 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAHaSIS: Shared Task on Sentiment Analysis for Arabic Dialects
Nov 17, 2025The hospitality industry in the Arab world increasingly relies on customer feedback to shape services, driving the need for advanced Arabic sentiment analysis tools. To address this challenge, the Sentiment Analysis on Arabic Dialects in the Hospitality Domain shared task focuses on Sentiment Detection in Arabic Dialects. This task leverages a multi-dialect, manually curated dataset derived from hotel reviews originally written in Modern Standard Arabic (MSA) and translated into Saudi and Moroccan (Darija) dialects. The dataset consists of 538 sentiment-balanced reviews spanning positive, neutral, and negative categories. Translations were validated by native speakers to ensure dialectal accuracy and sentiment preservation. This resource supports the development of dialect-aware NLP systems for real-world applications in customer experience analysis. More than 40 teams have registered for the shared task, with 12 submitting systems during the evaluation phase. The top-performing system achieved an F1 score of 0.81, demonstrating the feasibility and ongoing challenges of sentiment analysis across Arabic dialects.
M-DAIGT: A Shared Task on Multi-Domain Detection of AI-Generated Text
Nov 14, 2025The generation of highly fluent text by Large Language Models (LLMs) poses a significant challenge to information integrity and academic research. In this paper, we introduce the Multi-Domain Detection of AI-Generated Text (M-DAIGT) shared task, which focuses on detecting AI-generated text across multiple domains, particularly in news articles and academic writing. M-DAIGT comprises two binary classification subtasks: News Article Detection (NAD) (Subtask 1) and Academic Writing Detection (AWD) (Subtask 2). To support this task, we developed and released a new large-scale benchmark dataset of 30,000 samples, balanced between human-written and AI-generated texts. The AI-generated content was produced using a variety of modern LLMs (e.g., GPT-4, Claude) and diverse prompting strategies. A total of 46 unique teams registered for the shared task, of which four teams submitted final results. All four teams participated in both Subtask 1 and Subtask 2. We describe the methods employed by these participating teams and briefly discuss future directions for M-DAIGT.
AraReasoner: Evaluating Reasoning-Based LLMs for Arabic NLP
Jun 11, 2025Large language models (LLMs) have shown remarkable progress in reasoning abilities and general natural language processing (NLP) tasks, yet their performance on Arabic data, characterized by rich morphology, diverse dialects, and complex script, remains underexplored. This paper presents a comprehensive benchmarking study of multiple reasoning-focused LLMs, with a special emphasis on the newly introduced DeepSeek models, across a suite of fifteen Arabic NLP tasks. We experiment with various strategies, including zero-shot, few-shot, and fine-tuning. This allows us to systematically evaluate performance on datasets covering a range of applications to examine their capacity for linguistic reasoning under different levels of complexity. Our experiments reveal several key findings. First, carefully selecting just three in-context examples delivers an average uplift of over 13 F1 points on classification tasks-boosting sentiment analysis from 35.3% to 87.5% and paraphrase detection from 56.1% to 87.0%. Second, reasoning-focused DeepSeek architectures outperform a strong GPT o4-mini baseline by an average of 12 F1 points on complex inference tasks in the zero-shot setting. Third, LoRA-based fine-tuning yields up to an additional 8 points in F1 and BLEU compared to equivalent increases in model scale. The code is available at https://anonymous.4open.science/r/AraReasoner41299
Is LLM the Silver Bullet to Low-Resource Languages Machine Translation?
Mar 31, 2025
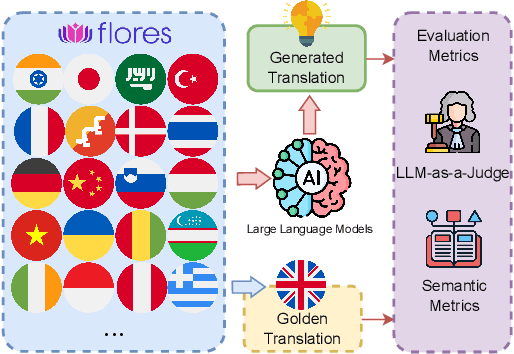
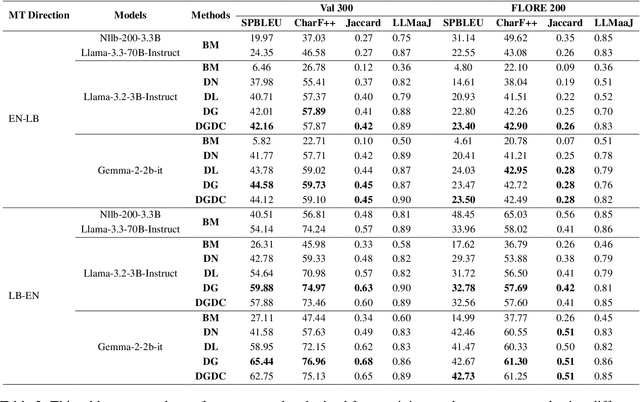
Low-Resource Languages (LRLs) present significant challenges in natural language processing due to their limited linguistic resources and underrepresentation in standard datasets. While recent advancements in Large Language Models (LLMs) and Neural Machine Translation (NMT) have substantially improved translation capabilities for high-resource languages, performance disparities persist for LRLs, particularly impacting privacy-sensitive and resource-constrained scenarios. This paper systematically evaluates the limitations of current LLMs across 200 languages using benchmarks such as FLORES-200. We also explore alternative data sources, including news articles and bilingual dictionaries, and demonstrate how knowledge distillation from large pre-trained models can significantly improve smaller LRL translations. Additionally, we investigate various fine-tuning strategies, revealing that incremental enhancements markedly reduce performance gaps on smaller LLMs.
Dialect2SQL: A Novel Text-to-SQL Dataset for Arabic Dialects with a Focus on Moroccan Darija
Jan 20, 2025



The task of converting natural language questions (NLQs) into executable SQL queries, known as text-to-SQL, has gained significant interest in recent years, as it enables non-technical users to interact with relational databases. Many benchmarks, such as SPIDER and WikiSQL, have contributed to the development of new models and the evaluation of their performance. In addition, other datasets, like SEDE and BIRD, have introduced more challenges and complexities to better map real-world scenarios. However, these datasets primarily focus on high-resource languages such as English and Chinese. In this work, we introduce Dialect2SQL, the first large-scale, cross-domain text-to-SQL dataset in an Arabic dialect. It consists of 9,428 NLQ-SQL pairs across 69 databases in various domains. Along with SQL-related challenges such as long schemas, dirty values, and complex queries, our dataset also incorporates the complexities of the Moroccan dialect, which is known for its diverse source languages, numerous borrowed words, and unique expressions. This demonstrates that our dataset will be a valuable contribution to both the text-to-SQL community and the development of resources for low-resource languages.
CallNavi: A Study and Challenge on Function Calling Routing and Invocation in Large Language Models
Jan 09, 2025
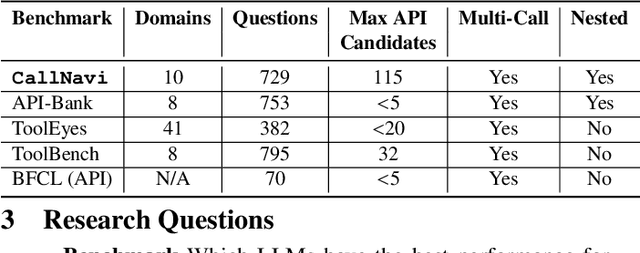


Interacting with a software system via a chatbot can be challenging, especially when the chatbot needs to generate API calls, in the right order and with the right parameters, to communicate with the system. API calling in chatbot systems poses significant challenges, particularly in complex, multi-step tasks requiring accurate API selection and execution. We contribute to this domain in three ways: first, by introducing a novel dataset designed to assess models on API function selection, parameter generation, and nested API calls; second, by benchmarking state-of-the-art language models across varying levels of complexity to evaluate their performance in API function generation and parameter accuracy; and third, by proposing an enhanced API routing method that combines general-purpose large language models for API selection with fine-tuned models for parameter generation and some prompt engineering approach. These approaches lead to substantial improvements in handling complex API tasks, offering practical advancements for real-world API-driven chatbot systems.
DreamFactory: Pioneering Multi-Scene Long Video Generation with a Multi-Agent Framework
Aug 21, 2024Current video generation models excel at creating short, realistic clips, but struggle with longer, multi-scene videos. We introduce \texttt{DreamFactory}, an LLM-based framework that tackles this challenge. \texttt{DreamFactory} leverages multi-agent collaboration principles and a Key Frames Iteration Design Method to ensure consistency and style across long videos. It utilizes Chain of Thought (COT) to address uncertainties inherent in large language models. \texttt{DreamFactory} generates long, stylistically coherent, and complex videos. Evaluating these long-form videos presents a challenge. We propose novel metrics such as Cross-Scene Face Distance Score and Cross-Scene Style Consistency Score. To further research in this area, we contribute the Multi-Scene Videos Dataset containing over 150 human-rated videos.
AraFinNLP 2024: The First Arabic Financial NLP Shared Task
Jul 13, 2024



The expanding financial markets of the Arab world require sophisticated Arabic NLP tools. To address this need within the banking domain, the Arabic Financial NLP (AraFinNLP) shared task proposes two subtasks: (i) Multi-dialect Intent Detection and (ii) Cross-dialect Translation and Intent Preservation. This shared task uses the updated ArBanking77 dataset, which includes about 39k parallel queries in MSA and four dialects. Each query is labeled with one or more of a common 77 intents in the banking domain. These resources aim to foster the development of robust financial Arabic NLP, particularly in the areas of machine translation and banking chat-bots. A total of 45 unique teams registered for this shared task, with 11 of them actively participated in the test phase. Specifically, 11 teams participated in Subtask 1, while only 1 team participated in Subtask 2. The winning team of Subtask 1 achieved F1 score of 0.8773, and the only team submitted in Subtask 2 achieved a 1.667 BLEU score.
DarijaBanking: A New Resource for Overcoming Language Barriers in Banking Intent Detection for Moroccan Arabic Speakers
May 26, 2024



Navigating the complexities of language diversity is a central challenge in developing robust natural language processing systems, especially in specialized domains like banking. The Moroccan Dialect (Darija) serves as the common language that blends cultural complexities, historical impacts, and regional differences. The complexities of Darija present a special set of challenges for language models, as it differs from Modern Standard Arabic with strong influence from French, Spanish, and Tamazight, it requires a specific approach for effective communication. To tackle these challenges, this paper introduces \textbf{DarijaBanking}, a novel Darija dataset aimed at enhancing intent classification in the banking domain, addressing the critical need for automatic banking systems (e.g., chatbots) that communicate in the native language of Moroccan clients. DarijaBanking comprises over 1,800 parallel high-quality queries in Darija, Modern Standard Arabic (MSA), English, and French, organized into 24 intent classes. We experimented with various intent classification methods, including full fine-tuning of monolingual and multilingual models, zero-shot learning, retrieval-based approaches, and Large Language Model prompting. One of the main contributions of this work is BERTouch, our BERT-based language model for intent classification in Darija. BERTouch achieved F1-scores of 0.98 for Darija and 0.96 for MSA on DarijaBanking, outperforming the state-of-the-art alternatives including GPT-4 showcasing its effectiveness in the targeted application.
Just-in-Time Security Patch Detection -- LLM At the Rescue for Data Augmentation
Dec 02, 2023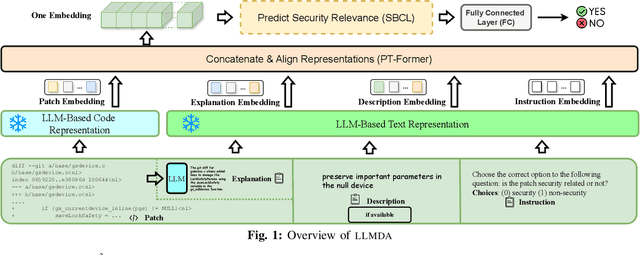
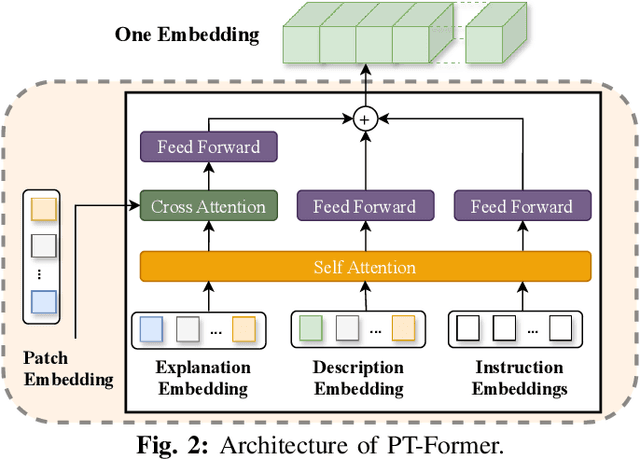
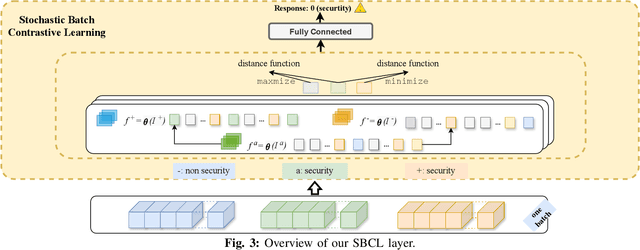
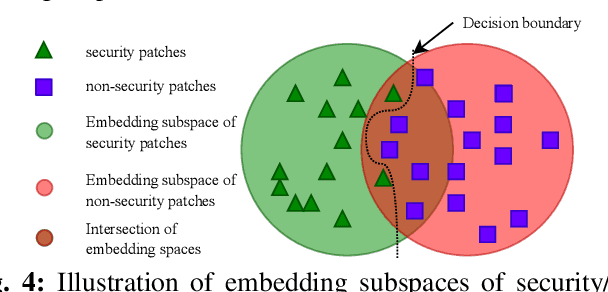
In the face of growing vulnerabilities found in open-source software, the need to identify {discreet} security patches has become paramount. The lack of consistency in how software providers handle maintenance often leads to the release of security patches without comprehensive advisories, leaving users vulnerable to unaddressed security risks. To address this pressing issue, we introduce a novel security patch detection system, LLMDA, which capitalizes on Large Language Models (LLMs) and code-text alignment methodologies for patch review, data enhancement, and feature combination. Within LLMDA, we initially utilize LLMs for examining patches and expanding data of PatchDB and SPI-DB, two security patch datasets from recent literature. We then use labeled instructions to direct our LLMDA, differentiating patches based on security relevance. Following this, we apply a PTFormer to merge patches with code, formulating hybrid attributes that encompass both the innate details and the interconnections between the patches and the code. This distinctive combination method allows our system to capture more insights from the combined context of patches and code, hence improving detection precision. Finally, we devise a probabilistic batch contrastive learning mechanism within batches to augment the capability of the our LLMDA in discerning security patches. The results reveal that LLMDA significantly surpasses the start of the art techniques in detecting security patches, underscoring its promise in fortifying software maintenance.