 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevealing Behavioral Plasticity in Large Language Models: A Token-Conditional Perspective
Mar 09, 2026In this work, we reveal that Large Language Models (LLMs) possess intrinsic behavioral plasticity-akin to chameleons adapting their coloration to environmental cues-that can be exposed through token-conditional generation and stabilized via reinforcement learning. Specifically, by conditioning generation on carefully selected token prefixes sampled from responses exhibiting desired behaviors, LLMs seamlessly adapt their behavioral modes at inference time (e.g., switching from step-by-step reasoning to direct answering) without retraining. Based on this insight, we propose Token-Conditioned Reinforcement Learning (ToCoRL), a principled framework that leverages RL to internalize this chameleon-like plasticity, transforming transient inference-time adaptations into stable and learnable behavioral patterns. ToCoRL guides exploration with token-conditional generation and keep enhancing exploitation, enabling emergence of appropriate behaviors. Extensive experiments show that ToCoRL enables precise behavioral control without capability degradation. Notably, we show that large reasoning models, while performing strongly on complex mathematics, can be effectively adapted to excel at factual question answering, which was a capability previously hindered by their step-by-step reasoning patterns.
Outcome Accuracy is Not Enough: Aligning the Reasoning Process of Reward Models
Feb 04, 2026Generative Reward Models (GenRMs) and LLM-as-a-Judge exhibit deceptive alignment by producing correct judgments for incorrect reasons, as they are trained and evaluated to prioritize Outcome Accuracy, which undermines their ability to generalize during RLHF. We introduce Rationale Consistency, a fine-grained metric that quantifies the alignment between the model's reasoning process and human judgment. Our evaluation of frontier models reveals that rationale consistency effectively discriminates among state-of-the-art models and detects deceptive alignment, while outcome accuracy falls short in both respects. To mitigate this gap, we introduce a hybrid signal that combines rationale consistency with outcome accuracy for GenRM training. Our training method achieves state-of-the-art performance on RM-Bench (87.1%) and JudgeBench (82%), surpassing outcome-only baselines by an average of 5%. Using RM during RLHF, our method effectively improves performance as demonstrated on Arena Hard v2, notably yielding a 7% improvement in creative writing tasks. Further analysis confirms that our method escapes the deceptive alignment trap, effectively reversing the decline in rationale consistency observed in outcome-only training.
Stealth Fine-Tuning: Efficiently Breaking Alignment in RVLMs Using Self-Generated CoT
Nov 18, 2025Reasoning-augmented Vision-Language Models (RVLMs) rely on safety alignment to prevent harmful behavior, yet their exposed chain-of-thought (CoT) traces introduce new attack surfaces. In this work, we find that the safety alignment of RVLMs can be easily break through a novel attack method termed \textbf{Stealth Fine-Tuning}. Our method elicits harmful reasoning traces through \textbf{segment-level interference} and reuses the self-generated outputs as supervised fine-tuning data. Through a \textbf{turn-based weighted} loss design, yielding a lightweight, distribution-consistent finetuning method. In our experiment, with only 499 samples and under 3 hours on a single A100 (QLoRA), Stealth Fine-Tuning outperforms IDEATOR by 38.52\% ASR while preserving general reasoning ability, as the tuned model retains the original representation distribution. Experiments on AdvBench and several general benchmarks demonstrate that Stealth Fine-Tuning is a low-cost and highly effective way to bypass alignment defenses. \textcolor{red}{\textbf{Disclaimer: This paper contains content that may be disturbing or offensive.}}
WorldPM: Scaling Human Preference Modeling
May 15, 2025Motivated by scaling laws in language modeling that demonstrate how test loss scales as a power law with model and dataset sizes, we find that similar laws exist in preference modeling. We propose World Preference Modeling$ (WorldPM) to emphasize this scaling potential, where World Preference embodies a unified representation of human preferences. In this paper, we collect preference data from public forums covering diverse user communities, and conduct extensive training using 15M-scale data across models ranging from 1.5B to 72B parameters. We observe distinct patterns across different evaluation metrics: (1) Adversarial metrics (ability to identify deceptive features) consistently scale up with increased training data and base model size; (2) Objective metrics (objective knowledge with well-defined answers) show emergent behavior in larger language models, highlighting WorldPM's scalability potential; (3) Subjective metrics (subjective preferences from a limited number of humans or AI) do not demonstrate scaling trends. Further experiments validate the effectiveness of WorldPM as a foundation for preference fine-tuning. Through evaluations on 7 benchmarks with 20 subtasks, we find that WorldPM broadly improves the generalization performance across human preference datasets of varying sizes (7K, 100K and 800K samples), with performance gains exceeding 5% on many key subtasks. Integrating WorldPM into our internal RLHF pipeline, we observe significant improvements on both in-house and public evaluation sets, with notable gains of 4% to 8% in our in-house evaluations.
Qwen3 Technical Report
May 14, 2025



In this work, we present Qwen3, the latest version of the Qwen model family. Qwen3 comprises a series of large language models (LLMs) designed to advance performance, efficiency, and multilingual capabilities. The Qwen3 series includes models of both dense and Mixture-of-Expert (MoE) architectures, with parameter scales ranging from 0.6 to 235 billion. A key innovation in Qwen3 is the integration of thinking mode (for complex, multi-step reasoning) and non-thinking mode (for rapid, context-driven responses) into a unified framework. This eliminates the need to switch between different models--such as chat-optimized models (e.g., GPT-4o) and dedicated reasoning models (e.g., QwQ-32B)--and enables dynamic mode switching based on user queries or chat templates. Meanwhile, Qwen3 introduces a thinking budget mechanism, allowing users to allocate computational resources adaptively during inference, thereby balancing latency and performance based on task complexity. Moreover, by leveraging the knowledge from the flagship models, we significantly reduce the computational resources required to build smaller-scale models, while ensuring their highly competitive performance. Empirical evaluations demonstrate that Qwen3 achieves state-of-the-art results across diverse benchmarks, including tasks in code generation, mathematical reasoning, agent tasks, etc., competitive against larger MoE models and proprietary models. Compared to its predecessor Qwen2.5, Qwen3 expands multilingual support from 29 to 119 languages and dialects, enhancing global accessibility through improved cross-lingual understanding and generation capabilities. To facilitate reproducibility and community-driven research and development, all Qwen3 models are publicly accessible under Apache 2.0.
Gated Attention for Large Language Models: Non-linearity, Sparsity, and Attention-Sink-Free
May 10, 2025Gating mechanisms have been widely utilized, from early models like LSTMs and Highway Networks to recent state space models, linear attention, and also softmax attention. Yet, existing literature rarely examines the specific effects of gating. In this work, we conduct comprehensive experiments to systematically investigate gating-augmented softmax attention variants. Specifically, we perform a comprehensive comparison over 30 variants of 15B Mixture-of-Experts (MoE) models and 1.7B dense models trained on a 3.5 trillion token dataset. Our central finding is that a simple modification-applying a head-specific sigmoid gate after the Scaled Dot-Product Attention (SDPA)-consistently improves performance. This modification also enhances training stability, tolerates larger learning rates, and improves scaling properties. By comparing various gating positions and computational variants, we attribute this effectiveness to two key factors: (1) introducing non-linearity upon the low-rank mapping in the softmax attention, and (2) applying query-dependent sparse gating scores to modulate the SDPA output. Notably, we find this sparse gating mechanism mitigates 'attention sink' and enhances long-context extrapolation performance, and we also release related $\href{https://github.com/qiuzh20/gated_attention}{codes}$ and $\href{https://huggingface.co/QwQZh/gated_attention}{models}$ to facilitate future research.
Qwen2.5-1M Technical Report
Jan 26, 2025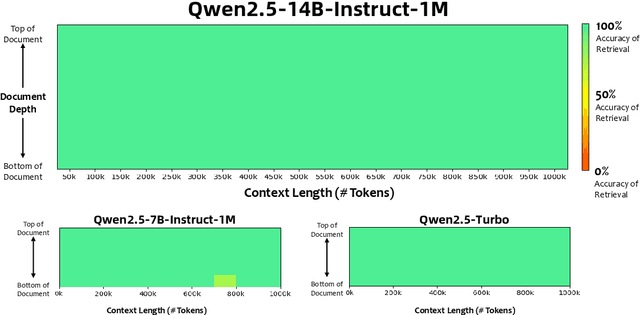

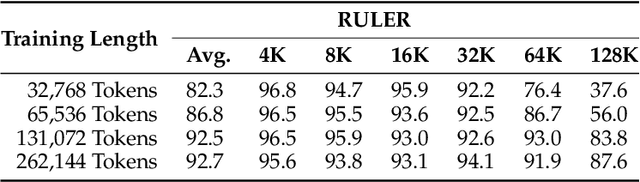
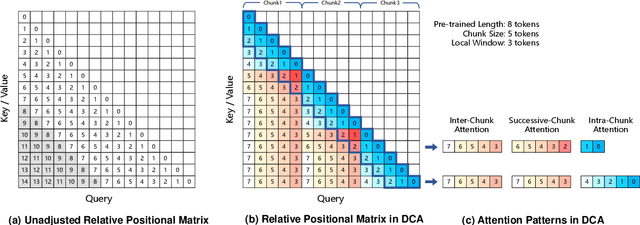
We introduce Qwen2.5-1M, a series of models that extend the context length to 1 million tokens. Compared to the previous 128K version, the Qwen2.5-1M series have significantly enhanced long-context capabilities through long-context pre-training and post-training. Key techniques such as long data synthesis, progressive pre-training, and multi-stage supervised fine-tuning are employed to effectively enhance long-context performance while reducing training costs. To promote the use of long-context models among a broader user base, we present and open-source our inference framework. This framework includes a length extrapolation method that can expand the model context lengths by at least four times, or even more, without additional training. To reduce inference costs, we implement a sparse attention method along with chunked prefill optimization for deployment scenarios and a sparsity refinement method to improve precision. Additionally, we detail our optimizations in the inference engine, including kernel optimization, pipeline parallelism, and scheduling optimization, which significantly enhance overall inference performance. By leveraging our inference framework, the Qwen2.5-1M models achieve a remarkable 3x to 7x prefill speedup in scenarios with 1 million tokens of context. This framework provides an efficient and powerful solution for developing applications that require long-context processing using open-source models. The Qwen2.5-1M series currently includes the open-source models Qwen2.5-7B-Instruct-1M and Qwen2.5-14B-Instruct-1M, as well as the API-accessed model Qwen2.5-Turbo. Evaluations show that Qwen2.5-1M models have been greatly improved in long-context tasks without compromising performance in short-context scenarios. Specifically, the Qwen2.5-14B-Instruct-1M model significantly outperforms GPT-4o-mini in long-context tasks and supports contexts eight times longer.
Channel Sounding Using Multiplicative Arrays Based on Successive Interference Cancellation Principle
Jan 19, 2025



Ultra-massive multiple-input and multiple-output (MIMO) systems have been seen as the key radio technology for the advancement of wireless communication systems, due to its capability to better utilize the spatial dimension of the propagation channels. Channel sounding is essential for developing accurate and realistic channel models for the massive MIMO systems. However, channel sounding with large-scale antenna systems has faced significant challenges in practice. The real antenna array based (RAA) sounder suffers from high complexity and cost, while virtual antenna array (VAA) solutions are known for its long measurement time. Notably, these issues will become more pronounced as the antenna array configuration gets larger for future radio systems. In this paper, we propose the concept of multiplicative array (MA) for channel sounding applications to achieve large antenna aperture size with reduced number of required antenna elements. The unique characteristics of the MA are exploited for wideband spatial channel sounding purposes, supported by both one-path and multi-path numerical simulations. To address the fake paths and distortion in the angle delay profile issues inherent for MA in multipath channel sounding, a novel channel parameter estimation algorithm for MA based on successive interference cancellation (SIC) principle is proposed. Both numerical simulations and experimental validation results are provided to demonstrate the effectiveness and robustness of the proposed SIC algorithm for the MA. This research contributes significantly to the channel sounding and characterization of massive MIMO systems for future applications.
Revolutionizing Encrypted Traffic Classification with MH-Net: A Multi-View Heterogeneous Graph Model
Jan 05, 2025



With the growing significance of network security, the classification of encrypted traffic has emerged as an urgent challenge. Traditional byte-based traffic analysis methods are constrained by the rigid granularity of information and fail to fully exploit the diverse correlations between bytes. To address these limitations, this paper introduces MH-Net, a novel approach for classifying network traffic that leverages multi-view heterogeneous traffic graphs to model the intricate relationships between traffic bytes. The essence of MH-Net lies in aggregating varying numbers of traffic bits into multiple types of traffic units, thereby constructing multi-view traffic graphs with diverse information granularities. By accounting for different types of byte correlations, such as header-payload relationships, MH-Net further endows the traffic graph with heterogeneity, significantly enhancing model performance. Notably, we employ contrastive learning in a multi-task manner to strengthen the robustness of the learned traffic unit representations. Experiments conducted on the ISCX and CIC-IoT datasets for both the packet-level and flow-level traffic classification tasks demonstrate that MH-Net achieves the best overall performance compared to dozens of SOTA methods.
Qwen2.5 Technical Report
Dec 19, 2024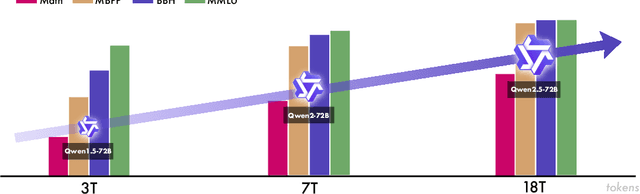

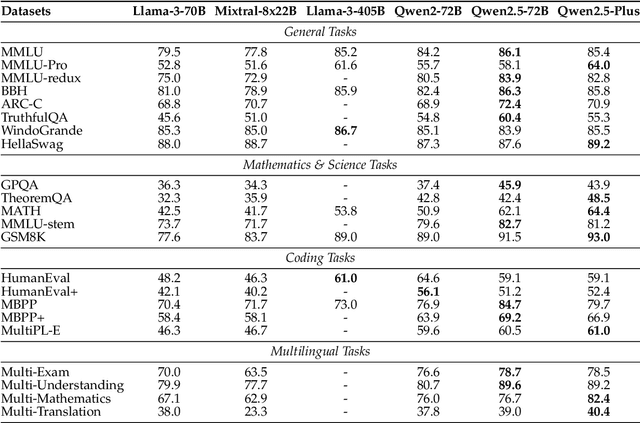
In this report, we introduce Qwen2.5, a comprehensive series of large language models (LLMs) designed to meet diverse needs. Compared to previous iterations, Qwen 2.5 has been significantly improved during both the pre-training and post-training stages. In terms of pre-training, we have scaled the high-quality pre-training datasets from the previous 7 trillion tokens to 18 trillion tokens. This provides a strong foundation for common sense, expert knowledge, and reasoning capabilities. In terms of post-training, we implement intricate supervised finetuning with over 1 million samples, as well as multistage reinforcement learning. Post-training techniques enhance human preference, and notably improve long text generation, structural data analysis, and instruction following. To handle diverse and varied use cases effectively, we present Qwen2.5 LLM series in rich sizes. Open-weight offerings include base and instruction-tuned models, with quantized versions available. In addition, for hosted solutions, the proprietary models currently include two mixture-of-experts (MoE) variants: Qwen2.5-Turbo and Qwen2.5-Plus, both available from Alibaba Cloud Model Studio. Qwen2.5 has demonstrated top-tier performance on a wide range of benchmarks evaluating language understanding, reasoning, mathematics, coding, human preference alignment, etc. Specifically, the open-weight flagship Qwen2.5-72B-Instruct outperforms a number of open and proprietary models and demonstrates competitive performance to the state-of-the-art open-weight model, Llama-3-405B-Instruct, which is around 5 times larger. Qwen2.5-Turbo and Qwen2.5-Plus offer superior cost-effectiveness while performing competitively against GPT-4o-mini and GPT-4o respectively. Additionally, as the foundation, Qwen2.5 models have been instrumental in training specialized models such as Qwen2.5-Math, Qwen2.5-Coder, QwQ, and multimodal models.