 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArabic Text Diacritization In The Age Of Transfer Learning: Token Classification Is All You Need
Paper and Code
Jan 09, 2024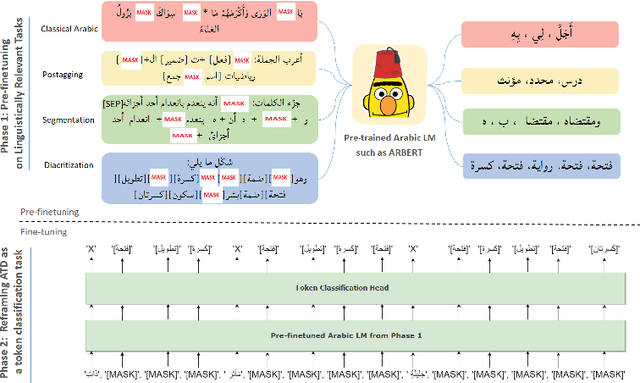


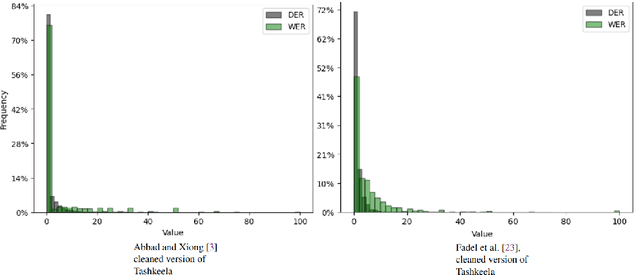
Automatic diacritization of Arabic text involves adding diacritical marks (diacritics) to the text. This task poses a significant challenge with noteworthy implications for computational processing and comprehension. In this paper, we introduce PTCAD (Pre-FineTuned Token Classification for Arabic Diacritization, a novel two-phase approach for the Arabic Text Diacritization task. PTCAD comprises a pre-finetuning phase and a finetuning phase, treating Arabic Text Diacritization as a token classification task for pre-trained models. The effectiveness of PTCAD is demonstrated through evaluations on two benchmark datasets derived from the Tashkeela dataset, where it achieves state-of-the-art results, including a 20\% reduction in Word Error Rate (WER) compared to existing benchmarks and superior performance over GPT-4 in ATD tasks.