 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMARGE: Improving Math Reasoning for LLMs with Guided Exploration
May 18, 2025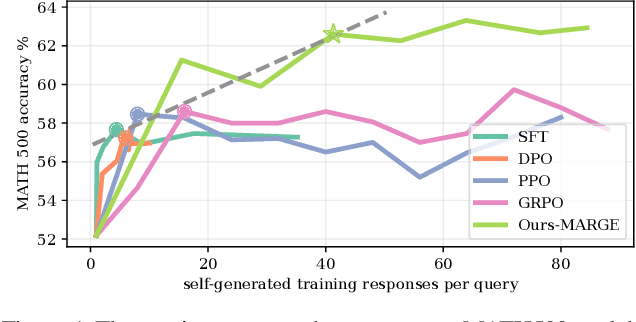
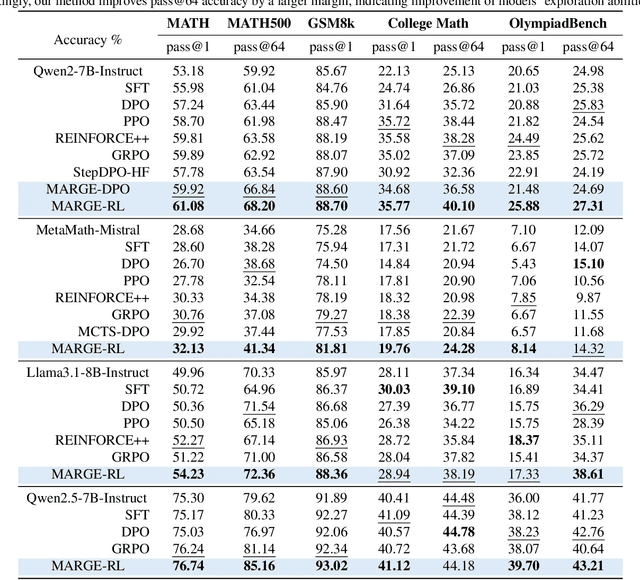
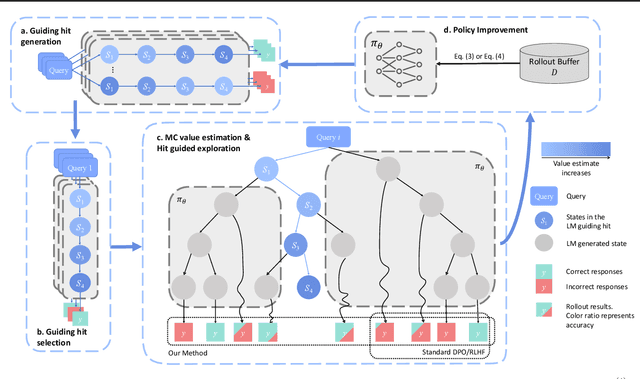
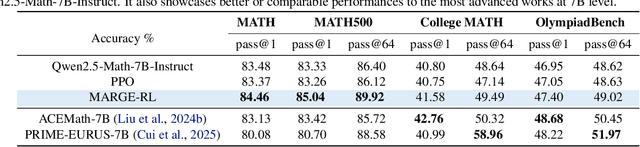
Large Language Models (LLMs) exhibit strong potential in mathematical reasoning, yet their effectiveness is often limited by a shortage of high-quality queries. This limitation necessitates scaling up computational responses through self-generated data, yet current methods struggle due to spurious correlated data caused by ineffective exploration across all reasoning stages. To address such challenge, we introduce \textbf{MARGE}: Improving \textbf{Ma}th \textbf{R}easoning with \textbf{G}uided \textbf{E}xploration, a novel method to address this issue and enhance mathematical reasoning through hit-guided exploration. MARGE systematically explores intermediate reasoning states derived from self-generated solutions, enabling adequate exploration and improved credit assignment throughout the reasoning process. Through extensive experiments across multiple backbone models and benchmarks, we demonstrate that MARGE significantly improves reasoning capabilities without requiring external annotations or training additional value models. Notably, MARGE improves both single-shot accuracy and exploration diversity, mitigating a common trade-off in alignment methods. These results demonstrate MARGE's effectiveness in enhancing mathematical reasoning capabilities and unlocking the potential of scaling self-generated training data. Our code and models are available at \href{https://github.com/georgao35/MARGE}{this link}.
WorldPM: Scaling Human Preference Modeling
May 15, 2025Motivated by scaling laws in language modeling that demonstrate how test loss scales as a power law with model and dataset sizes, we find that similar laws exist in preference modeling. We propose World Preference Modeling$ (WorldPM) to emphasize this scaling potential, where World Preference embodies a unified representation of human preferences. In this paper, we collect preference data from public forums covering diverse user communities, and conduct extensive training using 15M-scale data across models ranging from 1.5B to 72B parameters. We observe distinct patterns across different evaluation metrics: (1) Adversarial metrics (ability to identify deceptive features) consistently scale up with increased training data and base model size; (2) Objective metrics (objective knowledge with well-defined answers) show emergent behavior in larger language models, highlighting WorldPM's scalability potential; (3) Subjective metrics (subjective preferences from a limited number of humans or AI) do not demonstrate scaling trends. Further experiments validate the effectiveness of WorldPM as a foundation for preference fine-tuning. Through evaluations on 7 benchmarks with 20 subtasks, we find that WorldPM broadly improves the generalization performance across human preference datasets of varying sizes (7K, 100K and 800K samples), with performance gains exceeding 5% on many key subtasks. Integrating WorldPM into our internal RLHF pipeline, we observe significant improvements on both in-house and public evaluation sets, with notable gains of 4% to 8% in our in-house evaluations.
The Lessons of Developing Process Reward Models in Mathematical Reasoning
Jan 13, 2025



Process Reward Models (PRMs) emerge as a promising approach for process supervision in mathematical reasoning of Large Language Models (LLMs), which aim to identify and mitigate intermediate errors in the reasoning processes. However, the development of effective PRMs faces significant challenges, particularly in data annotation and evaluation methodologies. In this paper, through extensive experiments, we demonstrate that commonly used Monte Carlo (MC) estimation-based data synthesis for PRMs typically yields inferior performance and generalization compared to LLM-as-a-judge and human annotation methods. MC estimation relies on completion models to evaluate current-step correctness, leading to inaccurate step verification. Furthermore, we identify potential biases in conventional Best-of-N (BoN) evaluation strategies for PRMs: (1) The unreliable policy models generate responses with correct answers but flawed processes, leading to a misalignment between the evaluation criteria of BoN and the PRM objectives of process verification. (2) The tolerance of PRMs of such responses leads to inflated BoN scores. (3) Existing PRMs have a significant proportion of minimum scores concentrated on the final answer steps, revealing the shift from process to outcome-based assessment in BoN Optimized PRMs. To address these challenges, we develop a consensus filtering mechanism that effectively integrates MC estimation with LLM-as-a-judge and advocates a more comprehensive evaluation framework that combines response-level and step-level metrics. Based on the mechanisms, we significantly improve both model performance and data efficiency in the BoN evaluation and the step-wise error identification task. Finally, we release a new state-of-the-art PRM that outperforms existing open-source alternatives and provides practical guidelines for future research in building process supervision models.
Qwen2.5 Technical Report
Dec 19, 2024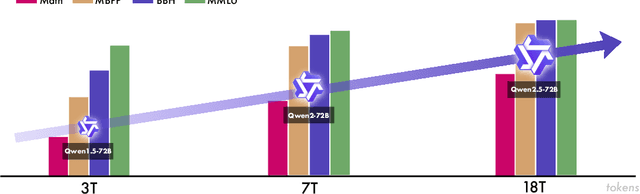

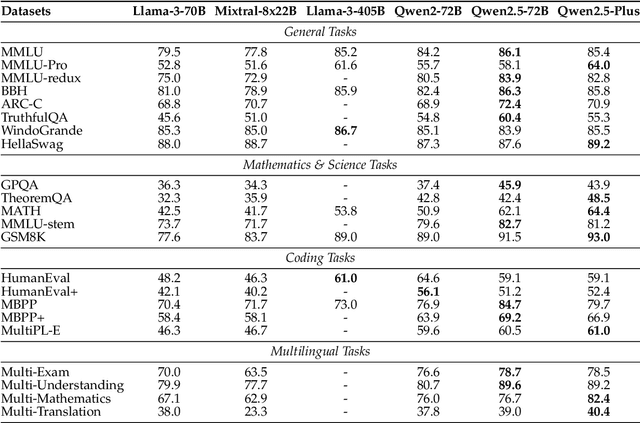
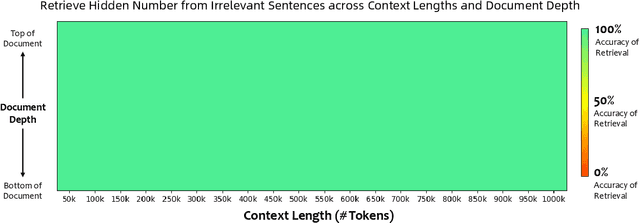
In this report, we introduce Qwen2.5, a comprehensive series of large language models (LLMs) designed to meet diverse needs. Compared to previous iterations, Qwen 2.5 has been significantly improved during both the pre-training and post-training stages. In terms of pre-training, we have scaled the high-quality pre-training datasets from the previous 7 trillion tokens to 18 trillion tokens. This provides a strong foundation for common sense, expert knowledge, and reasoning capabilities. In terms of post-training, we implement intricate supervised finetuning with over 1 million samples, as well as multistage reinforcement learning. Post-training techniques enhance human preference, and notably improve long text generation, structural data analysis, and instruction following. To handle diverse and varied use cases effectively, we present Qwen2.5 LLM series in rich sizes. Open-weight offerings include base and instruction-tuned models, with quantized versions available. In addition, for hosted solutions, the proprietary models currently include two mixture-of-experts (MoE) variants: Qwen2.5-Turbo and Qwen2.5-Plus, both available from Alibaba Cloud Model Studio. Qwen2.5 has demonstrated top-tier performance on a wide range of benchmarks evaluating language understanding, reasoning, mathematics, coding, human preference alignment, etc. Specifically, the open-weight flagship Qwen2.5-72B-Instruct outperforms a number of open and proprietary models and demonstrates competitive performance to the state-of-the-art open-weight model, Llama-3-405B-Instruct, which is around 5 times larger. Qwen2.5-Turbo and Qwen2.5-Plus offer superior cost-effectiveness while performing competitively against GPT-4o-mini and GPT-4o respectively. Additionally, as the foundation, Qwen2.5 models have been instrumental in training specialized models such as Qwen2.5-Math, Qwen2.5-Coder, QwQ, and multimodal models.
ProcessBench: Identifying Process Errors in Mathematical Reasoning
Dec 10, 2024



As language models regularly make mistakes when solving math problems, automated identification of errors in the reasoning process becomes increasingly significant for their scalable oversight. In this paper, we introduce ProcessBench for measuring the ability to identify erroneous steps in mathematical reasoning. It consists of 3,400 test cases, primarily focused on competition- and Olympiad-level math problems. Each test case contains a step-by-step solution with error location annotated by human experts. Models are required to identify the earliest step that contains an error, or conclude that all steps are correct. We conduct extensive evaluation on ProcessBench, involving two types of models: process reward models (PRMs) and critic models, where for the latter we prompt general language models to critique each solution step by step. We draw two main observations: (1) Existing PRMs typically fail to generalize to more challenging math problems beyond GSM8K and MATH. They underperform both critic models (i.e., prompted general language models) and our own trained PRM that is straightforwardly fine-tuned on the PRM800K dataset. (2) The best open-source model, QwQ-32B-Preview, has demonstrated the critique capability competitive with the proprietary model GPT-4o, despite that it still lags behind the reasoning-specialized o1-mini. We hope ProcessBench can foster future research in reasoning process assessment, paving the way toward scalable oversight of language models.
Qwen2.5-Math Technical Report: Toward Mathematical Expert Model via Self-Improvement
Sep 18, 2024In this report, we present a series of math-specific large language models: Qwen2.5-Math and Qwen2.5-Math-Instruct-1.5B/7B/72B. The core innovation of the Qwen2.5 series lies in integrating the philosophy of self-improvement throughout the entire pipeline, from pre-training and post-training to inference: (1) During the pre-training phase, Qwen2-Math-Instruct is utilized to generate large-scale, high-quality mathematical data. (2) In the post-training phase, we develop a reward model (RM) by conducting massive sampling from Qwen2-Math-Instruct. This RM is then applied to the iterative evolution of data in supervised fine-tuning (SFT). With a stronger SFT model, it's possible to iteratively train and update the RM, which in turn guides the next round of SFT data iteration. On the final SFT model, we employ the ultimate RM for reinforcement learning, resulting in the Qwen2.5-Math-Instruct. (3) Furthermore, during the inference stage, the RM is used to guide sampling, optimizing the model's performance. Qwen2.5-Math-Instruct supports both Chinese and English, and possess advanced mathematical reasoning capabilities, including Chain-of-Thought (CoT) and Tool-Integrated Reasoning (TIR). We evaluate our models on 10 mathematics datasets in both English and Chinese, such as GSM8K, MATH, GaoKao, AMC23, and AIME24, covering a range of difficulties from grade school level to math competition problems.
Online Decision MetaMorphFormer: A Casual Transformer-Based Reinforcement Learning Framework of Universal Embodied Intelligence
Sep 11, 2024Interactive artificial intelligence in the motion control field is an interesting topic, especially when universal knowledge is adaptive to multiple tasks and universal environments. Despite there being increasing efforts in the field of Reinforcement Learning (RL) with the aid of transformers, most of them might be limited by the offline training pipeline, which prohibits exploration and generalization abilities. To address this limitation, we propose the framework of Online Decision MetaMorphFormer (ODM) which aims to achieve self-awareness, environment recognition, and action planning through a unified model architecture. Motivated by cognitive and behavioral psychology, an ODM agent is able to learn from others, recognize the world, and practice itself based on its own experience. ODM can also be applied to any arbitrary agent with a multi-joint body, located in different environments, and trained with different types of tasks using large-scale pre-trained datasets. Through the use of pre-trained datasets, ODM can quickly warm up and learn the necessary knowledge to perform the desired task, while the target environment continues to reinforce the universal policy. Extensive online experiments as well as few-shot and zero-shot environmental tests are used to verify ODM's performance and generalization ability. The results of our study contribute to the study of general artificial intelligence in embodied and cognitive fields. Code, results, and video examples can be found on the website \url{https://rlodm.github.io/odm/}.
Qwen2 Technical Report
Jul 16, 2024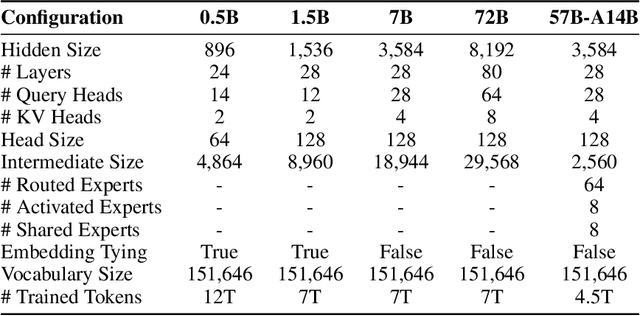
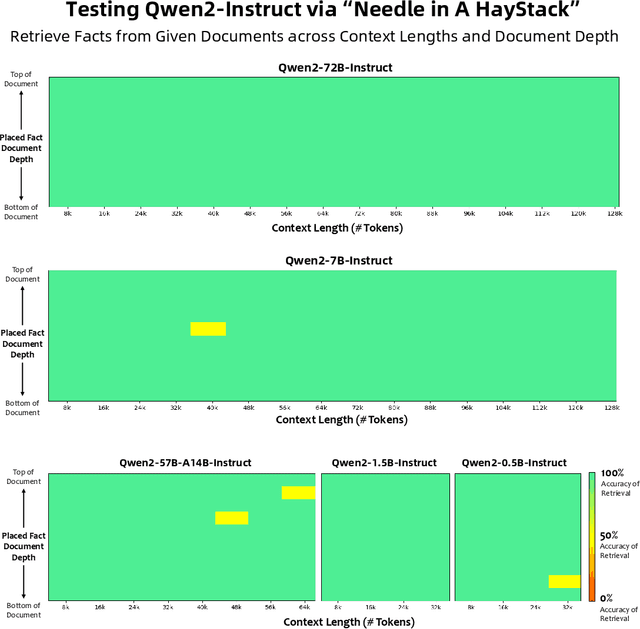
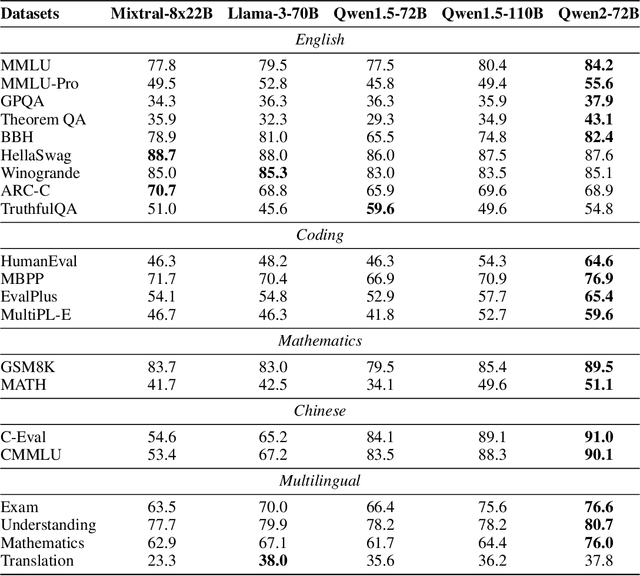
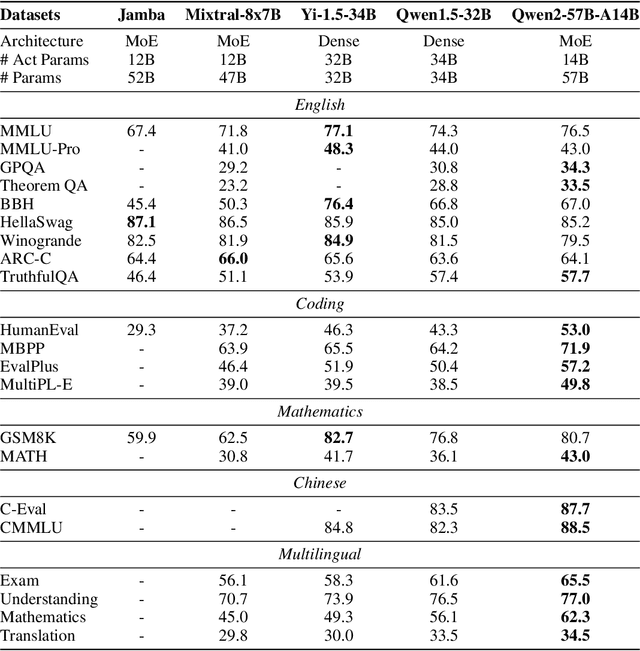
This report introduces the Qwen2 series, the latest addition to our large language models and large multimodal models. We release a comprehensive suite of foundational and instruction-tuned language models, encompassing a parameter range from 0.5 to 72 billion, featuring dense models and a Mixture-of-Experts model. Qwen2 surpasses most prior open-weight models, including its predecessor Qwen1.5, and exhibits competitive performance relative to proprietary models across diverse benchmarks on language understanding, generation, multilingual proficiency, coding, mathematics, and reasoning. The flagship model, Qwen2-72B, showcases remarkable performance: 84.2 on MMLU, 37.9 on GPQA, 64.6 on HumanEval, 89.5 on GSM8K, and 82.4 on BBH as a base language model. The instruction-tuned variant, Qwen2-72B-Instruct, attains 9.1 on MT-Bench, 48.1 on Arena-Hard, and 35.7 on LiveCodeBench. Moreover, Qwen2 demonstrates robust multilingual capabilities, proficient in approximately 30 languages, spanning English, Chinese, Spanish, French, German, Arabic, Russian, Korean, Japanese, Thai, Vietnamese, and more, underscoring its versatility and global reach. To foster community innovation and accessibility, we have made the Qwen2 model weights openly available on Hugging Face and ModelScope, and the supplementary materials including example code on GitHub. These platforms also include resources for quantization, fine-tuning, and deployment, facilitating a wide range of applications and research endeavors.
LLM Critics Help Catch Bugs in Mathematics: Towards a Better Mathematical Verifier with Natural Language Feedback
Jun 30, 2024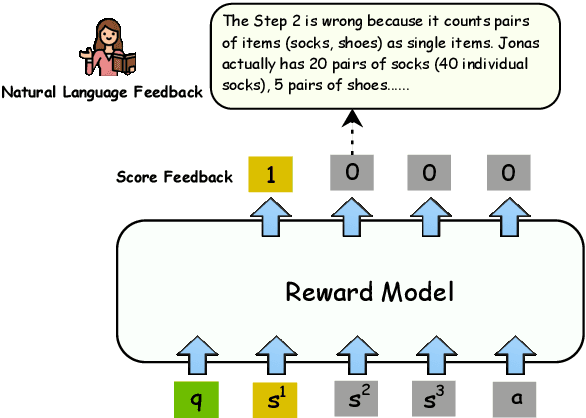
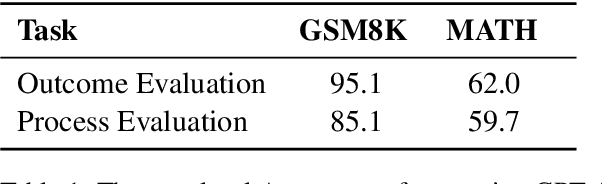
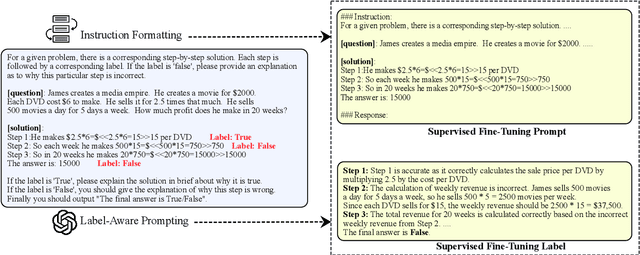

Mathematical verfier achieves success in mathematical reasoning tasks by validating the correctness of solutions. However, existing verifiers are trained with binary classification labels, which are not informative enough for the model to accurately assess the solutions. To mitigate the aforementioned insufficiency of binary labels, we introduce step-wise natural language feedbacks as rationale labels (i.e., the correctness of the current step and the explanations). In this paper, we propose \textbf{Math-Minos}, a natural language feedback enhanced verifier by constructing automatically-generated training data and a two-stage training paradigm for effective training and efficient inference. Our experiments reveal that a small set (30k) of natural language feedbacks can significantly boost the performance of the verifier by the accuracy of 1.6\% (86.6\% $\rightarrow$ 88.2\%) on GSM8K and 0.8\% (37.8\% $\rightarrow$ 38.6\%) on MATH. We have released our code and data for further exploration.
The Reason behind Good or Bad: Towards a Better Mathematical Verifier with Natural Language Feedback
Jun 20, 2024Mathematical verfier achieves success in mathematical reasoning tasks by validating the correctness of solutions. However, existing verifiers are trained with binary classification labels, which are not informative enough for the model to accurately assess the solutions. To mitigate the aforementioned insufficiency of binary labels, we introduce step-wise natural language feedbacks as rationale labels (i.e., the correctness of the current step and the explanations). In this paper, we propose \textbf{Math-Minos}, a natural language feedback enhanced verifier by constructing automatically-generated training data and a two-stage training paradigm for effective training and efficient inference. Our experiments reveal that a small set (30k) of natural language feedbacks can significantly boost the performance of the verifier by the accuracy of 1.6\% (86.6\% $\rightarrow$ 88.2\%) on GSM8K and 0.8\% (37.8\% $\rightarrow$ 38.6\%) on MATH. We will release the code, data and model for reproduction soon.