 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAudio-Reasoner: Improving Reasoning Capability in Large Audio Language Models
Mar 04, 2025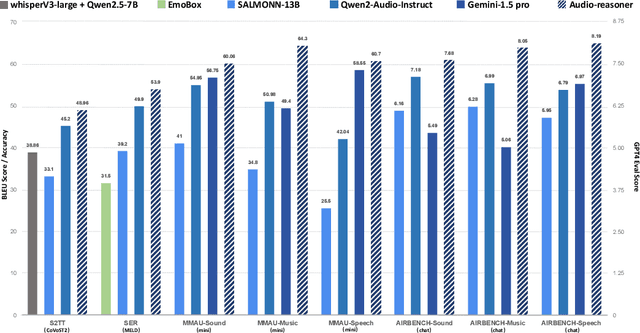
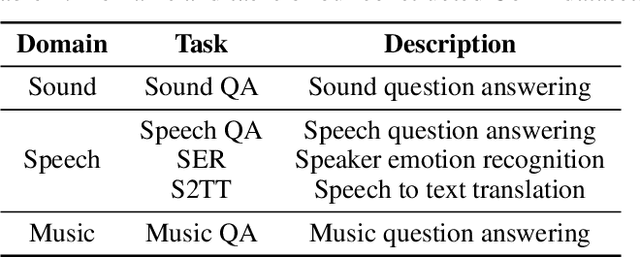
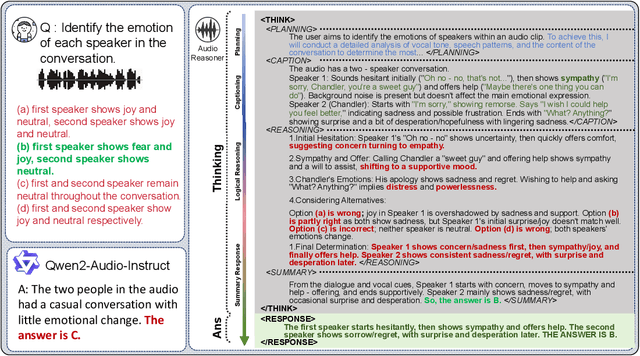

Recent advancements in multimodal reasoning have largely overlooked the audio modality. We introduce Audio-Reasoner, a large-scale audio language model for deep reasoning in audio tasks. We meticulously curated a large-scale and diverse multi-task audio dataset with simple annotations. Then, we leverage closed-source models to conduct secondary labeling, QA generation, along with structured COT process. These datasets together form a high-quality reasoning dataset with 1.2 million reasoning-rich samples, which we name CoTA. Following inference scaling principles, we train Audio-Reasoner on CoTA, enabling it to achieve great logical capabilities in audio reasoning. Experiments show state-of-the-art performance across key benchmarks, including MMAU-mini (+25.42%), AIR-Bench chat/foundation(+14.57%/+10.13%), and MELD (+8.01%). Our findings stress the core of structured CoT training in advancing audio reasoning.
Mini-Omni2: Towards Open-source GPT-4o with Vision, Speech and Duplex Capabilities
Oct 16, 2024



GPT-4o, an all-encompassing model, represents a milestone in the development of large multi-modal language models. It can understand visual, auditory, and textual modalities, directly output audio, and support flexible duplex interaction. Models from the open-source community often achieve some functionalities of GPT-4o, such as visual understanding and voice chat. Nevertheless, training a unified model that incorporates all modalities is challenging due to the complexities of multi-modal data, intricate model architectures, and training processes. In this paper, we introduce Mini-Omni2, a visual-audio assistant capable of providing real-time, end-to-end voice responses to visoin and audio queries. By integrating pretrained visual and auditory encoders, Mini-Omni2 maintains performance in individual modalities. We propose a three-stage training process to align modalities, allowing the language model to handle multi-modal inputs and outputs after training on a limited dataset. For interaction, we introduce a command-based interruption mechanism, enabling more flexible interaction with users. To the best of our knowledge, Mini-Omni2 is one of the closest reproductions of GPT-4o, which have similar form of functionality, and we hope it can offer valuable insights for subsequent research.
Mini-Omni2: Towards Open-source GPT-4o Model with Vision, Speech and Duplex
Oct 15, 2024GPT4o, an all-encompassing model, represents a milestone in the development of multi-modal large models. It can understand visual, auditory, and textual modalities, directly output audio, and support flexible duplex interaction. However, its technical framework is not open-sourced. Models from the open-source community often achieve some functionalities of GPT4o, such as visual understanding and voice dialogue. Nevertheless, training a unified model that incorporates all modalities is challenging due to the complexities of multi-modal data, intricate model architectures, and training processes. In this paper, we introduce Mini-Omni2, a visual-audio assistant capable of providing real-time, end-to-end voice responses to user video and voice queries, while also incorporating auditory capabilities. By integrating pretrained visual and auditory encoders, Mini-Omni2 maintains strong performance in individual modalities. We propose a three-stage training process to align modalities, allowing the language model to handle multi-modal inputs and outputs after training on a limited dataset. For interaction, we introduce a semantic-based interruption mechanism, enabling more flexible dialogues with users. All modeling approaches and data construction methods will be open-sourced. To the best of our knowledge, Mini-Omni2 is one of the models closest to GPT4o in functionality, and we hope it can offer valuable insights for subsequent research.
Mini-Omni: Language Models Can Hear, Talk While Thinking in Streaming
Aug 30, 2024Recent advances in language models have achieved significant progress. GPT-4o, as a new milestone, has enabled real-time conversations with humans, demonstrating near-human natural fluency. Such human-computer interaction necessitates models with the capability to perform reasoning directly with the audio modality and generate output in streaming. However, this remains beyond the reach of current academic models, as they typically depend on extra TTS systems for speech synthesis, resulting in undesirable latency. This paper introduces the Mini-Omni, an audio-based end-to-end conversational model, capable of real-time speech interaction. To achieve this capability, we propose a text-instructed speech generation method, along with batch-parallel strategies during inference to further boost the performance. Our method also helps to retain the original model's language capabilities with minimal degradation, enabling other works to establish real-time interaction capabilities. We call this training method "Any Model Can Talk". We also introduce the VoiceAssistant-400K dataset to fine-tune models optimized for speech output. To our best knowledge, Mini-Omni is the first fully end-to-end, open-source model for real-time speech interaction, offering valuable potential for future research.
DreamFactory: Pioneering Multi-Scene Long Video Generation with a Multi-Agent Framework
Aug 21, 2024Current video generation models excel at creating short, realistic clips, but struggle with longer, multi-scene videos. We introduce \texttt{DreamFactory}, an LLM-based framework that tackles this challenge. \texttt{DreamFactory} leverages multi-agent collaboration principles and a Key Frames Iteration Design Method to ensure consistency and style across long videos. It utilizes Chain of Thought (COT) to address uncertainties inherent in large language models. \texttt{DreamFactory} generates long, stylistically coherent, and complex videos. Evaluating these long-form videos presents a challenge. We propose novel metrics such as Cross-Scene Face Distance Score and Cross-Scene Style Consistency Score. To further research in this area, we contribute the Multi-Scene Videos Dataset containing over 150 human-rated videos.