 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAudio Interaction Model
Jun 03, 2026Audio is an inherently interactive modality, yet today's Large Audio Language Models (LALMs) are offline, and streaming audio models each handle only a single task such as streaming ASR or voice chatting. It is time to unify them into one online LALM: a model that, through an always-on perceive-decide-respond loop, listens to sound, environment, and instructions in real time and reacts on the fly. We formalize this regime as the Audio Interaction Model, and realize it with Audio-Interaction, a unified streaming model that retains offline task execution while adding online general audio instruction following, from dialogue to full voice chatting, deciding when to respond from the semantics of the stream. To enable this, we propose SoundFlow, a framework that instantiates the perceive-decide-respond loop end to end, from data to training to deployment, through streaming-native data construction, comprehension-aware training, and asynchronous low-latency inference for stable real-time interaction. We further construct StreamAudio-2M, a 2.6M-item streaming corpus spanning 7 fundamental abilities and 28 sub-tasks, and Proactive-Sound-Bench for evaluating proactive audio intervention. Across 8 benchmarks, Audio-Interaction preserves competitive performance on mainstream audio tasks while unlocking capabilities inaccessible to offline LALMs, including real-time ASR, streaming audio instruction following, and proactive help.
PASK: Toward Intent-Aware Proactive Agents with Long-Term Memory
Apr 09, 2026Proactivity is a core expectation for AGI. Prior work remains largely confined to laboratory settings, leaving a clear gap in real-world proactive agent: depth, complexity, ambiguity, precision and real-time constraints. We study this setting, where useful intervention requires inferring latent needs from ongoing context and grounding actions in evolving user memory under latency and long-horizon constraints. We first propose DD-MM-PAS (Demand Detection, Memory Modeling, Proactive Agent System) as a general paradigm for streaming proactive AI agent. We instantiate this paradigm in Pask, with streaming IntentFlow model for DD, a hybrid memory (workspace, user, global) for long-term MM, PAS infra framework and introduce how these components form a closed loop. We also introduce LatentNeeds-Bench, a real-world benchmark built from user-consented data and refined through thousands of rounds of human editing. Experiments show that IntentFlow matches leading Gemini3-Flash models under latency constraints, while identifying deeper user intent.
RMNP: Row-Momentum Normalized Preconditioning for Scalable Matrix-Based Optimization
Mar 20, 2026Preconditioned adaptive methods have gained significant attention for training deep neural networks, as they capture rich curvature information of the loss landscape . The central challenge in this field lies in balancing preconditioning effectiveness with computational efficiency of implementing the preconditioner. Among recent advances, \textsc{Muon} stands out by using Newton-Schulz iteration to obtain preconditioned updates without explicitly constructing the preconditioning matrix. Despite its advantages, the efficiency of \textsc{Muon} still leaves room for further improvement. In this paper, we introduce \textsc{RMNP} (Row Momentum Normalized Preconditioning), an optimizer that replaces Newton-Schulz iteration with a simple row-wise $\ell_2$ normalization operation, motivated by the empirically observed diagonal block structure of the Transformer layerwise Hessian. This substitution reduces the per-iteration computational complexity from $\mathcal{O}(mn\cdot\min(m,n))$ to $\mathcal{O}(mn)$ for an $m\times n$ weight matrix while maintaining comparable optimization performance. Theoretically, we establish convergence guarantees for \textsc{RMNP} in the non-convex setting that match recent results for \textsc{Muon} optimizers, achieving the information-theoretic minimax optimal complexity. Extensive experiments on large language model pretraining show that \textsc{RMNP} delivers competitive optimization performance compared with \textsc{Muon} while substantially reducing preconditioning wall-clock time. Our code is available at \href{https://anonymous.4open.science/r/RMNP-E8E1/}{this link}.
HTMuon: Improving Muon via Heavy-Tailed Spectral Correction
Mar 10, 2026Muon has recently shown promising results in LLM training. In this work, we study how to further improve Muon. We argue that Muon's orthogonalized update rule suppresses the emergence of heavy-tailed weight spectra and over-emphasizes the training along noise-dominated directions. Motivated by the Heavy-Tailed Self-Regularization (HT-SR) theory, we propose HTMuon. HTMuon preserves Muon's ability to capture parameter interdependencies while producing heavier-tailed updates and inducing heavier-tailed weight spectra. Experiments on LLM pretraining and image classification show that HTMuon consistently improves performance over state-of-the-art baselines and can also serve as a plug-in on top of existing Muon variants. For example, on LLaMA pretraining on the C4 dataset, HTMuon reduces perplexity by up to $0.98$ compared to Muon. We further theoretically show that HTMuon corresponds to steepest descent under the Schatten-$q$ norm constraint and provide convergence analysis in smooth non-convex settings. The implementation of HTMuon is available at https://github.com/TDCSZ327/HTmuon.
Learning to Discover Iterative Spectral Algorithms
Feb 10, 2026We introduce AutoSpec, a neural network framework for discovering iterative spectral algorithms for large-scale numerical linear algebra and numerical optimization. Our self-supervised models adapt to input operators using coarse spectral information (e.g., eigenvalue estimates and residual norms), and they predict recurrence coefficients for computing or applying a matrix polynomial tailored to a downstream task. The effectiveness of AutoSpec relies on three ingredients: an architecture whose inference pass implements short, executable numerical linear algebra recurrences; efficient training on small synthetic problems with transfer to large-scale real-world operators; and task-defined objectives that enforce the desired approximation or preconditioning behavior across the range of spectral profiles represented in the training set. We apply AutoSpec to discovering algorithms for representative numerical linear algebra tasks: accelerating matrix-function approximation; accelerating sparse linear solvers; and spectral filtering/preconditioning for eigenvalue computations. On real-world matrices, the learned procedures deliver orders-of-magnitude improvements in accuracy and/or reductions in iteration count, relative to basic baselines. We also find clear connections to classical theory: the induced polynomials often exhibit near-equiripple, near-minimax behavior characteristic of Chebyshev polynomials.
Semantic-Guided Diffusion Model for Single-Step Image Super-Resolution
May 11, 2025Diffusion-based image super-resolution (SR) methods have demonstrated remarkable performance. Recent advancements have introduced deterministic sampling processes that reduce inference from 15 iterative steps to a single step, thereby significantly improving the inference speed of existing diffusion models. However, their efficiency remains limited when handling complex semantic regions due to the single-step inference. To address this limitation, we propose SAMSR, a semantic-guided diffusion framework that incorporates semantic segmentation masks into the sampling process. Specifically, we introduce the SAM-Noise Module, which refines Gaussian noise using segmentation masks to preserve spatial and semantic features. Furthermore, we develop a pixel-wise sampling strategy that dynamically adjusts the residual transfer rate and noise strength based on pixel-level semantic weights, prioritizing semantically rich regions during the diffusion process. To enhance model training, we also propose a semantic consistency loss, which aligns pixel-wise semantic weights between predictions and ground truth. Extensive experiments on both real-world and synthetic datasets demonstrate that SAMSR significantly improves perceptual quality and detail recovery, particularly in semantically complex images. Our code is released at https://github.com/Liu-Zihang/SAMSR.
Audio-Reasoner: Improving Reasoning Capability in Large Audio Language Models
Mar 04, 2025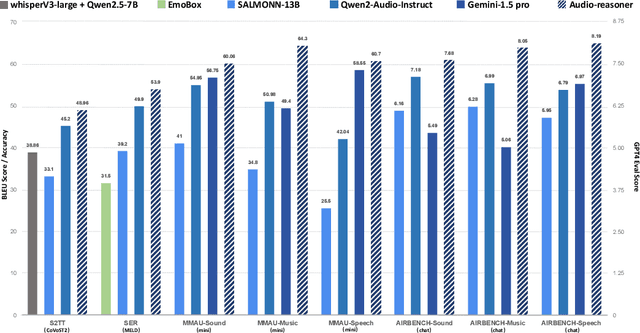
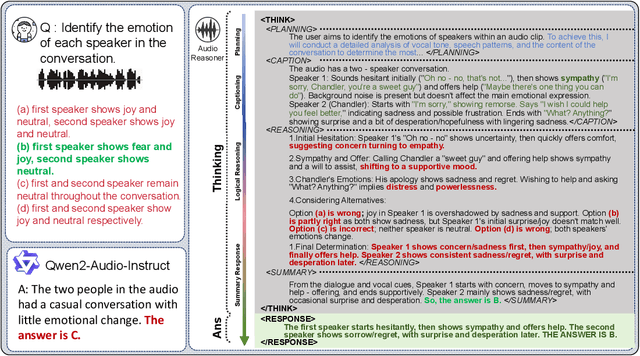

Recent advancements in multimodal reasoning have largely overlooked the audio modality. We introduce Audio-Reasoner, a large-scale audio language model for deep reasoning in audio tasks. We meticulously curated a large-scale and diverse multi-task audio dataset with simple annotations. Then, we leverage closed-source models to conduct secondary labeling, QA generation, along with structured COT process. These datasets together form a high-quality reasoning dataset with 1.2 million reasoning-rich samples, which we name CoTA. Following inference scaling principles, we train Audio-Reasoner on CoTA, enabling it to achieve great logical capabilities in audio reasoning. Experiments show state-of-the-art performance across key benchmarks, including MMAU-mini (+25.42%), AIR-Bench chat/foundation(+14.57%/+10.13%), and MELD (+8.01%). Our findings stress the core of structured CoT training in advancing audio reasoning.
Model Balancing Helps Low-data Training and Fine-tuning
Oct 16, 2024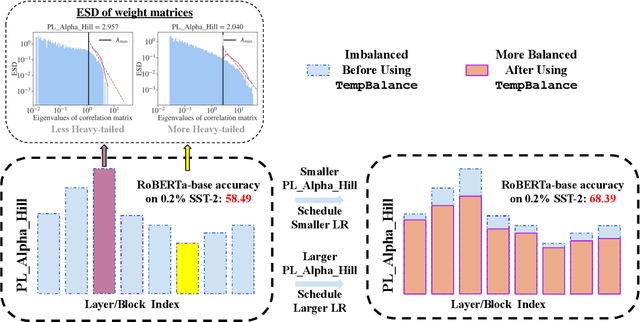

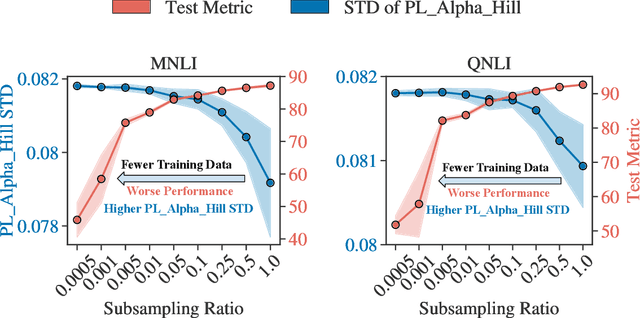
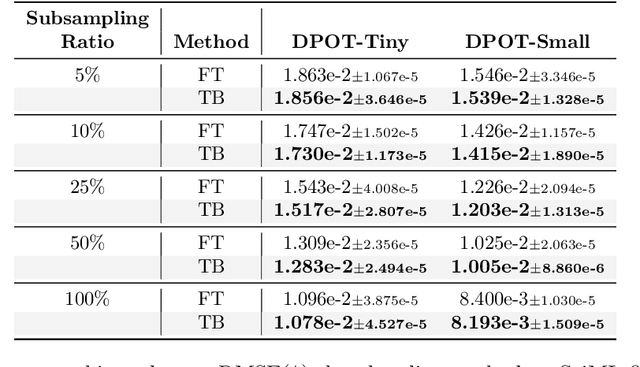
Recent advances in foundation models have emphasized the need to align pre-trained models with specialized domains using small, curated datasets. Studies on these foundation models underscore the importance of low-data training and fine-tuning. This topic, well-known in natural language processing (NLP), has also gained increasing attention in the emerging field of scientific machine learning (SciML). To address the limitations of low-data training and fine-tuning, we draw inspiration from Heavy-Tailed Self-Regularization (HT-SR) theory, analyzing the shape of empirical spectral densities (ESDs) and revealing an imbalance in training quality across different model layers. To mitigate this issue, we adapt a recently proposed layer-wise learning rate scheduler, TempBalance, which effectively balances training quality across layers and enhances low-data training and fine-tuning for both NLP and SciML tasks. Notably, TempBalance demonstrates increasing performance gains as the amount of available tuning data decreases. Comparative analyses further highlight the effectiveness of TempBalance and its adaptability as an "add-on" method for improving model performance.
A Simple Framework for Multi-mode Spatial-Temporal Data Modeling
Aug 22, 2023
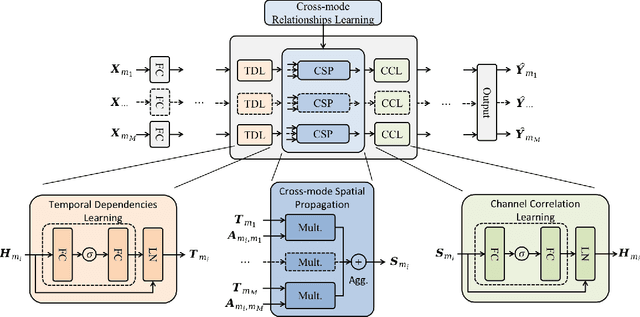
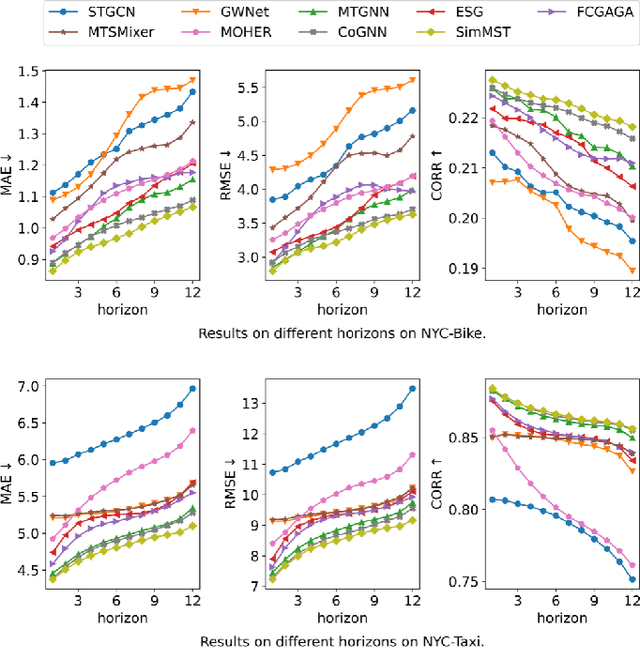

Spatial-temporal data modeling aims to mine the underlying spatial relationships and temporal dependencies of objects in a system. However, most existing methods focus on the modeling of spatial-temporal data in a single mode, lacking the understanding of multiple modes. Though very few methods have been presented to learn the multi-mode relationships recently, they are built on complicated components with higher model complexities. In this paper, we propose a simple framework for multi-mode spatial-temporal data modeling to bring both effectiveness and efficiency together. Specifically, we design a general cross-mode spatial relationships learning component to adaptively establish connections between multiple modes and propagate information along the learned connections. Moreover, we employ multi-layer perceptrons to capture the temporal dependencies and channel correlations, which are conceptually and technically succinct. Experiments on three real-world datasets show that our model can consistently outperform the baselines with lower space and time complexity, opening up a promising direction for modeling spatial-temporal data. The generalizability of the cross-mode spatial relationships learning module is also validated.
EnsembleMOT: A Step towards Ensemble Learning of Multiple Object Tracking
Oct 11, 2022
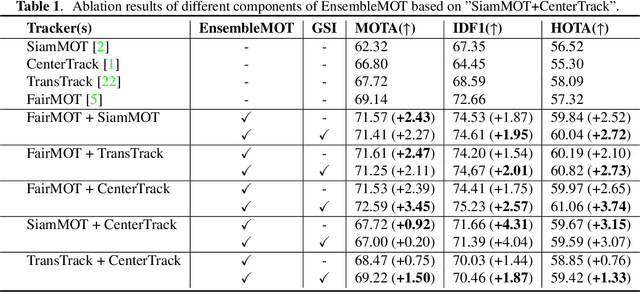

Multiple Object Tracking (MOT) has rapidly progressed in recent years. Existing works tend to design a single tracking algorithm to perform both detection and association. Though ensemble learning has been exploited in many tasks, i.e, classification and object detection, it hasn't been studied in the MOT task, which is mainly caused by its complexity and evaluation metrics. In this paper, we propose a simple but effective ensemble method for MOT, called EnsembleMOT, which merges multiple tracking results from various trackers with spatio-temporal constraints. Meanwhile, several post-processing procedures are applied to filter out abnormal results. Our method is model-independent and doesn't need the learning procedure. What's more, it can easily work in conjunction with other algorithms, e.g., tracklets interpolation. Experiments on the MOT17 dataset demonstrate the effectiveness of the proposed method. Codes are available at https://github.com/dyhBUPT/EnsembleMOT.