% reduction in Word Error Rate (WER) compared to existing benchmarks and superior performance over GPT-4 in ATD tasks.
CT-xCOV: a CT-scan based Explainable Framework for COVid-19 diagnosis
Nov 24, 2023



In this work, CT-xCOV, an explainable framework for COVID-19 diagnosis using Deep Learning (DL) on CT-scans is developed. CT-xCOV adopts an end-to-end approach from lung segmentation to COVID-19 detection and explanations of the detection model's prediction. For lung segmentation, we used the well-known U-Net model. For COVID-19 detection, we compared three different CNN architectures: a standard CNN, ResNet50, and DenseNet121. After the detection, visual and textual explanations are provided. For visual explanations, we applied three different XAI techniques, namely, Grad-Cam, Integrated Gradient (IG), and LIME. Textual explanations are added by computing the percentage of infection by lungs. To assess the performance of the used XAI techniques, we propose a ground-truth-based evaluation method, measuring the similarity between the visualization outputs and the ground-truth infections. The performed experiments show that the applied DL models achieved good results. The U-Net segmentation model achieved a high Dice coefficient (98%). The performance of our proposed classification model (standard CNN) was validated using 5-fold cross-validation (acc of 98.40% and f1-score 98.23%). Lastly, the results of the comparison of XAI techniques show that Grad-Cam gives the best explanations compared to LIME and IG, by achieving a Dice coefficient of 55%, on COVID-19 positive scans, compared to 29% and 24% obtained by IG and LIME respectively. The code and the dataset used in this paper are available in the GitHub repository [1].